论文Transformers without Normalization的研究证明了Transformer可以在无归一化的情况下稳定训练,并提出了一种简单的替代方法 DyT。DyT 通过 动态缩放 tanh 取代 LN,成功复现了归一化层的作用,并在多个实验中达到了等同或更优的性能。该研究挑战了归一化层“不可或缺”的传统认知,并为高效神经网络设计提供了新的思路。
论文作者为Jiachen Zhu, Xinlei Chen, Kaiming He(何恺明), Yann LeCun, Zhuang Liu,来自来自FAIR(Meta), New York University, MIT和Princeton University。杨立昆(Yann LeGun)教授也是论文作者之一。
一、引言
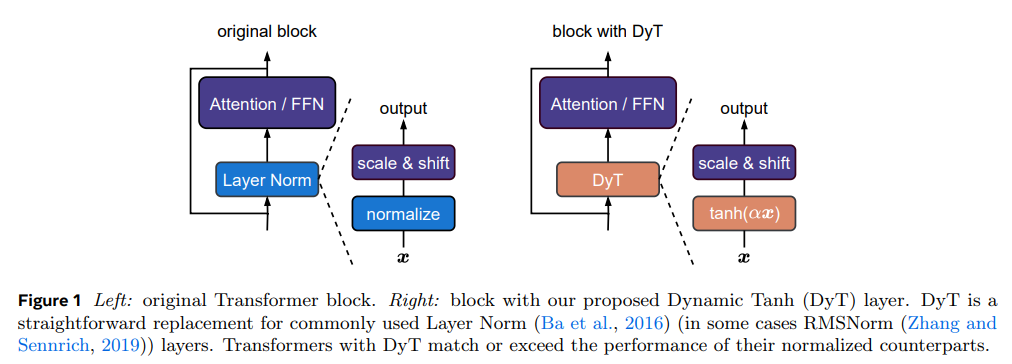
在现代深度学习网络中,归一化(Normalization)层已成为不可或缺的组件。自2015年批归一化(Batch Normalization, BN)提出以来,归一化层在优化、稳定训练和加速收敛等方面的优势已被广泛验证。特别是在Transformer架构中,层归一化(Layer Normalization, LN)成为默认选择,并被广泛用于计算机视觉、自然语言处理及其他任务。然而,本文提出了一种新的方法 动态双曲正切(Dynamic Tanh, DyT),它可以完全替代归一化层,使Transformer网络在无需归一化的情况下仍能稳定训练并取得等同甚至更优的性能。
DyT 的核心思想来源于对LN层的深入分析。研究发现,LN的输入-输出关系呈现S形曲线,与双曲正切(tanh)函数极为相似。因此,DyT通过 可学习的缩放因子 α 控制 tanh(x) 的尺度变化,从而在不计算输入统计特性的情况下,实现类似LN的归一化作用。实验表明,使用DyT的Transformer可以在各种任务中达到甚至超过传统LN的性能,并且无需调整超参数。
本研究挑战了归一化层在现代深度学习中“不可或缺”的传统认知,并为深入理解归一化层的作用提供了新见解。同时,DyT 在计算效率上也展现出优势,有望推动更高效的网络设计。
二、背景:归一化层的作用
归一化层的主要作用是调整输入分布,以改善训练稳定性和收敛速度。LN的标准计算方式如下:

LN的计算独立于批次尺寸(batch size),仅在 每个token 维度进行归一化,因此特别适用于Transformer架构。此外,另一种常见的归一化方法是 RMSNorm,其公式如下:
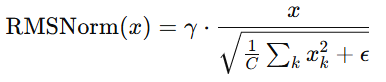
RMSNorm去除了均值归一化操作,在一些大规模语言模型(如LLaMA, T5, Qwen等)中被采用。
本研究首先分析了LN的实际作用,发现其主要功能包括:
- 线性缩放输入,并在极端值处施加非线性约束。
- 通过归一化不同通道的方差,限制数值的极端增长。
- 其输出形状与tanh函数极为相似,这为DyT的设计提供了灵感。
三、动态双曲正切(DyT)方法
DyT的定义如下:

DyT 直接替换 Transformer 中的 LN 层,并保持所有其他组件(如自注意力、前馈网络、激活函数等)不变。与LN相比,DyT 具有以下优点:
- 计算更简单:不需要计算均值和方差,减少了计算开销。
- 保持归一化效果:tanh(x) 本身具有输入值限制功能,可模拟LN对极端值的“挤压”作用。
- 无须调整超参数:大多数情况下,DyT可直接用于标准Transformer架构,而不需要重新搜索超参数。
四、实验验证
为了验证DyT的有效性,作者在多个领域的任务上进行了实验,包括计算机视觉、自然语言处理、语音处理和基因序列建模等。
- 计算机视觉任务(ImageNet-1K分类)
- 使用 Vision Transformer(ViT) 和 ConvNeXt 进行测试。
- 结果显示,DyT 在不调整超参数的情况下,与LN性能相当甚至略有提升:
- ViT-B: DyT 82.5% > LN 82.3%
- ViT-L: DyT 83.6% > LN 83.1%
- ConvNeXt-B 和 ConvNeXt-L 结果几乎相同。
- 自监督学习任务(MAE, DINO)
- 在 掩码自动编码器(MAE) 和 对比学习(DINO) 任务中,DyT 与 LN 的性能基本一致:
- MAE ViT-B: DyT 83.2% = LN 83.2%
- DINO ViT-B(16×16 patch): DyT 83.4% > LN 83.2%
- 在 掩码自动编码器(MAE) 和 对比学习(DINO) 任务中,DyT 与 LN 的性能基本一致:
- 扩散模型(DiT)
- 采用 Diffusion Transformer(DiT) 进行图像生成实验,使用 FID 评估:
- DiT-B: DyT 63.9 < LN 64.9(FID越低越好)
- DiT-L: DyT 45.7 ≈ LN 45.9
- DiT-XL: DyT 20.8 > LN 19.9(略低)
- 采用 Diffusion Transformer(DiT) 进行图像生成实验,使用 FID 评估:
- 大规模语言模型(LLaMA 训练)
- 在 LLaMA 7B、13B、34B、70B 预训练中,DyT 取得了与 RMSNorm 相似的性能。
- 训练损失曲线表明,DyT 与 RMSNorm 具有几乎相同的收敛速度。
- 语音处理(wav2vec 2.0)
- 在 LibriSpeech 数据集上预训练 wav2vec 2.0,DyT 的损失与 LN 基本相同:
- wav2vec 2.0 Base: DyT 1.95 = LN 1.95
- wav2vec 2.0 Large: DyT 1.91 < LN 1.92
- 在 LibriSpeech 数据集上预训练 wav2vec 2.0,DyT 的损失与 LN 基本相同:
- DNA序列建模
- 采用 HyenaDNA 和 Caduceus 进行基因组分类任务,DyT 与 LN 保持相同水平。
五、分析与消融实验
为了进一步理解 DyT 的工作原理,作者进行了详细的消融实验:
- 替换 tanh:如果将 tanh(x) 替换为 hardtanh 或 sigmoid,模型仍能训练,但效果下降。
- 去除 α:如果 DyT 不引入可学习参数 α,模型性能下降,证明 α 对性能至关重要。
- 计算效率对比:DyT 相比 LN 在推理和训练时间上分别减少 7.8% 和 8.2%。
- 与其他去归一化方法对比:DyT 在性能上优于 Fixup、SkipInit 和 σReparam 等方法。