论文《A Review of Large Language Models and Autonomous Agents in Chemistry》,探讨了大型语言模型(LLMs)及其在化学领域中的应用,以及基于LLMs的自主代理在化学研究中的应用和潜力。论文作者为Mayk Caldas、Christopher Collison和Andrew White。研究过程中,Mayk创建了一个LLM代理来帮助寻找论文并将它们发布到一个GitHub仓库中。
《A Review of Large Language Models and Autonomous Agents in Chemistry》
By Mayk Caldas、Christopher Collison and Andrew White
论文内容介绍如下:
摘要
大型语言模型(LLMs)在多个化学领域中展示出强大的应用潜力,能够准确预测性质、设计新分子、优化合成路径,加速药物和材料的发现。结合化学特定工具如合成规划器和数据库,这些模型可以形成所谓的“代理”,从而推动化学研究的跨学科应用。
介绍与背景
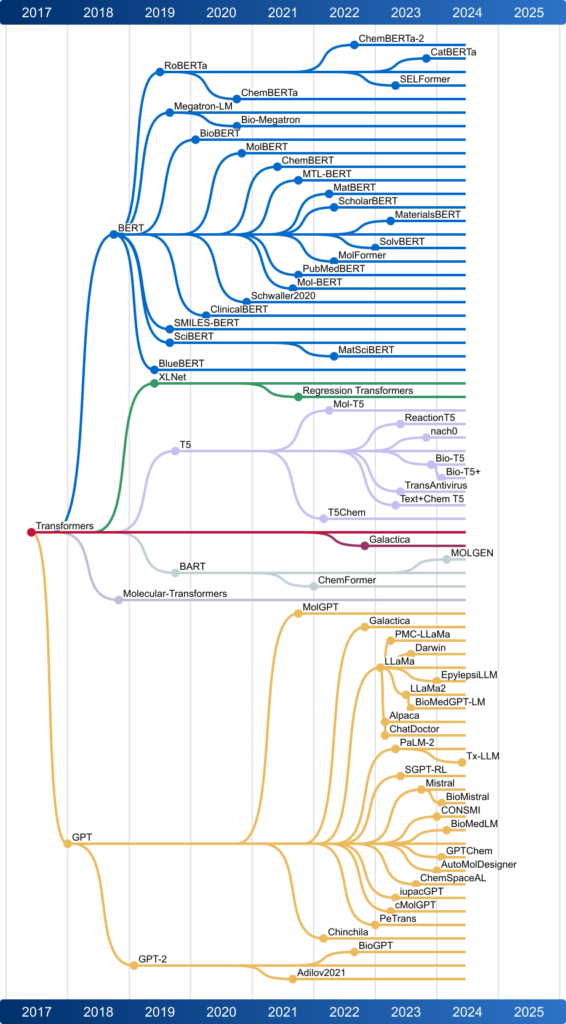
论文首先回顾了AI和ML在化学中的发展历程。从1950年代到1970年代的量子化学和分子建模,到1980年代的专家系统(如DENDRAL),再到1990年代引入神经网络用于药物设计。随着高通量筛选数据的爆炸式增长,支持向量机和随机森林等ML算法在分类和回归任务中变得流行。2010年代,深度学习在化学和材料科学中取得了重大进展,RNN、CNN和GNN等模型在分子性质预测、药物发现和合成预测中表现出色。
大型语言模型
- Transformer模型:
- 介绍了Transformer模型,包括编码器-解码器架构,以及其在化学中的应用。
- 编码器-解码器模型通常用于翻译任务,而编码器模型用于性质预测或分类任务,解码器模型用于生成新分子。
- 模型训练:
- LLM的训练分为预训练和微调两个阶段。
- 预训练阶段使用无监督学习,微调阶段使用有监督学习,最后可能还需要通过强化学习进行模型校准,以确保模型输出符合人类偏好。
- 模型类型:
- 编码器模型(如BERT)主要用于理解输入序列,解码器模型(如GPT)主要用于生成输出序列,编码器-解码器模型(如BART)结合了两者的优点。
化学中的LLMs
- 分子表示、数据集与基准:
- 分子可以通过多种方式表示,如分子图、3D点云和定量特征描述。本文关注基于字符串的表示(如SMILES、SELFIES和InChI)。
- 训练数据集和评估数据集的质量至关重要,缺乏高质量的数据是阻碍化学领域LLM发展的主要瓶颈。
- 性质预测与编码器模型:
- 编码器模型可以有效地进行化学空间的探索和性质预测。文章列举了多个实例,展示了编码器模型在反应分类和性质预测中的应用和优越性。
- 基于性质的逆设计与解码器模型:
- 解码器模型在生成新分子方面具有重要价值,能够根据预设的条件生成具有特定化学性质的新分子。
- 文章详细介绍了多个基于解码器的LLM在分子生成和性质预测中的应用。
基于LLM的自主代理
- 模块设计:
- 自主代理包括记忆模块、规划与推理模块、分析模块、感知模块和工具模块。
- 这些模块结合起来,可以用于文献综述、化学创新、实验规划和自动化化学信息学任务。
- 应用实例:
- 文章列举了多个实例,展示了LLM-based自主代理在化学研究中的应用,如用于文献综述的代理、用于化学创新的代理、用于实验规划的代理等。
挑战与机遇
- 数据质量与多模态数据:
- 当前数据集存在质量问题,未来需要更多高质量、多模态的数据。
- 多模态模型结合结构数据与其他类型的分子信息,可能是未来的发展方向。
- 模型解释性与可靠性:
- 提高模型的解释性和可靠性是一个重要挑战,需要更多的研究来增强模型对化学领域的适应性。
结论
本文综述了LLMs及其在化学中的应用,指出了当前存在的挑战和未来的研究方向。通过结合LLMs与自主代理,化学研究有望取得更大的进展,加速科学发现和创新。论文全面回顾了LLMs在化学中的应用,并提出了未来的发展方向和研究重点,为化学与AI的结合提供了宝贵的参考。
Large language models and autonomous agents in chemistry: a review on GitHub: https://github.com/ur-whitelab/LLMs-in-science/