论文NaVILA: LEGGED ROBOT VISION-LANGUAGE-ACTION MODEL FOR NAVIGATION提出了一个用于腿式机器人导航的新型视觉语言行动模型框架NaVILA。NaVILA框架通过创新性的分层设计,成功实现了腿式机器人在复杂场景中的视觉-语言导航,展示了卓越的鲁棒性和通用性。
论文作者为An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, Xiaolong Wang,来自UC San Diego, USC, NVIDIA。
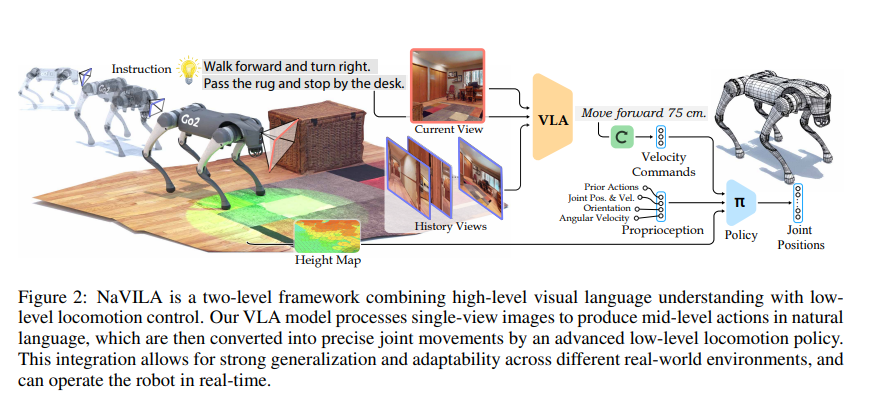
1. 背景与研究动机
- 视觉语言导航的核心问题:
- 视觉-语言导航(Vision-Language Navigation, VLN)要求机器人在没有地图的环境中,根据自然语言指令完成导航任务。这种任务涉及视觉感知、语言理解、高层推理和低层运动控制,是机器人自主能力的关键组成部分。
- 现有的VLN研究多集中于离散场景和轮式机器人,忽视了连续环境中的挑战,如复杂地形、动态障碍物、环境光线变化等。
- 腿式机器人的需求与挑战:
- 腿式机器人相比轮式机器人在狭窄空间、不规则地形中具有更大的灵活性。然而,腿式机器人需要处理精确的低层运动控制,例如腿关节的姿态调整,这使得从语言到动作的映射更加复杂。
- 传统的端到端方法试图直接生成低级控制命令,但这对视觉-语言模型提出了过高的要求,往往导致模型难以泛化。
- 研究目标:
- 提出一种分层方法,利用视觉-语言模型生成中层动作指令,再通过强化学习策略执行这些指令,以实现更加鲁棒和灵活的导航。
2. NaVILA 框架设计
NaVILA 是一个两级框架,包含高层的视觉语言行动(Vision-Language-Action, VLA)模型和低层的视觉行走策略。
2.1 高层VLA模型
- 核心功能:
- 将输入的单视图图像和自然语言指令转换为中层动作描述,如“向前移动75厘米”或“向右转30度”。
- 提供导航过程中所需的高层次规划。
- 模型架构:
- 视觉编码器:处理输入图像,将其转换为视觉令牌。
- 多层感知(MLP)映射器:将视觉令牌投射到语言域,与文本令牌结合。
- 大语言模型(LLM):负责从输入中生成导航动作。
- 改进策略:
- 结合当前视图和历史视图(多帧图像),通过统一提示(prompt)设计区分这两者的角色。
- 通过自然语言输出中层指令,使得模型能够保留语言推理的强大能力,同时避免直接生成低级动作的复杂性。
- 导航提示设计:
- 构建基于文本和图像的任务描述,例如“当前观察:走廊,历史观察:实验室”,生成指令“向右转并进入下一个房间”。
2.2 低层视觉行走策略
- 核心功能:
- 接收来自VLA模型的中层动作指令,如移动距离或旋转角度。
- 利用机器人传感器(LIDAR和关节状态)实现对环境的实时感知和精准控制。
- 主要技术:
- LIDAR高度图:通过激光雷达生成2.5D环境高度图,有效检测透明或复杂表面。
- 强化学习策略:采用单阶段强化学习(PPO算法),直接训练机器人在真实场景中的行走策略。
- 动作空间和观测空间:
- 动作空间:12个腿关节的目标位置。
- 观测空间:关节位置、速度、上一动作、LIDAR高度图等。
- 训练方法:
- 在模拟环境(Isaac Sim)中使用高度图进行端到端训练,确保策略能够在现实环境中部署。
- 引入随机化技术,弥合模拟和现实之间的差距(sim-to-real gap)。
3. 数据集与训练
3.1 数据设计
- 数据来源:
- 真实导航视频:从YouTube获取2000段导航视频,使用视觉-语言模型生成自然语言指令。
- 仿真数据:在模拟环境中生成路径点和动作序列,用于训练中层指令。
- 辅助数据集:利用扩展数据集(如ScanQA)增强模型对场景理解和问答任务的能力。
- 通用视觉-问答数据集:确保模型在广泛任务上的泛化能力。
- 数据处理:
- 对导航视频进行轨迹采样,通过熵优化确保样本多样性。
- 使用Mast3R技术估计相机姿态,并生成与轨迹匹配的自然语言指令。
3.2 训练流程
- 视觉语言模型训练:
- 使用视觉-文本数据预训练VILA模型,然后进行导航任务微调。
- 微调时解冻所有模块,包括视觉编码器、映射器和LLM。
- 行走策略训练:
- 在模拟环境中直接训练低层策略,机器人通过与环境交互学习复杂场景中的最佳行为策略。
4. 实验与评估
4.1 在经典VLN基准上的表现
- 数据集:R2R 和 RxR。
- 性能指标:
- 成功率(Success Rate, SR):NaVILA在单视图RGB输入条件下提高了17%。
- 导航误差(NE):相比现有方法显著降低。
4.2 在模拟环境中的表现
- 数据集:VLN-CE-Isaac(新提出的基准)。
- 成果:
- 视觉策略成功率比盲策略提高14%-21%。
- 展示了对复杂地形和动态障碍物的优异适应能力。
4.3 在真实场景中的表现
- 场景:
- 工作空间、家庭环境、室外场景。
- 任务:
- 简单指令:如“走到椅子前停止”。
- 复杂指令:如“走出房间,右转,进入前方房间,到达桌子前停止”。
- 结果:
- 简单任务成功率达100%。
- 复杂任务中,与GPT-4o相比提升显著,尤其是在多房间导航任务中表现优异。
5. 创新与优势
- 分层设计:
- 通过中层指令解耦高层推理与低层控制,显著提高模块化能力。
- 泛化能力:
- 通过多源数据训练,模型具备跨场景的鲁棒性和适应性。
- 现实部署:
- 无需额外训练即可适应不同机器人平台(如Unitree Go2和H1)。
6. 潜在应用与未来工作
- 潜在应用:
- 智能家居机器人:在室内场景中完成复杂任务。
- 搜救机器人:在动态环境中导航到指定地点。
- 工业巡检机器人:适应复杂工业环境的自动化任务。
- 未来工作方向:
- 数据增强:引入更多具有噪声和动态障碍物的真实场景数据。
- 跨平台优化:提升模型在不同硬件平台上的适应性。
- 多模态扩展:结合语音、触觉等模态,进一步提升导航任务的完成度。
NaVILA: https://navila-bot.github.io/