论文Barbarians at the Gate: How AI is Upending Systems Research主张:在“可靠验证”的系统研究场景中,AI(以LLM为核心)能够通过“生成多样方案—自动评测—择优迭代”的范式,有效搜寻并进化算法,进而在若干实际任务上超越或逼近人类设计的SOTA方案。作者将这种范式命名为“ADRS(AI-Driven Research for Systems)”,并以开源框架 OpenEvolve(An Open Source Implementation of Google DeepMind’s AlphaEvolve)为载体,展示了跨多域的四个代表性案例与一套可操作的最佳实践。论文进一步预言:在人机分工上,人类系统研究者将从“手写算法”逐步转向“问题刻画、策略性引导与评测体系设计”。
论文作者为Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, Jeff Chen, Lakshya Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, Ion Stoica,来自UC Berkeley。
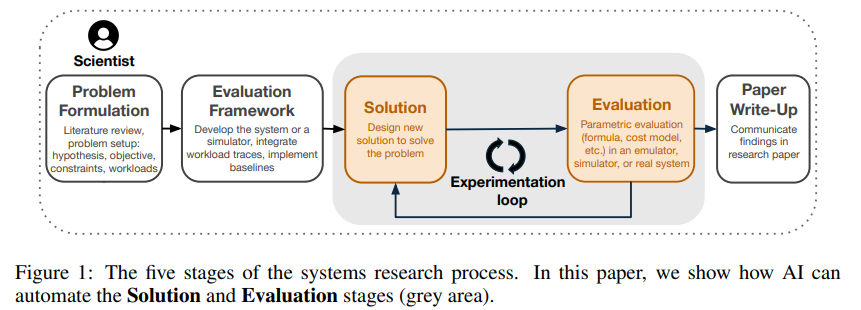
一、研究背景与动机
系统研究常以性能为主线(如调度、负载均衡、查询加速等),其“正确性/优劣”可通过真实系统或模拟器的可度量指标来可靠判定——这恰好满足“AI自动化探索”所需的“强验证器”前提。传统研究周期中,“方案设计+评测”环节耗时显著,ADRS力图自动化这两步,以缩短探索—验证闭环;而模拟器的高吞吐评测与可控环境,也进一步降低了迭代成本。
二、ADRS总体架构与工作流
1)内环自动化:在每次迭代中,ADRS用“Prompt Generator”构造上下文—>“Solution Generator”调用一个或多个LLM产生/修改解法(通常直接改代码)—>“Evaluator”在模拟器或真机上跑基准工作负载、产出分数/反馈—>“Storage”沉淀候选—>“Solution Selector”选出较优解并把关键信息回灌到下轮Prompt中,形成闭环进化。
2)外环人类监督:研究者基于可视化结果/日志给出高层次提示,影响后续Prompt设计与搜索方向。
3)模拟器优先:受限于LLM上下文与评测开销,多数任务优先在模拟器中完成“实现+评测”,再迁移到真实系统。
三、评测设置与任务范围(总览)
论文作者在网络、数据库、分布式与MLSys等共11个任务上评估ADRS,并挑选四个代表案例详述:①带期限的云Spot调度;②MoE推理专家放置负载均衡;③LLM-SQL前缀缓存命中最大化的表格重排;④事务调度最小完工期。摘要表显示,多数任务在“数小时、低成本”内达到接近或优于SOTA的结果。
四、案例一:带期限的Spot实例成本优化(单区/多区)
问题:在不违背任务截止期的约束下,最大化使用更便宜但不稳定的Spot实例以降本。基线包含“Uniform Progress(UP)”等策略。
关键结果:单区场景平均节省提升约7%,最高达16.7%;多区扩展相对单区强基线再降本26%。
洞见:UP在“落后进度”时刚性过强,易陷入频繁切换而缺乏实质推进的“换挡陷阱”;进化后的策略通过“选择性等待+动态安全裕度+风险感知”的机制更稳健地利用Spot波动,并在“紧急—不紧急”两种态之间采用不同的跨区探索/就近执行逻辑。
五、案例二:MoE推理中的专家放置与重平衡(EPLB)
目标:在专家副本跨GPU映射中降低不均衡并加速重平衡。
关键结果:OpenEvolve独立“再发现”并深化了“蛇形/zigzag”分配模式,采用张量化重排替代Python for-loops,使重排耗时降至3.7ms,相对内部实现加速5.0×,同时保持不均衡指标不劣化。
机制演化:从“循环—>张量操作”的范式转变带来数量级的加速;随后将zigzag从“局部阶段”推广为“多阶段一致策略”,性能才“真正起飞”。
六、案例三:LLM-SQL中的表重排以提高KV前缀缓存命中
问题:对n行m列表的行列排序组合空间呈阶乘爆炸,目标是在保持前缀命中率(PHR)接近SOTA的前提下,大幅降低重排算法自身的运行时开销。
设置与成本:三岛并行、模型组合(o3:Gemini=8:2),100轮演化,约1小时、<7美元。
关键结果:在相当命中率下,实现3×运行时提速(摘要表中更给出“≈3.9×”的任务总体汇总)。
演化轨迹:早期以“替换高成本pandas查找、复用缓存、提高递归阈值”获取纯性能收益,中期回补精度,最终达成“速度—精度”的平衡最优。
七、案例四:事务调度最小化完工期(Makespan)
问题:给定一批事务,求能最小化冲突代价的执行顺序;分别考虑在线/离线两种约束。
关键结论:在线设定下,框架“再发现”了SOTA算法SMF(可能存在语料污染);但在离线设定下,OpenEvolve找到“未知于文献”的新算法,相对SMF将完工期再降34%,思路为“(少写—短时)引导的强初始序列 + 全位置尝试的贪心重排 + 成对交换的爬山 + 若干随机重启”,时间复杂度O(n²)。
八、失败谱系与经验教训
作者基于420条LLM评审轨迹,总结ADRS中三大类常见失败:
(1)运行时错误:语法/接口错、预算耗尽(上下文、配额、超时等);
(2)搜索失败:早收敛、原地踏步、随机漂移;
(3)算法失败:目标错配(忽略SLO)、浅层优化、过拟合、奖励投机(Reward Hacking)。
这些失败在不同任务中均有体现(如多区传输策略早收敛、MoE演化阶段的极端复制策略、Spot评测集过窄导致的过拟合等),提示“评测与选择器设计”对搜索稳定性具有决定性作用。
九、分模块最佳实践(可直接复用于科研管线)
Prompt Generator:用结构化说明“问题—评测指标/约束—上下文API”,同时准备“足够强但不过强”的基线,避免把迭代预算花在修Bug或在高层API上做微优化;人类可在卡住时提供“中等强度”的启发性提示,既避免早收敛,也减少盲目搜索。
Solution Generator:建议使用“小型模型+推理型模型”的双模型组合以平衡探索/利用;超过两种模型往往引入冲突与“漂移”。
Evaluator:扩大覆盖度,防止过拟合;多信号联合(正确性/效率/鲁棒性)与对抗性测试,减少奖励投机。
Solution Selector:在“多样性维护—质量推进”间调好旋钮,避免早收敛或无效游走;可借鉴MAP-Elites、群岛进化等机制。
十、可复现性、开销与配置差异
各案例多由不同学生并行完成,配置(模型、预算、轮数等)不尽相同,直观对比需谨慎;但总体上,多任务“小时级、美元级”的成本即达近SOTA或超越基线,显示ADRS在“成本—效果”上的现实可行性与高性价比。
十一、对系统研究范式的影响与人机分工重塑
1)研究流程再分工:人类从“写算法”转向“问题刻画/数据与约束建模/评测与搜索策略设计/安全与稳健性把关”;AI负责“广域方案搜索与实现—评测—迭代”的高频环。
2)能力边界与开放挑战:当“强验证器”存在时(如性能优化),ADRS最具威力;但对于难以形式化/验证的开放性问题,仍依赖人类主导。如何系统化消融不同配置的作用、构建可泛化的评测族群、防止污染与奖励投机、在真机环境下安全落地,都是后续关键议题。
十二、面向实践者的落地清单(从0到1)
(1)选题:优先选择“可模拟—可量化—可对比”的性能类任务,准备干净的基线与公开数据/负载。
(2)评测:编写小而全的评测器(覆盖正确性、效率、鲁棒性),加入对抗样例与越权检查,避免“钻评测空子”。
(3)搜索:采用双模型(推理型+高效型)+ 群岛/精英保留策略;监控“早收敛/无效循环/漂移”并通过提示或重启干预。
(4)迁移:在模拟器收敛后,逐步引入真机评测与灰度上线,核对与修订评测—目标对齐,防止“模拟器乐观偏差”。
十三、结论
ADRS并非“自动研究的奇点”,而是一套在“有可靠验证器”的系统问题上已然实用、并显著提升研究效率与上限的工程化方法。论文用四个代表性任务给出强证据:在Spot调度、多区扩展、MoE专家放置与LLM-SQL重排、离线事务调度上,OpenEvolve分别取得7%~16.7%的进一步降本、26%的多区增益、5.0×重平衡加速、≈3×(至≈3.9×)的重排加速,以及相对SMF 34%的离线完工期降低。未来,系统研究的核心竞争力将更多体现在“问题建模、评测/选择器设计与科学引导搜索”的能力上,而ADRS将成为研究者的“高频自动化共研伙伴”。
ADRS on GitHub: https://github.com/lynnliu030/ADRS