论文Language-Guided Image Tokenization for Generation提出的TexTok为一种有效且高效的图像分词新范式,其通过文本语义在分词阶段的引入,显著提升了图像重建质量和生成性能,并在不同token压缩率下均保持领先。在ImageNet条件生成与文本生成任务中均达成了SOTA水准,并大幅减少推理时间和计算成本。TexTok展现出将语言信息用于视觉任务早期编码阶段的潜力,未来可拓展至更多多模态生成与理解任务。
论文作者为Kaiwen Zha, Lijun Yu, Alireza Fathi, David A. Ross, Cordelia Schmid, Dina Katabi, Xiuye Gu,来自Google DeepMind和MIT CSAIL。
一、研究背景与动机
近年来图像生成领域取得了显著进展,其中一个关键因素是图像分词(tokenization)技术的发展,即将原始图像压缩为低维潜在表示。这一过程通常借助自动编码器(AutoEncoder)完成,使生成模型(如扩散模型和自回归模型)可以在潜在空间中生成图像,从而大幅降低计算开销。然而,现有图像分词方法在高压缩率下往往牺牲重建质量,导致高分辨率图像生成的表现受限。
本文提出的核心观点是:语言描述天然具备图像语义表达能力,若能在分词阶段引入图像对应的文字描述,或可提升语义学习效率,使得更多token空间用于精细视觉细节的编码,从而兼顾压缩率与重建质量。
二、方法概述:TexTok 框架
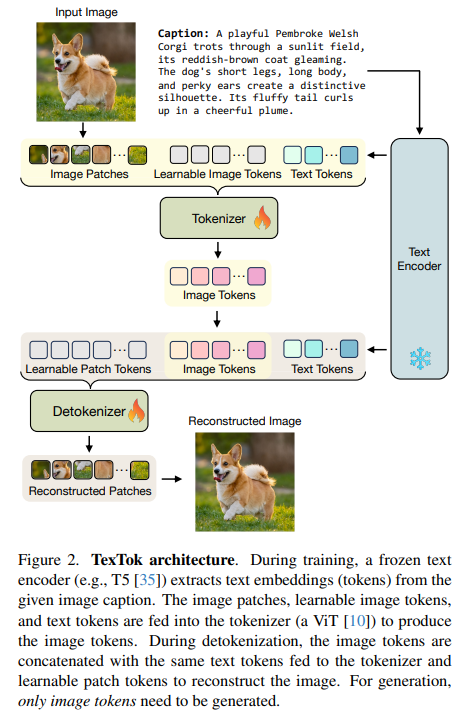
TexTok(Text-Conditioned Image Tokenization)是本文提出的基于文本条件引导的图像分词框架,其核心创新在于在编码器(Tokenizer)与解码器(Detokenizer)中均引入图像对应的文字描述嵌入,作为语义条件,指导图像的压缩与重建。
其结构包括:
- 文本编码器使用冻结的 T5 模型,将图像描述转化为嵌入向量。
- 分词器(Tokenizer)输入由三个部分组成:图像 patch token、可学习的图像 token 以及文本 token。输出仅保留图像 token。
- 解码器输入同样包括图像 token、文本 token 以及可学习的 patch token,最终恢复出原图。
- 模型训练采用 L2 重建损失、感知损失(LPIPS)、GAN 损失及 LeCAM 正则项。
TexTok 与传统方法的不同在于,它将图像的高层语义交由文本 token 表达,使模型更多关注细节纹理,尤其在 token 数量受限的场景下优势更明显。
三、图像生成流程
在图像生成阶段,TexTok 仅需生成图像 token,而文本 token 可由预设caption直接提供。生成模型选用 Diffusion Transformer(DiT),在 class-conditional 任务中使用类别标签作为条件,在 text-to-image 任务中使用文本描述作为条件。
在推理阶段,TexTok 具有以下特点:
- 类别生成任务中,用离线生成的类描述caption与生成的图像token共同送入解码器。
- 文本生成任务中,caption同样送入生成器与解码器,生成过程无额外注释代价。
四、实验设置与实现细节
TexTok 的训练主要基于 ImageNet-256 与 ImageNet-512 数据集,并使用 Gemini VLM 自动为图像生成文字描述(caption)。文本长度设置为最多75词,通过T5-XL或T5-XXL编码为128维token序列。
网络结构采用ViT-Base,具有12层Transformer结构、768维隐藏层、12头注意力,token维度设为8。图像token数设置为32/64/128/256,分别用于评估压缩率与生成质量的权衡。
生成器为原始DiT结构,文本生成任务中添加多头cross-attention用于接收文本嵌入,称为DiT-T2I。
五、实验结果与分析
- 图像重建与生成质量:TexTok 在各个token数量设定下均优于未使用文本条件的Baseline(w/o text),在ImageNet-256上重建FID平均提升29.2%,生成FID提升16.3%;在ImageNet-512上分别提升48.1%与34.3%。
- 压缩率:TexTok 在仅使用Baseline一半乃至四分之一token数的情况下,仍能达到相同甚至更佳的重建质量(如图3所示),验证了其在压缩效率上的显著优势。
- 系统性能对比:TexTok + DiT 在ImageNet-256上达成1.46的FID,在ImageNet-512上达成1.62的FID,均为当前最佳水平。同时,在使用32个token时,TexTok实现高达93.5×的生成速度提升。
- 文本到图像生成(Text-to-Image):TexTok 在32/64/128-token条件下分别提升FID与CLIP分数,且图像与描述匹配度显著优于Baseline,尤其在复杂视觉细节(如鸟喙、汽车轮胎)还原上效果突出。
六、消融实验与关键因素分析
- 文本信息丰富度:越详细的caption(25词 vs 75词)带来更优的重建质量。
- 文本编码器规模:T5从Small到XXL逐级提升,模型表现也随之增强。
- 条件注入方式:将文本token直接拼接输入ViT(in-context conditioning)优于cross-attention方案。
- 注入位置:在Tokenizer与Detokenizer均注入文本token效果最佳。
- 模型大小:TexTok-Base在性能与效率间取得最佳平衡。
七、与相关工作的比较
与其他方法如LQAE、SPAE等直接将图像映射至语言模型token或在对齐image-text表示上强制约束不同,TexTok并不试图将图像token与语言空间强行对齐,而是采用软条件方式引导视觉压缩过程,因而在保持生成质量的同时保留了视觉信息结构,避免语义损失。
TexTok: https://kaiwenzha.github.io/textok/