论文RAG-Anything: All-in-One RAG Framework提出 RAG-Anything,一个“面向一切模态”的统一 RAG 框架,用于弥合现实世界多模态知识库(文本、图片/图表、表格、公式)与现有以纯文本为中心的 RAG 方案之间的错配。作者指出,把多模态内容简单“转文字”会丢失重要结构与语义(如图表布局、坐标轴/图例关联、表格的行列层级、公式的符号依赖),因而在科研、金融、医疗等高度依赖非文本证据的领域尤其失效。论文围绕三大挑战展开:统一表示、结构感知分解、跨模态检索对齐。核心思想是:把多模态内容视为“相互关联的知识实体”而非孤立数据类型,并通过“双图”(跨模态知识图 + 文本知识图)表示与“结构导航 + 语义匹配”的混合检索,实现对长文档、多模态证据的协同检索与推理。
论文作者为Zirui Guo, Xubin Ren, Lingrui Xu, Jiahao Zhang, Chao Huang,来自The University of Hong Kong。
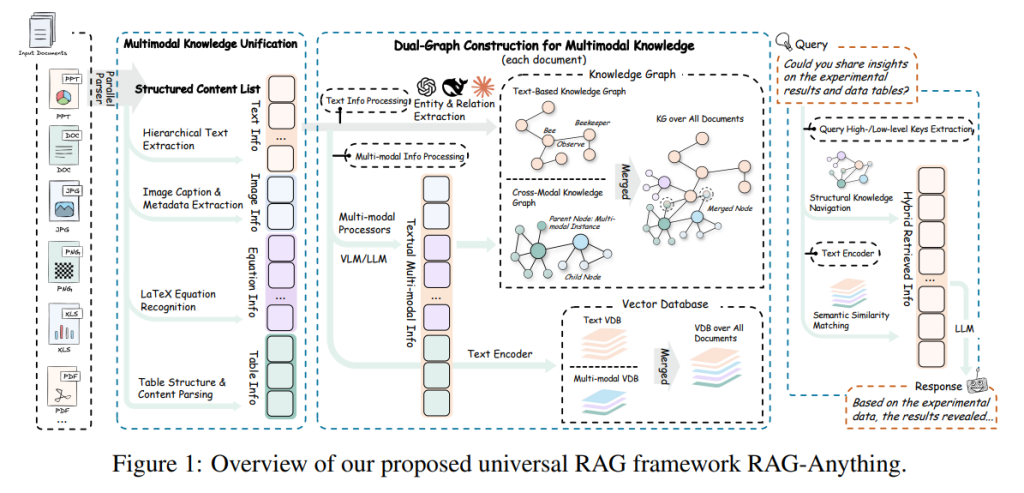
一、总体框架与组件
RAG-Anything 的流水线包含三大模块:①“多模态知识统一表示”把原始文档解析为保留上下文与层级关系的原子单元;②“跨模态混合检索”并行做结构化图导航与稠密语义相似检索,并融合多信号排序;③“从检索到综合”阶段把检索到的文本上下文与反指到的原始可视内容共同输入 VLM/LLM 以生成有据可依的答案。整套架构以“双图结构”为骨架,并配套向量表,实现结构与语义的双通道召回与互补。
二、关键技术一:多模态知识统一表示
作者将每个知识源分解为原子内容单元 cj=(tj,xj),其中 tj∈{text,image,table,equation,… },xj 是模态感知的内容表示;同时保留局部邻域 Cj 以刻画层级与顺序关系。不同模态由专用解析器抽取:文本按段落/条目切分;图像连同标题、图例、交叉引用抽取;表格解析出表头-单元格-单位的结构;公式转成可计算/可对齐的符号表示。这样既“格式归一”,又“上下文不丢”。
三、关键技术二:双图构建(Dual-Graph)
(1)跨模态知识图:把非文本原子单元(图、表、公式)作为锚点节点 vjmm,并利用 VLM 生成两类文本表示:面向检索的详细描述 djchunk 与图谱抽取友好的实体摘要 ejentity。从 djchunk 中抽取细粒度实体与关系 (Vj,Ej),并通过 belongs_to 边把它们挂接到对应的锚点节点,显式保留“子图-到-多模态实例”的依附关系。
(2)文本知识图:对文本块直接做实体/关系抽取,形成传统文本图。
双图分工明确:跨模态图保证“视觉/表格/公式”被正确锚定于其语境,文本图覆盖细粒度语义关系。
四、关键技术三:图融合与索引
先做实体对齐(以实体名为主键)把两张图合并为统一图 G=(V,E),同时为“实体、关系、原子块”统一生成稠密向量表示,形成嵌入表 T={emb(s)}。最终得到检索索引 I=(G,T):既可按图结构多跳导航,也可在共享向量空间内做跨模态相似召回。
五、关键技术四:跨模态混合检索
(1)模态感知的查询编码:从查询中解析模态线索(如“figure/表/公式”),并编码成与索引一致的文本嵌入 eq。
(2)结构知识导航:在 G 中做实体匹配与邻域扩张(受 hop 限制),优先发现显式的跨模态/多跳关系证据,得到候选集 Cstru(q)。
(3)语义相似匹配:用 eq 在嵌入表 TTT 上做向量近邻检索,跨实体、关系与原子块进行“隐性语义”召回,得 Cseman(q)。
(4)多信号融合排序:把结构重要性、语义相似度与“查询推断的模态偏好”联合成打分,输出最终候选 C⋆(q)。这种“双通道 + 融合”的架构,兼顾“显式结构证据”与“隐式语义相似”,尤其适合证据分散在多模态、跨页长文档的场景。
六、关键技术五:从检索到综合生成
为 VLM 构造两类条件:一是把 C⋆(q) 的文本化表示(实体摘要、关系描述、块文本)按模态/层级注释后串联为结构化上下文;二是对命中的多模态块做“反指”取回原图/原表/原公式内容 V⋆(q)。VLM 同时条件化于查询、文本上下文与视觉内容,实现“看得到真正的图表”,而不是仅凭图表的文本描述“想象”细节,从而提升可视语义与事实对齐。
七、实验设置
数据集:DocBench(229 份文档、1102 问题、平均 66 页、约 4.64 万 token,涵盖学术/金融/政府/法律/新闻)与 MMLongBench-Doc(135 份文档、1082 问题、7 类文档,强调长上下文)。基线包括 GPT-4o-mini、LightRAG、MMGraphRAG。解析器采用 MinerU;检索嵌入使用 text-embedding-3-large(3072 维),重排序用 bge-reranker-v2-m3;对图谱类方法设置实体+关系与 chunk 的 token 上限。评测由 GPT-4o-mini 做一致性判定。
八、主要结果与发现
在 DocBench 上,RAG-Anything 总体准确率 63.4%,优于 LightRAG(58.4%)与 MMGraphRAG(61.0%)及直接大模型处理(51.2%);在 MMLongBench 上,总体 42.8%,同样领先于对比方法(33.5%~38.9%)。更关键的是“长度韧性”:文档越长、跨页越多、模态越复杂,优势越显著(例如 DocBench 的 100+ 页段,领先幅度可达十余百分点)。这印证了“双图 + 混合检索”在长文档多模态证据聚合中的有效性。
九、消融实验
两组消融凸显了“结构优先”的价值:
(1)Chunk-only(无图谱,仅传统块检索)降至 60.0%,说明仅凭向量检索难以捕捉跨模态与布局关系;
(2)去除重排序(w/o Reranker)仅小幅回退至 62.4%,表明主要增益来自“图结构表示 + 跨模态融合”,重排序起精修作用。
十、案例剖析
(1)多子图可视比较:论文展示了 t-SNE 多面板图的问答,许多基线会混淆“风格空间”与“内容空间”面板;RAG-Anything 通过“面板-坐标轴-图例-标题”的结构图,精准定位到正确子图并得出正确比较结论。
(2)金融表格取值:问题要求在“工资与薪酬”行、“2020 年”列取值。方法把表格解析为“表头-单元格-单位”的有向关系网(row-of/column-of/header-applies-to/unit-of),避免近义行项与多年份列的歧义,正确落点到目标单元格。以上都体现了“结构化对齐”优于“文本展平”的本质差异。
十一、与相关工作的定位
相比 LightRAG/GraphRAG 等“文本优先”的图增强 RAG,本工作显式把图、表、公式升级为“一等公民”,并以跨模态图锚定其与语境的关系;相较仅把图像并入的 MMGraphRAG,本文进一步把表格/公式结构化为实体-关系,减少“把表当段落”的信息损失;相较把版面转为整页图像喂给大模型的方案(如基于版面图的检索),本文通过“反指原内容 + 双图结构”在可视语义与结构约束之间取得平衡。
十二、局限与未来方向
作者在失败案例中总结两类系统性难点:(1)文本偏置:当查询需要视觉证据时,检索仍偏向文本片段,导致粒度错配;(2)空间处理僵化:按“从上到下、从左到右”的默认扫描在非常规布局(合并单元格、异形表、跨列注解、流程/管线图)上易失效。未来需要更强的布局自适应解析、跨模态注意力对齐,以及在“结构噪声”场景下的鲁棒召回与可信裁决。
十三、实现落地与工程建议(面向多模态企业文档库)
1)解析与清洗:采用版面解析器(MinerU 同类)抽取文本/图/表/公式与交叉引用;保留页号、坐标、标题层级、表头层级、单位。
2)双图生成:对非文本块生成“检索描述 + 实体摘要”,抽取实体/关系并挂接到多模态锚点;对文本块直接做 NER/RE;做实体名消歧与合并。
3)索引与存储:以图数据库/图引擎存结构层(G),以向量库存嵌入表(T),两者以跨模态块 ID 对齐;冷热分层与分页级反指以控规模。
4)检索执行:查询解析模态偏好 → 图上实体定位与 K-hop 扩展(控制冗余)→ 向量近邻补召 → 多信号融合降重与重排。
5)答案综合:把文本证据编排成结构化提示,同时反指原图/原表/原公式喂入 VLM;保留证据可追溯(页/图/表/单元格坐标、实体路径)。
6)评测与质控:构建多模态问答集;对长文档分长度桶评测;加入“结构噪声”与“跨模态冲突”专项集;引入自动化准确性审评提示词与人工抽检闭环。
十四、可复用 Prompt 与开发资产
论文在附录给出了图像、表格、公式三类“结构化解析 Prompt”与“统一准确性评估 Prompt”,便于标准化知识抽取与一致性判分;工程上可直接把这些模板化到解析与评测流水线中,快速复现论文能力。
十五、典型场景的结合建议
针对常见的长篇技术规范、财务/运维报表、结构化点表与含大量图示的技术报告,可直接复用“双图 + 混合检索”范式:将 SCADA 点表、传感器标定表做行-列-单位-量纲实体化;把系统框图/流程图做“组件-连线-方向”图谱化;在事故/故障报告中通过“页-图-表-段落”跨模态路径定位根因证据;答案阶段反指到原图表与单元格,确保“可视-可核”。
十六、总结
RAG-Anything 用“多模态统一表示 + 双图结构 + 结构导航与语义匹配融合”的设计,有效突破了文本中心 RAG 在多模态长文档上的瓶颈:它既能以结构化方式对齐图/表/公式与语境,又能在共享嵌入空间里跨模态召回潜在证据;在 DocBench 与 MMLongBench-Doc 上取得全面领先,并在超长文档情形下显示出更强韧性。对真实企业文档库(科研、金融、工程、医疗等)而言,这是一条“以结构为纲、以语义为用、以证据反指为准”的务实路线。
RAG-Anything on GitHub: https://github.com/HKUDS/RAG-Anything