论文《Robot Utility Models: General Policies for Zero-Shot Deployment in New Environments》详细介绍了如何设计和实现机器人效用模型(Robot Utility Models, RUM),使得机器人在新环境中无需微调即可执行任务,即所谓的零样本部署(Zero-Shot Deployment)。RUM成功实现了机器人在不同环境中的任务执行。该框架不仅减少了数据收集和微调的成本,还展示了机器人在实际应用中的高效性和可靠性,为未来更多类型任务的零样本部署提供了宝贵的借鉴和参考。
论文作者为Haritheja Etukuru, Norihito Naka, Zijin Hu, Seungjae Lee, Julian Mehu, Aaron Edsinger, Chris Paxton, Soumith Chintala, Lerrel Pinto, Nur Muhammad Mahi Shafiullah,来自New York University, Hello Robot Inc.和Meta。
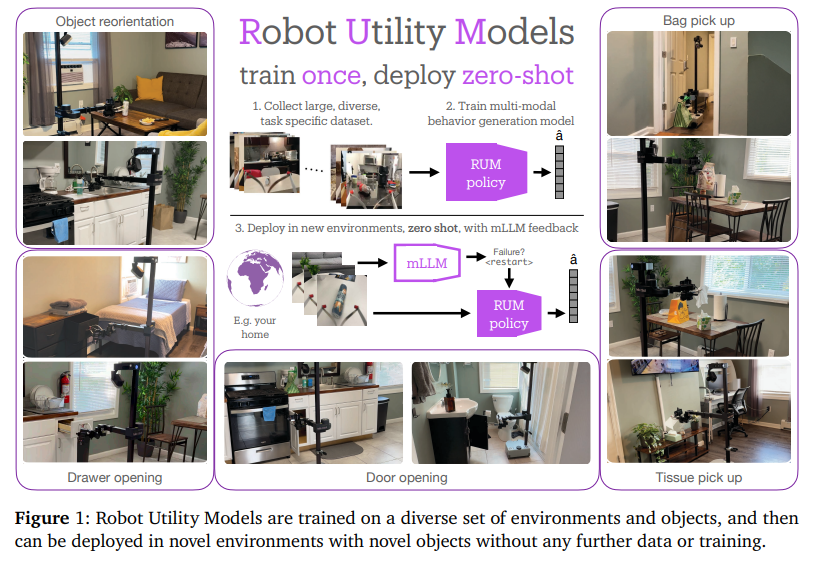
以下是论文概要内容:
1. 引言
机器人技术在操控和导航任务上取得了长足的进展,尤其是通过深度学习和模仿学习,机器人能够在相对稳定的环境中表现出较强的任务完成能力。然而,传统方法要求机器人在每个新环境中进行微调,这极大限制了其灵活性和扩展性。而视觉和语言模型已经能够实现零样本问题解决,即无需专门为新环境进行调整。为了让机器人也具备类似的能力,论文提出了一种新的框架——机器人效用模型(RUM),旨在训练并部署能够直接在新环境中泛化的机器人策略,完全不需要额外的数据收集和微调。
2. 核心框架:机器人效用模型(RUM)
论文提出的RUM框架是一个系统化的学习框架,能够训练出具备泛化能力的机器人政策。这种政策不仅能够在训练中使用的环境中表现优异,还能在完全未见过的新环境中执行任务。其核心流程如下:
- 数据收集:
- 利用名为Stick-v2的便携式数据收集工具,快速在不同环境中收集大量、多样的任务示范数据。Stick-v2由一台iPhone Pro组成,能够精确采集RGB视频、深度数据以及位置信息,且不需要额外的相机校准。
- 论文中的任务包括:开门、开抽屉、拾取纸巾、拾取纸袋、重新定向掉落的物体等五项核心任务。为每个任务收集了大约1000次的示范操作,确保涵盖多种不同的环境和对象。
- 多模态模仿学习(Multi-modal Imitation Learning):
- 数据收集完成后,通过多模态模仿学习算法来训练机器人策略。最有效的算法包括VQ-BeT和Diffusion Policy,这些算法能够有效学习任务的多模态行为,即从视觉信息中推断出机器人的动作。
- 每个模型都基于一个ResNet34的视觉编码器,并使用transformer结构作为策略预测器,以确保模型能够处理复杂的任务执行流程。
- 零样本部署与多模态大语言模型(mLLM)反馈:
- 在训练完成后,RUM可以直接部署到实际机器人上,如Hello Robot的Stretch机器人,无需在新环境中进行任何微调。部署过程中,外部的多模态大语言模型(mLLM)作为辅助反馈机制,能够检测到任务执行中的错误,并指示机器人进行重试。
3. 数据收集工具:Stick-v2
论文设计了一种低成本、高便携的工具——Stick-v2,用于在不同环境中快速收集高质量的数据。其设计特点包括:
- 便携性:整个工具使用iPhone Pro和少量廉价材料构成,总成本仅为25美元,方便携带和部署。
- 高精度数据采集:借助iPhone的ARKit API,Stick-v2可以以高频率采集RGB视频、深度数据和位置信息,同时自动同步和时间戳化这些数据,保证在不同环境中的数据一致性。
- 易于部署:由于不需要额外的相机校准,Stick-v2可以直接在任何环境中使用,减少了每次环境设置的时间成本。作者在多种环境(例如商店、家庭)中快速收集数据,从而丰富了数据集的多样性。
4. 数据集与任务定义
论文定义了五个任务,每个任务的示范数据来自大约40个不同的环境,每个环境有25次左右的操作示范。这五个任务包括:
- 开门任务:机器人需要开门,任务中仅包含有把手的门(排除了带有圆形门把手的门)。
- 开抽屉任务:机器人需要打开带把手的抽屉(不包含带圆形把手的抽屉)。
- 重新定向物体任务:机器人需要将躺在平面上的物体(如瓶子)重新摆正。
- 拾取纸巾任务:机器人需要从纸巾盒中拿取纸巾。
- 拾取纸袋任务:机器人需要从平面上拾取一个纸袋。
每个任务都在40个环境中采集了大约1000次的示范数据,这些环境包括普通家庭场景以及商店等公共环境,以确保数据的多样性。
5. 模型训练与部署
在训练过程中,论文使用了多种模型架构,包括VQ-BeT和Diffusion Policy等。这些模型能够处理多模态输入,预测机器人在6D空间中的相对动作。训练的关键在于找到合适的数据子采样频率,并使用过去几帧的历史数据来提高预测的准确性。整个训练过程耗时24到48小时,使用两块Nvidia A100 GPU完成。
部署方面,RUM框架能够适应多种机器人平台,不仅支持Hello Robot的Stretch机器人,还支持其他具有6自由度控制的机器人手臂,如xArm。此外,论文还测试了不同的相机设置,展示了RUM在硬件变化下的高泛化能力。
6. 结果与分析
为了验证RUM的有效性,论文在多个真实环境中进行了2950次机器人任务执行实验,结果表明:
- 高成功率:RUM在25个新环境中实现了平均90%的成功率,尤其在开门、开抽屉和拾取任务中表现尤为突出,成功率达到84%-94%。
- 多模态政策的优势:相比于传统的单模态政策,RUM使用的多模态政策在未见环境中的成功率为74.4%,而通过mLLM的反馈和重试机制,成功率进一步提高了15.6%,达到了90%左右。
- 数据多样性的重要性:实验表明,数据的多样性比数据量的增加更为重要,模型在不同环境中的泛化能力极大依赖于训练时所使用的多样化数据集。
- 自我检验与重试机制:论文引入了多模态大语言模型(mLLM)作为一种错误检测机制,当模型在执行任务时出现错误时,mLLM会自动检测到并指示机器人重试任务,极大提高了任务完成的成功率。
7. 启示与未来工作
这篇论文展示了通用机器人效用模型在多个任务和不同环境中的强大泛化能力,并为机器人在新环境中的零样本部署提供了一种切实可行的方法。尽管RUM目前在某些任务(例如开带有圆形把手的门)上存在硬件限制,未来的工作可以通过改进硬件设计或进一步增加任务多样性来解决这些问题。
RUM: https://robotutilitymodels.com/