Federico Barbero等近期发表论文:Transformers need glasses👓: Information over-squashing in language tasks,研究了仅解码器结构的Transformer(decoder-only Transformers)在语言任务中的信息传播方式。通过理论信号传播分析,发现了一种表示崩溃(representational collapse)现象:不同的输入序列在Transformer最终层的最后一个token表示中可能会变得非常接近。这种现象在现代LLMs中使用的低精度浮点格式下尤为明显,导致模型在处理这些序列时出现错误。此外,论文还指出仅解码器Transformer语言模型可能会对输入中的特定token失去敏感性,这与图神经网络中的过度压缩现象类似。论文通过实验证明了这些问题的存在,并提出了简单的解决方案。
论文作者:
- Federico Barbero, University of Oxford
- Andrea Banino, Steven Kapturowski, Dharshan Kumaran, João G.M. Araújo, Alex Vitvitskyi, Razvan Pascanu, Petar Veličković, Google DeepMind
Transformers need glasses👓: Information over-squashing in language tasks
1. 引言
近年来,NLP领域通过引入基于Transformer的架构取得了革命性进展。大型语言模型(LLMs)在多种任务中表现出色,包括对话代理、多模态输入理解和代码补全等。然而,Transformer模型在某些简单任务中仍然表现出明显的不足,例如计数和复制操作。本文旨在通过理论分析和实验证实这些不足,并提供改善这些问题的方案。
2. 背景
本文主要研究仅解码器结构的Transformer,这类结构是大多数当前LLMs的基础架构。使用这些模型进行信号传播分析,特别是分析最终层最后一个token的表示,这是用于下一个token预测的表示。通过分析,本文发现了一种表示崩溃现象:某些不同的输入序列在Transformer最终层的最后一个token表示中可能会变得非常接近,导致模型无法区分这些序列。此外,低精度浮点格式加剧了这一现象。
3. 动机示例
本文通过一系列实验展示了现代仅解码器Transformer架构在简单的复制和计数任务中的惊人失败案例。这些实验揭示了模型在处理这些基本任务时的不足,进一步证明了本文理论分析的必要性。
3.1 复制任务
在复制任务中,模型需要根据提示复制特定位置的token。实验结果表明,当提示模型复制序列末尾的元素时,模型表现不佳,而复制序列开头的元素时表现较好。这表明信息在序列中的传播存在问题,特别是在处理长序列时。
3.2 计数任务
在计数任务中,模型需要计算特定token在序列中出现的次数。实验结果显示,随着序列长度的增加,模型的表现急剧下降,错误率显著上升。这表明模型在处理需要精确计数的任务时存在严重问题。
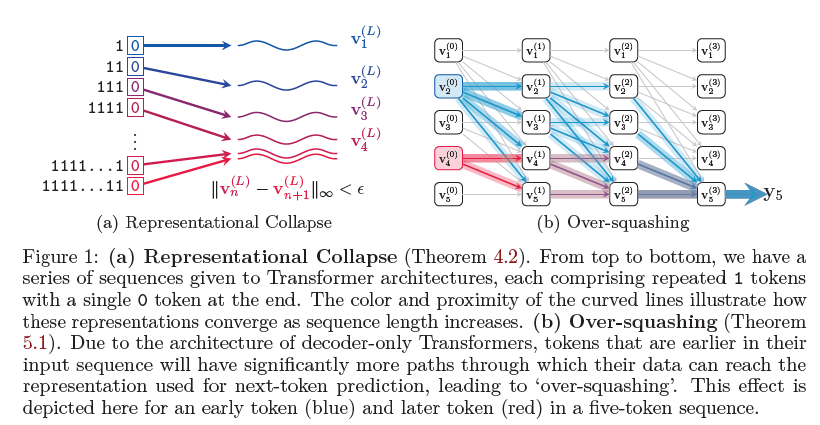
4. 表示崩溃
4.1 理论分析
本文通过理论分析揭示了表示崩溃现象:在某些条件下,两个不同的输入序列在Transformer最终层的表示会变得非常接近,特别是当序列长度增加时。这种现象在低浮点精度下更为明显,导致模型无法区分这些序列。理论分析还指出,这种现象与图神经网络中的过度压缩问题有关。
4.2 实验证明
通过对现有LLMs的实验证实了理论分析的实际影响。实验结果显示,表示崩溃现象在长序列中确实存在,并且会导致模型在复制和计数任务中的表现不佳。特别是当序列中有重复token时,表示崩溃现象更加明显。
5. 信息过度压缩
5.1 理论分析
信息过度压缩现象描述了输入序列中较早的token信息更容易传播到最终表示中,而较晚的token信息则可能丧失。本文通过分析揭示了这种现象在仅解码器Transformer中的表现,并指出这种现象与图神经网络中的过度压缩问题类似。
5.2 实验证明
实验结果显示,输入序列中较早的token信息更容易保留到最终表示中,而较晚的token信息则更容易丧失。这解释了为什么模型在处理长序列时表现不佳,特别是在计数和复制任务中。
6. 计数问题
6.1 理论分析
计数任务需要模型能够精确地处理和传播输入序列中的信息。然而,Transformer模型中的softmax归一化机制和位置编码使得计数任务变得非常困难。本文通过理论分析揭示了这种机制导致的表示问题,并指出这种问题在低精度浮点格式下更加明显。
6.2 实验证明
实验结果显示,Transformer模型在处理计数任务时表现不佳,特别是在序列长度增加时。模型在长序列中的表现迅速恶化,进一步证明了理论分析的有效性。
7. 解决方案
本文提出了一些简单的解决方案来缓解表示崩溃和信息过度压缩问题。例如,通过引入额外的token(👓)来保持表示的距离,或通过调整浮点精度来减少表示崩溃的影响。实验结果显示,这些解决方案在一定程度上改善了模型在复制和计数任务中的表现。
8. 结论与未来工作
本文揭示了仅解码器Transformer在处理某些基本任务时的表示问题,并提出了缓解这些问题的解决方案。未来的研究可以进一步探索如何测量和改善Transformer模型中的信息传播问题,以提升现有语言模型的性能。
一些细节内容:
1)低精度权重/Quantisation可显著加速推理速度,但也有代价
一种常用于加速LLM推理的技术是Quantisation。Quantisation是一种构建LLM近似版本的过程,这种近似版本使用低精度的数据类型运行。这有助于显著提高LLM的推理速度,因为现代加速器在低精度数据类型下能产生显著更多的FLOPs。当然,Quantisation通常是有代价的。我们的理论分析表明,Quantisation可能导致表示的潜在灾难性丧失。特别是,更低的机器精度意味着表示收敛会发生得更早,因此LLM甚至无法区分更短的序列。
在实际应用中,tokenisation使得理论结果的直接应用变得更加复杂。例如,一个重复token的序列“11111”不一定会被tokenised成5个独立的“1”token。从原则上讲,这应该有助于缓解表示的直接崩溃。tokenisation总体上增加了研究这种现象的难度,因为它为实验分析增加了额外的复杂性。在我们的实验中,我们考虑了tokenisation并试图减轻其影响。
2)针对表示崩溃的简单解决方案
Transformer在处理长序列的重复token时会遇到挑战。对此问题的一个实际解决方案是在整个序列中引入额外的token,以帮助保持表示的距离。例如当处理一个全是1的序列时(c)发生了表示崩溃,而每隔三个数字添加逗号则有助于保持表示的分离。