论文MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings提出MUVERA这一理论与实践兼备的多向量检索新框架。该框架通过构建FDE(固定维度编码,Fixed Dimensional Encodings)有效将MV(多向量,Multi-Vector)检索任务转换为SV MIPS(单向量,Single-Vector;最大内积搜索,Maximum Inner Product Search)问题,在保持精度的同时显著降低计算延迟与系统复杂度。尽管在MS MARCO上不明显优于PLAID(可能因为PLAID为其高度定制优化),MUVERA在其他数据集上的泛化性和效率更具优势。未来可探索进一步优化FDE构造方法、适应更广泛的模型结构与领域。
论文作者为Laxman Dhulipala, Majid Hadian, Rajesh Jayaram, Jason Lee, Vahab Mirrokni,均来自Google。
一、研究背景与问题定义
近年来,神经网络生成的嵌入向量(embedding)已成为信息检索(Information Retrieval, IR)中的核心手段。传统的做法多使用单向量(Single-Vector, SV)表示法,即将每个文档或查询编码为一个固定维度的向量,通过高效的最大内积搜索(MIPS)算法进行相似度检索。然而,这种方式在表达能力上存在限制,特别是在捕捉查询与文档之间细粒度语义匹配时。
ColBERT引入了多向量(Multi-Vector, MV)表示,即为文档或查询的每个token生成一个嵌入向量,利用所谓的Chamfer相似度(也称MaxSim)计算整体相似性,这大幅提升了检索质量。然而,MV模型带来了两个挑战:一是每个数据点的向量数量成倍增加,导致存储与计算负担激增;二是Chamfer相似度计算复杂,当前缺乏专门优化的MV检索系统。
二、现有方法的不足
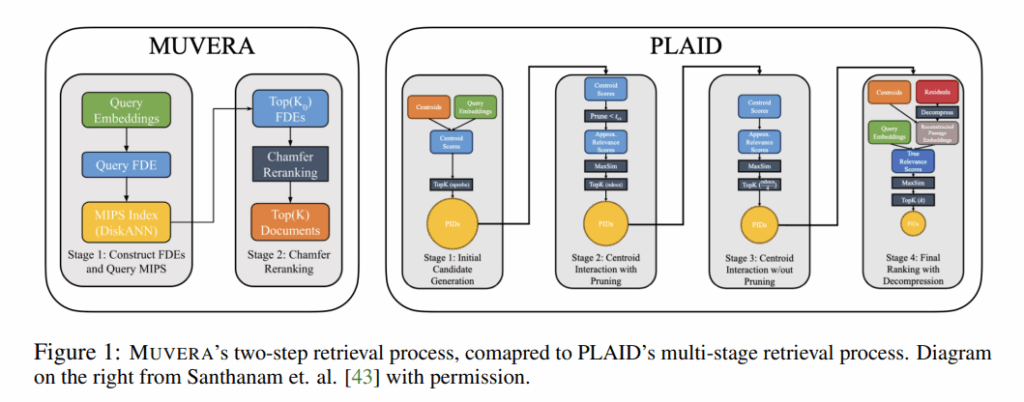
目前主流MV检索方法采用多阶段管线(如ColBERTv2和其加速引擎PLAID),先通过每个查询token与文档token进行SV MIPS检索,挑选出若干候选文档,再使用Chamfer相似度进行重排序。这种做法不仅计算代价高,而且参数调优复杂,难以在不同任务间迁移。此外,由于SV检索方法不能保证Chamfer最近邻的一致性,这些方法的准确性也受到限制。
三、MUVERA方法概述
本论文提出MUVERA(Multi-Vector Retrieval Algorithm),它通过构造固定维度编码(Fixed Dimensional Encodings, FDEs),将复杂的MV检索任务简化为SV MIPS问题。具体做法为:
- 对查询和文档的多向量集合分别构造一个固定维度的FDE向量;
- 保证两个FDE之间的内积能较好地近似原始的Chamfer相似度;
- 通过高度优化的SV MIPS索引(如DiskANN)进行检索,再对Top-k候选文档执行一次Chamfer重排序。
MUVERA是第一个具有理论保证的FDE检索框架,论文证明其能以ε近似恢复Chamfer相似度下的最邻近结果,且查询时间优于穷举计算。
四、固定维度编码(FDE)生成原理
FDE的生成过程基于以下关键步骤:
- 空间划分 φ(x):使用SimHash或k-means将向量空间划分为B个簇。SimHash基于多个高斯随机超平面,构造局部敏感哈希(LSH)映射φ,使得距离近的向量更可能落入同一簇。
- 簇内汇总:对于每个簇k,将落入该簇的query向量加和为q→(k),而document向量求均值为p→(k)。
- 维度压缩 ψ(x):使用随机投影(±1矩阵)将每个q→(k)、p→(k)降至d_proj维。
- 多重重复 Rreps:重复上述步骤R次以降低方差,最终将所有R个投影拼接成完整FDE。
最终,FDE维度为:
d_FDE = B × d_proj × Rreps
文档编码会应用“填充空簇”(fill_empty_clusters)策略,即若某簇无p ∈ P落入,则选择最接近该簇的p作为p→(k),确保编码完整性。
五、理论分析与近似保证
MUVERA的核心理论结果是:
对于任意单位向量集合Q, P ⊂ ℝᵈ,构造出的FDE内积可近似Chamfer相似度,误差不超过ε:
NCHAMFER(Q, P) − ε ≤ ⟨Fq(Q), Fdoc(P)⟩ / |Q| ≤ NCHAMFER(Q, P) + ε
其中NCHAMFER是归一化的Chamfer相似度。构造FDE的必要条件如下:
- k_sim = O(log m / ε)
- d_proj = O(1 / ε² log (m / εδ))
- R_reps = O(1 / ε² log n)
时间复杂度为O(n|Q|),比起O(n|Q||P|)的暴力计算显著更快。
六、实验验证与效果分析
论文在六个BEIR检索基准数据集(MS MARCO、HotpotQA、NQ、Quora、SciDocs、ArguAna)上评估MUVERA的性能。关键结果如下:
- FDE精度提升随维度增长而提高:在相同召回率下,FDE可用更少候选文档数实现高效检索。
- 对比PLAID性能:
- 平均召回率提高约10%;
- 平均延迟降低90%,部分数据集达到5.7倍加速;
- 无需多阶段调参,采用统一配置即可跨数据集稳定运行。
- 压缩能力:
- 使用Product Quantization (PQ-256-8)压缩FDE至原始1/32,仅损失不到2%的召回率;
- 提升吞吐性能(QPS)至原始20倍。
七、对比方法与分析
与SV Heuristic方法对比,MUVERA的FDE在检索候选数量相近情况下表现出更高的Recall@N。例如,在MS MARCO上:
- FDE维度为10240时,只需60个候选文档即可达到80%召回率;
- 而SV Heuristic需300个(去重后)或1200个(不去重)候选文档才能达到相同召回。