Robot Learning: A Tutorial是一篇面向研究者与实践者的“机器人学习”教程型综述,主张在不抛弃传统动力学/控制学成果的前提下,以数据驱动的学习范式(RL/BC 与通用语言条件化策略)重塑从“感知到动作”的端到端控制栈。作者不仅体系化梳理了传统与学习范式的分野、互补路径与现实掣肘,还给出了大量可复现的 lerobot 代码示例与数据格式规范(LeRobotDataset),以降低新手入门与工程落地门槛。全篇结构依次为:引言与数据集格式;经典机器人学与其局限;强化学习在机器人上的机遇与难题;模仿学习与生成模型(VAE/扩散/Flow Matching、ACT、Diffusion Policy);推理优化;通用型机器人策略(VLA、π0、SmolVLA);结论与展望。
文章作者为Francesco Capuano, Caroline Pascal, Adil Zouitine, Thomas Wolf, Michel Aractingi,来自University of Oxford, Hugging Face。
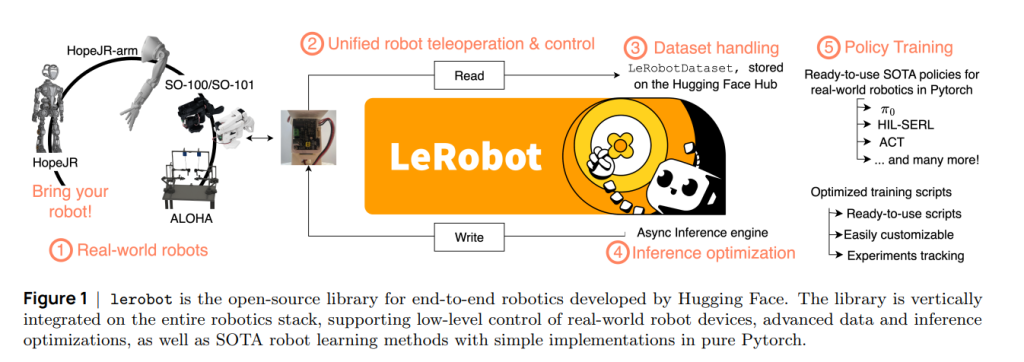
一、LeRobotDataset:为机器人学习而生的数据基建
作者首先强调:随着多模态机器人数据的大量涌现,标准化、高吞吐、可扩展的数据组织是推动“从单任务到通才”跃迁的关键。LeRobotDataset 的设计要点包括:
1)三大支柱式存储:表格数据(关节/动作等低维高频,内存映射+datasets库)、视觉数据(同一 episode 帧拼接为 MP4,按相机视角分组+分目录减轻文件系统压力)、元数据(JSON 记录特征模式、帧率、归一化统计与 episode 边界,充当“关系层”来重建跨文件的索引)。
2)把真实存储与用户 API 解耦:底层集中拼接、上层以窗口化(delta_timestamps)直接喂给 PyTorch DataLoader,既支持离线批处理也支持 Hub 流式读取,提升打乱度与吞吐(80–100 it/s 级别),贴合 BC/RL 训练对时序栈帧和动作块的需求。
3)面向多形态与可扩展:已覆盖 SO-100/ALOHA-2/仿真/人形/自动驾驶等多机体数据,促进可复现实验与社区共享。
二、经典机器人学的能力与边界
作者以“显式模型 vs 隐式模型”切入:显式模型依赖精准的几何/动力学/接触建模与规划—跟踪—控制流水线;隐式模型将运动视为统计映射,由数据学习感知到动作的直接函数。教程通过“平面 2 自由度操作臂”的玩具例子,说明正/逆运动学(FK/IK)、微分逆运动学(diff-IK)和反馈(P/PI/PID、LQR、MPC)在静态可控环境中的有效性,以及在障碍、接触、非线性/不确定扰动下的脆弱性和调参成本。更关键的是,传统流水线在模块拼装、误差级联、传感多模态融合与跨任务迁移上成本高、复用性差;同时,摩擦/顺应/可变形体等现象的简化建模限制了真实世界性能。
三、为何转向学习式机器人(以 RL 为例)
学习范式的优势在于:
1)单体化的“感知→动作”策略,减少脆弱接口;
2)天然兼容高维多模态输入(视觉/触觉/音频/本体感受等);
3)不依赖显式动力学模型,可直接用交互数据迭代;
4)随数据规模提升而可扩展。教程用到标准的 MDP 框架与回报最大化目标,概述了价值函数/策略优化关系与主流算法(TRPO/PPO/SAC 等),并以到达—放置(操作)与侧向移动(步态)示例化“序贯决策”的本质。
四、现实机器人 RL 的两大痛点:安全与样本效率
1)安全与人力:早期策略探索往往“瞎”,可能触发自撞/超速/超力矩等风险,同时需要频繁人工复位,训练节奏慢。
2)样本效率:即便是强算法(如 SAC)也常需大量交互步数,真实机器人上代价高昂。
常见缓解是在仿真中训练+域随机化(DR)转实:随机摩擦/质心/光照等参数提高鲁棒性。然而 DR 需要手工选参与分布设计,熵太小难转移、太大则过正则;近期方法尝试自动调 DR 分布,如 AutoDR(随性能拓宽 U(a,b) 的边界)与 DORAEMON(学得的 Beta 分布、外层最大熵+内层性能约束),另有“以真促仿”的在线/离线轨迹配准。尽管如此,很多接触/可变形任务仿真仍难高保真、算力代价大;更底层的限制是复杂任务通常难以给出密集奖励,稀疏回报显著放慢学习。作者因而提倡:尽量锚定已采集演示/经验,采用样本高效的离线/离策略方法,并结合“人类在环”干预,已在 1–2 小时内把真实世界复杂抓取操作做到接近满分成功率。
五、模仿学习与生成建模:从单任务到“动作分布”的学习
作者将行为克隆(BC)置于“生成模型”视角系统化阐述:
1)VAE:以潜变量重建轨迹,适配噪声/多峰动作分布;
2)扩散模型(Diffusion Models):在动作空间做去噪生成,已成为视觉—运动策略学习的前沿方案;
3)Flow Matching:在连续时间上拟合数据到先验的概率流,推理更快、稳定性更好。这些生成法的共同点是“学轨迹族”(而非单一点控制),对多模态/不确定性更友好。文中随后给出两条落地主线:
A)ACT(Action Chunking with Transformers):以短时动作块为建模单元,Transformer 预测未来多步控制,天然匹配“窗口化”数据接口,工程上训练—推理简洁;
B)Diffusion Policy:通过动作扩散实现鲁棒分布拟合,已在多种操作任务上给出强性能与泛化示范。教程配有完整的训练/推理代码片段,强调与 LeRobotDataset 的即插即用。
六、推理优化:让策略“既快又稳”
为缩短控制回路延迟并提升实时性,教程提出把“动作规划”与“动作执行”解耦,辅以异步推理栈与批处理/流水线化,实现硬件侧的时序保障与策略侧的吞吐优化,并提供异步推理示例以便在资源受限的真实机器人上落地。
七、通用机器人策略(Generalist Policies):从单任务到“多任务×多机体×语言条件化”
作者将通用策略归入“广义的 BC 家族”,因为它们本质上仍以大规模演示为监督信号,只是引入语言/图像等多模态条件与跨任务多机体数据:
1)VLA(Vision-Language-Action):以 VLM(如 PaLM-E/指令微调架构)为感知—语义层,输出动作序列,支持语言指令驱动的任务泛化;
2)π0:强调从大规模、跨场景的演示中学习统一的多任务策略,配套开源推理与调用示例;
3)SmolVLA:以更“轻量”的参数规模追求更高的部署性与更低延迟,同样提供使用样例。教程在“模型与数据预备”中给出数据配方与训练接口,力图把“通才机器人”从论文走向可复现工程。
八、方法论脉络与实践建议
1)范式互补:并非“学习取代一切”。在规则清晰、动力学可准确建模的场景,经典方法的可解释与稳定优势仍不可替代;在接触/非线性/多模态与跨任务泛化诉求强的场景,学习范式更具伸缩性。
2)数据优先与标准化:以 LeRobotDataset 为枢纽,统一特征模式/统计/视频—表格—元数据的索引重建,才能把“大数据+大模型”的红利来到机器人的“栈底”。
3)现实训练三件套:安全护栏(限幅/看门狗/急停)、人类在环(干预/演示注入)、高效算法(离策略+重放+演示混入/奖励学习)。
4)从单任务 BC 到通用策略:先用 ACT/Diffusion Policy 在特定机体/场景打通工程链,再循序迈向语言条件化的 VLA/π0/SmolVLA。
5)推理侧工程:异步、解耦与流水线化是把“论文级性能”搬到“控制级实时”的必要条件。
九、总结与展望
教程的核心价值在于“桥接”:它一方面尊重 60 余年经典机器人学的成果与边界条件,另一方面以数据/模型/工程三位一体的方式,把 RL/BC/生成建模与通用策略的最新进展落在可复现的 lerobot 代码与数据标准上。面向未来,作者看好三条线:
(1)更安全、更高效的真实世界 RL(少样本、人类在环、奖励学习);
(2)以扩散/Flow Matching 为核心的鲁棒 BC 与快速推理;
(3)跨任务/跨机体、语言条件化的通用策略与小型化部署路线并进。对产业界而言,这套方法论等于提供了一条从“小型、可 3D 打印的 SO-100 教学/原型平台”到“通才机器人”的工程上手路径。
LeRobot on GitHub: https://github.com/huggingface/lerobot