论文Mitigating Object Hallucination via Data Augmented Contrastive Tuning探讨了在多模态大型语言模型(MLLMs)中对象幻觉的挑战。对象幻觉是指当MLLMs生成的描述中包括并不存在于输入中的对象或其属性,这大大削弱了这些模型在视觉-语言任务中的可靠性。
论文作者为Pritam Sarkar, Sayna Ebrahimi, Ali Etemad, Ahmad Beirami, Sercan Ö. Arık, Tomas Pfister,来自Queen’s University,Vector Institute,Google Cloud AI Research和Google DeepMind。
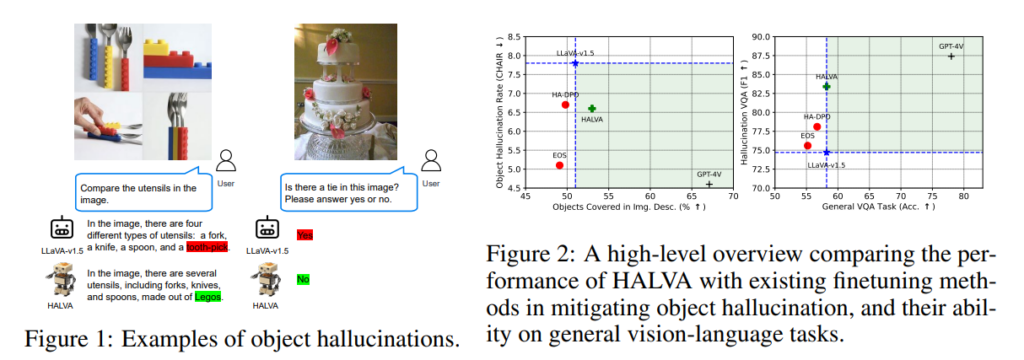
论文要点如下:
- 问题识别:
- 尽管MLLMs取得了显著进展,但在生成图像描述时,它们往往会产生幻觉。这种幻觉通常源于模型在训练过程中学到的虚假关联,例如某些对象的频繁共现(如“领带”和“婚礼蛋糕”)。
- 以往方法:
- 以往解决幻觉问题的方法主要集中在推理阶段、预训练阶段和微调阶段。然而,这些方法通常会增加推理时间、需要大量的再训练,或是会降低模型在一般视觉-语言任务上的性能。
- 提出的解决方案:
- 作者提出了一种对比微调方法,可应用于预训练的MLLM。核心思想是通过生成式数据增强创建“幻觉词元”,选择性地改变真实信息,然后微调模型,使其更倾向于选择真实的词元而非幻觉词元。
- 方法论:
- 生成式数据增强:通过改变正确响应中的对象相关属性,作者生成了幻觉响应,以创建对比对。
- 对比微调:通过在词元级别应用对比损失来微调模型,减少幻觉词元的生成概率,同时通过KL散度正则化保持模型在视觉-语言任务中的原始性能。
- 评估:
- 该方法在多个基准测试上进行了验证,包括CHAIR、MME-Hall和AMBER,结果显示,在保持或提高视觉-语言任务性能的同时,该方法显著降低了幻觉率。
- 与现有的HA-DPO和EOS方法相比,提出的方法(称为HALVA)在减轻幻觉方面表现更好,并且没有降低通用任务的性能。
- 结果:
- 结果表明,HALVA降低了句子级别的幻觉率,并提高了图像描述中对象的覆盖率。
- 在诸如存在、属性和关系识别等辨别性任务上,它也表现得更好。
- 消融研究:
- 论文包括了对方法中不同组件的影响的消融研究,例如对比损失的选择和KL散度约束的强度,研究发现,平衡的方法对于保持性能至关重要。
- 更广泛的影响和未来工作:
- 作者承认,尽管他们的方法有效地解决了对象幻觉问题,MLLMs中的其他类型的幻觉仍然是一个挑战。他们建议,未来的工作可以扩展他们的方法,以缓解不同类型的幻觉,并探索超越MLLMs的应用,例如减少语言模型中的偏见。