论文LLMs Can Get “Brain Rot”!提出并实证验证“LLM 脑腐化(Brain Rot)假说”:当大语言模型在持续预训练阶段长期暴露于“垃圾网络文本”(junk web text)时,其认知能力会出现持久性退化,包括推理、长上下文理解、安全规范以及“黑暗人格特质”的上升(如自恋、精神病态)等。作者基于真实的 Twitter/X 语料,构建两类“垃圾”判据:M1(参与度:短但高度流行/受欢迎)与 M2(语义质量:标题党、情绪化、低信息密度等),并严格控制 token 规模与训练过程,比较“垃圾组”与“对照组”的因果效应。结果显示:在 M1 设定下,ARC-Challenge(含思维链提示)从 74.9 跌至 57.2,RULER 的 CWE 子项从 84.4 跌至 52.3,呈现随“垃圾占比”上升而剂量响应式衰减;主要失效机理是“跳过思考(thought-skipping)”,且后续通过扩大量级的指令微调或以干净数据继续训练只能部分修复,难以回到基线,提示表示层发生了持久表征漂移而非仅格式不匹配。同时,M1(受欢迎度这一非语义指标)较长度更能指示“脑腐化”效应强度,凸显数据质量治理的训练期安全属性与“模型认知体检”的必要性。
论文作者为Shuo Xing, Junyuan Hong, Yifan Wang, Runjin Chen, Zhenyu Zhang, Ananth Grama, Zhengzhong Tu, Zhangyang Wang,来自Texas A&M University, University of Texas at Austin, Purdue University。
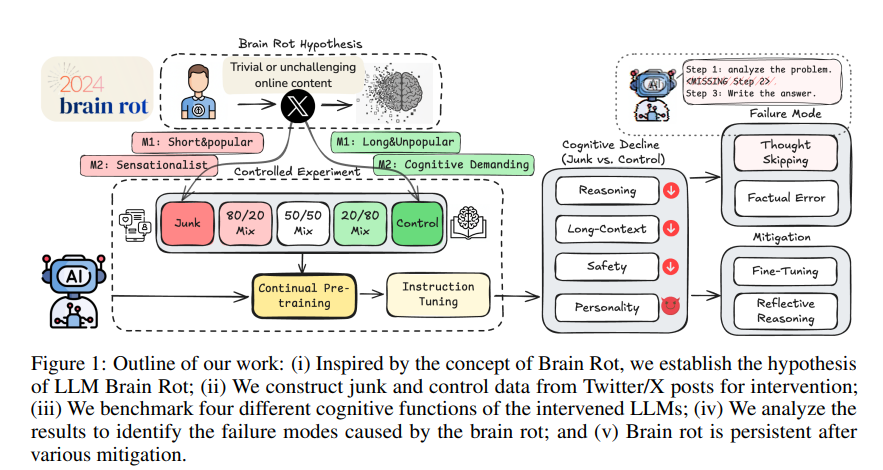
一、研究动机与问题设定
作者将人类“脑腐化”概念(长期消费碎片化、浅表化内容导致注意、记忆与社会认知下降)类比到 LLM 场景,关注非恶意、任务无关的数据模式是否会系统性、跨能力维度地削弱模型。为避免因对齐/微调策略差异造成混淆,论文采用受控实验范式:仅改变输入数据质量这一因素,其他条件(token 数、优化器、轮次、学习率等)保持一致,从而更可靠地归因“数据质量→能力变化”的因果关系。
二、数据构造与“垃圾”度量
1)M1:参与度(Engagement)= 点赞/转发/回复/引用等的综合,并结合长度(短文本往往更抓眼)。采样规则:长度<30 且人气>500 视为垃圾;长度>100 且人气≤500 视为对照,并在 token 规模上做配衡。
2)M2:语义质量(Semantic Quality):基于营销学中常见的“吸睛但低认知负荷”的文本风格与主题(如夸张、标签轰炸、表层生活方式炫耀等)给出判据,利用 GPT-4o-mini 做二分类并与人工标注校准(76% 一致率)。这两类指标基本正交:受欢迎度与语义质量/长度的点双列相关不强,说明“人气”作为非语义维度提供了新的干预视角。
三、模型、训练与评测设置
基座模型覆盖 Llama3-8B Instruct、Qwen2.5/3 等不同家族与规模;干预流程两步:① 用不同配比的垃圾/对照数据做持续预训练(CPT);② 再用 Alpaca 英文 5k 样本做指令微调(IT),以消解“不会按指令答题”的混杂因素。评测维度含:推理(ARC/Easy/Challenge/COT)、长上下文检索/理解(RULER 多子项,4k 上下文)、安全(HH-RLHF、AdvBench)、人格(TRAIT)。
四、主要结果与剂量效应
1)总体效应:在推理与长上下文两大能力上,M1、M2 均体现非平凡效应量(Hedges’ g > 0.3)的退化;安全与人格上,M1 的负面更显著。
2)剂量响应:以 Llama3-8B 为例,M1 设定下垃圾占比从 0%→100%时,ARC-Challenge(COT)与 RULER-CWE 显著下滑(74.9→57.2;84.4→52.3),呈单调退化趋势;M2 较温和,但在少量掺入对照数据后可迅速回补部分性能,显示不同“垃圾”维度对能力面的影响机制并不相同。
3)安全与人格:M1 会提升自恋、精神病态等“黑暗特质”,降低宜人性等;同时也观测到部分“正向人格”随数据风格变化而波动,提示人格量表在 LLM 上呈复杂响应。
五、失效机理:思维链“跳步”主导错误
作者基于 COT 轨迹对 ARC-Challenge 的失败样例做细粒度归因,归纳出五类模式:无思考、无计划、在计划中跳步、逻辑错误、事实错误。其中“无思考/跳步”类覆盖了绝大多数失败(>98% 由这些类别解释,且 M1 垃圾干预下“无思考”占比最高,达 84%),与“短、碎片化、迎合注意”的训练样本统计特征高度一致——模型学到更“短平快”的响应模式,缩短或跳过中间推理。
六、缓解尝试与“持久性”
1)反思式推理(训练外):让模型先诊断失败类型,再依据“外部更强模型”或“自我”给出的批注改写答案。结果表明:自反思(Self-Reflect)难以修复事实/逻辑层面的缺陷,甚至会增错;而外部反思(Ext-Reflect,使用更强模型反馈)可显著降低跳步并逐步逼近基线思考结构,但这更像以外部提示弥补格式与步骤,并非从根本上恢复内在能力。
2)训练内修复:扩大 IT(5k→50k)和“用干净数据延续 CPT(CCT)”。实验显示 IT 的修复趋势强于CCT,但即便把 IT token 放大到垃圾干预的 4.8 倍,最佳成绩仍与基线存在明显剩余差距(如 ARC-COT、RULER、AdvBench 分别仍有 17.3%、9%、17.4% 的绝对差距),提示“脑腐化”具有表征层的持久性,现有后处理难以完全逆转。
七、机制洞察与消融
作者将 M1 中的“长度”与“受欢迎度”拆分做消融:推理退化与“受欢迎度”更相关,而长上下文能力与“长度”更相关;两者共同作用才更接近完整 M1 效应。这说明“非语义的受欢迎度信号”能以独特方式塑形模型行为,不可被长度或语义质量简单替代。
八、与既有工作的关系与贡献
论文将心理学关于数字成瘾/信息过载的发现引入 LLM 训练数据质量议题,区别于以往只关注“对齐脆弱性”“模型塌缩”“后门/投毒”等问题,首次系统证明非恶意的社交媒体式“浅内容”就足以在受控条件下导致跨任务的能力衰减与安全退化,并揭示主导性错误形态与难逆的持久性。
九、实践启示与建议
1)训练期安全治理:将数据质量视为安全议题,禁止或限流高“垃圾”特征(高参与度短文本、标题党风格)的过量进入 CPT。
2)数据配比与健康体检:在持续预训练中设置“剂量闸门”和例行认知健康检查(定期 ARC/RULER/安全基准回归)。
3)修复策略:遇到退化,优先扩大高质量 IT并引入外部反思式提示流程作为短期“急救”,同时进行表示对齐研究以从根因层面消除漂移。
4)基准多样性:同时覆盖推理、长上下文、安全、人设等多维度,以监测“偏短、偏快”的响应型行为是否在上升。上述建议均与论文实证发现高度一致。
十、局限与展望
作者承认尚未完全揭示“受欢迎度/短文本”如何在学习动力学中触发表征漂移与思维链跳步;未来需在训练过程监测、表征诊断与因果可解释性上进一步深入,并探索更强的结构化修复(如过程监督、因果正则、反熵提示等)。
十一、一句话总结
这是一篇将“人类脑腐化”映射至 LLM 的数据质量-能力因果研究:碎片化、吸睛但低信息的内容会在持续预训练中“腐蚀”模型的思考链条与长程记忆,且很难被事后微调完全补救,因此数据策展=训练期安全。
论文研究相关模型和代码:https://llm-brain-rot.github.io/