论文Going Deeper with Convolutions发表于2014年,论文的研究验证了通过稠密组件模拟稀疏连接结构是一种实用有效的深度网络构建方式,尤其适用于计算预算受限场景。GoogLeNet在ILSVRC 2014分类与检测任务中均取得领先成绩,论文提出的Inception架构在提升准确率的同时兼顾了效率。此外,辅助分类器、尺度融合、降维策略等设计对网络稳定性与训练可行性均具有显著贡献。的详细中文分析,按照原文结构进行梳理,章节间不设分割线。
论文作者为Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich,来自Google, University of North Carolina和University of Michigan。
一、引言
近年来,图像识别和目标检测技术因深度学习特别是卷积神经网络(CNN)的快速发展而取得显著进步。尽管硬件性能增强、数据集增大等因素有所助益,但研究表明,真正的突破更多源于新颖的算法设计和网络架构的改进。本文提出的Inception架构,正是出于高效利用计算资源的目标而设计,能够在保持计算预算的同时增加网络深度与宽度。其在ILSVRC 2014中提交的GoogLeNet模型仅使用了Krizhevsky等人模型约1/12的参数数量,却取得了更优的准确率。本文关注如何在限制资源下达到更高识别质量,并强调可在移动和嵌入式设备中部署的重要性。
二、相关工作
从LeNet-5以来,CNN通常由卷积层、归一化层、池化层和全连接层组成。近年趋势是增深网络结构并扩大每层通道数量,同时用Dropout缓解过拟合。尽管最大池化层会丢失部分空间信息,但许多工作仍在定位、目标检测和姿态估计任务中取得成功。Lin等人的Network-in-Network通过在卷积层中引入1×1卷积提升表示能力,本文借鉴了该思路,将1×1卷积用于特征压缩与激活转换。R-CNN引入候选区域与CNN分类器结合的新范式,也在本文检测方案中被采用。
三、动机与高层设计考量
提升深度网络性能的直接方法是增加深度和宽度,但这会引发两个问题:
1)参数数量增加导致过拟合风险上升,尤其在训练样本有限时;
2)计算成本指数增加。若网络结构未能高效利用容量,可能造成大量计算浪费。
理想方案是转向稀疏连接结构,从而减少冗余连接。Arora等人的理论支持基于神经激活相关性进行层间稀疏连接构建,这种“Hebbian式聚类”可层层构造最优网络拓扑。然而,在当前硬件架构下,稀疏矩阵计算效率远低于优化良好的稠密矩阵运算,因此作者试图用稠密组件来逼近稀疏结构,提出了Inception架构。
四、架构细节
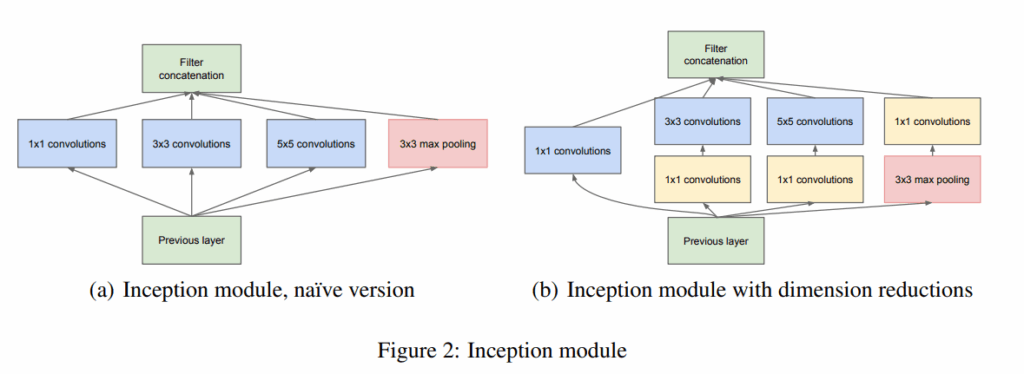
Inception模块核心思想是用不同大小卷积核(1×1、3×3、5×5)并行提取多尺度特征,并将结果拼接。再引入最大池化路径,丰富输出特征表达。
但直接使用3×3、5×5卷积计算量巨大,为降低成本,作者使用1×1卷积先对输入通道进行降维,然后再施加大卷积核处理,从而实现“先压缩再计算”的策略。最终构建的Inception模块如下图所示,在保持输出维度的同时显著降低计算量。多个Inception模块堆叠构成整网架构,中间使用步长为2的池化层降低特征图分辨率。低层使用传统卷积结构是出于当前硬件资源限制,并非架构设计本意。
五、GoogLeNet
GoogLeNet是本文提交ILSVRC14的Inception网络实例,共22个含参数的层(若含池化层则为27层),总体结构含约100个构建模块。其设计目标是优化推理效率与内存占用,适用于资源受限设备。
关键设计包括:
1)替代全连接层为全局平均池化,提高泛化能力并减少参数量;
2)在中间层添加辅助分类器,增强梯度流并提供正则化;
3)使用1×1卷积完成降维,同时加入ReLU激活函数形成非线性变换。
辅助分类器结构为:5×5平均池化(stride=3)→1×1卷积(128 filters)→FC层(1024 units)→Dropout(70%)→FC + Softmax。仅用于训练阶段,在推理时被移除。
六、训练方法
使用DistBelief分布式系统以异步SGD+动量(0.9)进行训练,学习率每8轮下降4%,采用Polyak均值进行推理时参数融合。数据增强策略包括:
- 多尺度裁剪
- 光照变换(借鉴Andrew Howard的方法)
- 插值方法多样性(随机选择双线性、面积、最近邻、双三次)
实验中发现最终效果受这些数据增强组合影响较大,但无法完全分离每项的独立贡献。
七、ILSVRC 2014分类挑战设置与结果
分类任务要求将图像归为ImageNet中的1000个类别之一,评价指标为Top-1和Top-5错误率。作者未使用外部数据训练,提交7个GoogLeNet模型(1个为宽版),以投票集成方式提升精度。
测试阶段采用144种裁剪组合:4种缩放尺寸×3种图像区域(左中右或上下中)×6种裁剪(4角+中心+整图缩放)×2(镜像),最终Top-5错误率降至6.67%,为当年最佳结果,且未依赖外部数据。
如表3所示,裁剪数和模型数量越多,效果提升越明显(但收益递减)。
八、ILSVRC 2014目标检测挑战设置与结果
检测任务要求定位图像中最多200类目标,预测正确需与GT类别一致且IoU>50%。
作者检测方案基于R-CNN框架,主要创新包括:
1)使用Inception取代AlexNet作为候选区域分类器;
2)候选区域生成结合Selective Search与MultiBox,提高召回率并降低冗余;
3)未使用bounding box回归,仅通过改进候选框筛选与模型集成实现mAP 43.9%,为2014第一名。
相比2013年冠军22.6%的mAP,提升接近一倍。与同时期其他模型(如DeepID-Net)相比,GoogLeNet在无需外部上下文建模与边框回归的情况下仍取得领先,验证了Inception架构的强大表达能力。