隧道是一种很“长”的结构:空间很长、时间也很长。很多风险不是一瞬间发生的,而是由一系列缓慢累积的变化(沉降、变形、衬砌背后脱空、渗水)和少量突变(掉块、塌方征兆、异物入侵)共同叠加出来的。
如果把隧道比作一个复杂系统,那么三维雷达的意义是:它让这个系统从“不可见、不可测”变成“可观测、可对比、可预测”。而真正落地到工程里,关键不在于买到一台设备,而在于把数据采集、处理、建模、识别、预警、仿真、报告变成一条稳定的流水线。
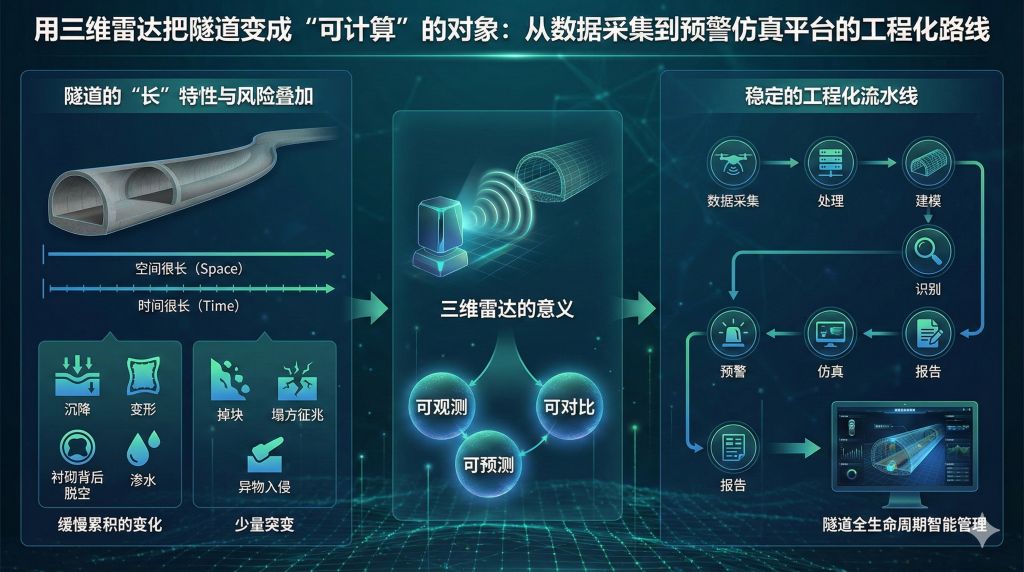
这篇Blog把整条链路拆开讲清楚:
- 三维雷达在隧道里常见的设备类型与输出方式
- 设备输出的数据“到底长什么样”
- 必要的数据处理流程(包含默认参数与可调范围)
- 一个可落地的平台化设计:接口、字段、文件组织、部署形态、迭代路线
一、隧道里的“三维雷达”通常不是一种设备,而是三类能力
很多团队口中的“三维雷达”,实际对应三条技术路线,侧重点不同,经常组合使用:
1) 3D 探地雷达阵列(3D GPR Array)
擅长看“结构内部/衬砌背后”:衬砌厚度、脱空、空洞、含水异常、钢筋/金属物分布等。
数据形态一般是:多通道阵列的 A-scan/B-scan 组合成 3D 体数据,可以做 time-slice(层析切片)与任意剖切。
典型设备/生态里常见:MALÅ(RAD/RD3/RD7)、GSSI(DZT)等格式体系,以及面向 3D mapping 的阵列式产品线。
2) 毫米波 3D/4D 成像雷达(mmWave Imaging Radar)
擅长看“隧道可见空间里的目标”:FOD/异物入侵、运动目标、人员/车辆等(不依赖光照,对烟尘雾更鲁棒)。
数据形态常见两种:
- 上层输出:目标列表(object list / tracks)、点云(point cloud)
- 底层输出:range–Doppler–angle cube(更原始,算力成本更高)
3) 干涉测量雷达(Interferometric Radar)
擅长看“远距离的位移/振动”:洞口边坡、结构远距离变形监测等。
输出常见为:位移图、位移时间序列等,配套控制 PC/软件较多。
结论:不要用“一种雷达”去覆盖所有场景。工程上更合理的做法是:内部缺陷(GPR)+ 空间入侵(mmWave)+ 远距位移(干涉)按需组合。
二、把数据分成三层:Raw / Processed / Product(平台化的关键)
设备输出的数据通常“不可直接用”。真正能支撑三维可视化、对比分析与预警的,是平台侧的“标准化中间层”。建议从一开始就定义三层数据:
- Raw(原始层)
- 原始波形/原始雷达块(厂商格式),外加最小必要元数据
- 目的:可追溯、可复现、可重新处理
- Processed(处理层)
- 完成时零校正、去漂移、滤波、增益、背景去除、(可选迁移)
- 完成时空对齐(时间/里程/姿态)与 t→z(走时→深度)转换
- 目的:可对比、可建模、可切片
- Product(成果层)
- 3D 体数据/瓦片、剖切缓存、病害对象、指标曲线、告警事件、报告材料
- 目的:可展示、可决策、可交付
这三层的好处是:
- 同一套 Raw 可以用不同版本算法重跑(尤其适合长期运营)
- 处理层可以做缓存与加速(适合交互式可视化)
- 成果层可以直接驱动预警、报告、协同闭环
三、三维雷达数据采集:典型接口、典型输出、典型坑
1) 采集链路的两种范式:文件导入 vs 实时流
- 3D GPR 阵列更常见:边采边看,但对外集成通常是文件块(chunk)落盘 → 平台导入处理
- mmWave 成像雷达更常见:SDK/网关实时流(点云/目标列表/雷达立方体)
- 干涉雷达更常见:设备+控制 PC 输出位移与时间序列(文件/接口)
2) 必做:时间同步与里程体系(不做就无法“融合”和“对比”)
隧道场景 GPS 常不可用,定位往往依赖:里程计编码器、轨迹推算、全站仪/里程桩、或 SLAM。
建议每条数据都绑定两套坐标信息:
- 时间轴:统一时间戳(毫秒级)
- 空间轴:里程链(chainage)+ 断面参数(环向角/左右线/拱顶参考)
3) 必做:分段采集与断点续传(数据量决定的现实)
建议按“里程段(10–50m)或时间(30–120s)”滚动生成数据块:
- 采集端容易恢复
- 平台端容易并行处理
- 可视化端更容易加载(LOD/瓦片)
4) 典型文件格式生态(平台必须做“解析适配器”)
工程里常见:
- MALÅ:
.rad+.rd3/.rd7 - GSSI:
.dzt - 开放交换:SEG-Y(
.sgy)
平台不应绑定单一厂商:统一封装成“metadata.json + payload.*”是更稳妥的路线(下文给出文件组织规范)。
四、三维雷达数据内容:建议用“字段字典”把东西讲明白
下面给一个平台侧建议的数据字典(足够覆盖 3D GPR/mmWave/干涉三类)。
1) 采集会话 ScanSession(元数据)
| 字段 | 类型 | 说明 |
|---|---|---|
| session_id | string | 会话唯一 ID |
| project_id / tunnel_id | string | 工程与隧道标识 |
| start_time / end_time | int64(ms) | 会话起止时间 |
| mode | enum | operation巡检 / construction实时 |
| segment | object | 起止里程、左右线、环号/区间 |
| devices | array | 参与设备列表(雷达/相机/里程计等) |
| coordinate_frame | object | 坐标系定义(里程链、零点、拱顶参考) |
| qc_policy | object | 质量控制阈值(丢包率、配准残差等) |
2) 3D GPR 的基础数据 TraceFrame(原始/处理后的单块)
| 字段 | 类型 | 说明 |
|---|---|---|
| frame_id | string | 数据块 ID(建议与文件块一致) |
| timestamp | int64(ms) | 时间戳 |
| chainage | float | 里程(m) |
| pose | object | 可选:姿态/位姿(用于配准) |
| channel_count | int | 阵列通道数 |
| ns | int | 每道采样点数 |
| dt | float | 采样间隔(ns 或 s) |
| tw | float | 时间窗(two-way travel time) |
| samples_dtype | enum | int16/int32/float32 等 |
| raw_payload_ref | string | 原始 payload 地址(对象存储路径) |
| processed_payload_ref | string | 处理后 payload 地址(可选) |
3) 成果对象 Finding(病害/异常)
| 字段 | 类型 | 说明 |
|---|---|---|
| finding_id | string | 病害唯一 ID |
| type | enum | 脱空/空洞/含水异常/掉块风险/异物入侵/变形等 |
| position | object | 里程、环向角、深度/距离(或 3D 坐标) |
| extent | object | 尺寸范围:长度/宽度/深度/体积 |
| confidence | float | 置信度 0~1 |
| evidence_refs | array | 证据包引用(雷达片段/视频/图片) |
| status | enum | 未确认/已确认/已处置/已复核 |
4) 告警对象 Alert(事件闭环)
| 字段 | 类型 | 说明 |
|---|---|---|
| alert_id | string | 告警 ID |
| level | enum | low / medium / high |
| trigger | object | 触发规则、阈值、持续时间、趋势指标等 |
| target | object | 隧道/里程段/构件/病害对象 |
| created_at | int64(ms) | 触发时间 |
| notifications | array | 短信/邮件/声光/移动端推送记录 |
| lifecycle | object | 确认、派单、处置、复核等状态 |
五、必要的数据处理流程:从“能看”到“能比”到“能判”
三维雷达(尤其 GPR)数据处理的核心不是“做得花”,而是把每一步变成可配置、可重复、可审计的流水线。
1) 处理流水线(建议顺序)
- Time-zero 校正(时零校正)
- DC/Dewow(去直流漂移/低频摆动)
- Bandpass 滤波(抑制带外噪声)
- 增益 Gain(深部补偿)
- 背景去除 Background removal(去系统性相干噪声)
- (可选)Migration 迁移成像(提升几何定位)
- t→z(走时→深度)转换(依赖介电常数/速度模型)
- 3D 体生成/插值体素化(支持切片与任意剖切)
- QC 质量评估(配准残差、噪声水平、覆盖率等)
- 识别与指标产出(规则/统计/AI)
- 预警规则引擎(阈值/趋势/仿真一致性)
- 证据包与报告材料生成
2) 默认参数与可调范围(工程可用版)
下面给一组“可直接用作平台默认值”的建议(不同设备/频率会有差异,但这套能作为起点):
| 步骤 | 参数 | 默认值 | 可调范围 | 备注 |
|---|---|---|---|---|
| time-zero | tz_method | first_break | manual/auto/first_break | 建议支持人工微调 |
| time-zero | tz_shift_samples | 0 | -200 ~ +200 | 以采样点为单位 |
| dewow | window_ns | 20ns | 5ns ~ 200ns | 窗口越大越“平” |
| bandpass | f_low | 0.1*f0 | 0.02f0 ~ 0.3f0 | f0=天线中心频率 |
| bandpass | f_high | 2.0*f0 | 1.2f0 ~ 3.0f0 | 结合采样率/奈奎斯特 |
| gain | mode | agc | linear/exponential/agc | 建议同时支持 |
| gain | agc_window_traces | 50 | 10 ~ 200 | B-scan 横向窗口 |
| background | mode | mean_trace_sub | mean/median/pca | PCA 更重但更强 |
| migration | enabled | false | true/false | 默认关,按场景开启 |
| t→z | eps_r | 6.0 | 3.0 ~ 12.0 | 介电常数(需标定) |
| voxelize | grid_dx_m | 0.02 | 0.005 ~ 0.1 | 里程方向栅格 |
| voxelize | grid_dtheta_deg | 1.0 | 0.2 ~ 5.0 | 环向角分辨率 |
| voxelize | grid_dz_m | 0.01 | 0.002 ~ 0.05 | 深度方向分辨率 |
| qc | max_drop_rate | 0.5% | 0.1% ~ 2% | 丢包/缺失率 |
| qc | max_reg_rmse | 0.03m | 0.01m ~ 0.10m | 配准残差 |
关键点:所有参数必须随版本记录(pipeline_version),否则“长周期对比”会失真。
六、文件组织结构:用对象存储把“原始—中间—成果”放稳
建议统一用对象存储(S3/MinIO/OSS)来管理大文件,路径按项目/隧道/会话分层:
s3://tunnel-platform/
projects/{project_id}/
tunnels/{tunnel_id}/
sessions/{session_id}/
raw/
radar/
chunk_{000001}/
metadata.json
payload.rd3 (或 payload.dzt / payload.sgy / payload.bin)
vendor_head.rad (可选保留原始头文件)
video/
cam_{cam_id}/
2025-12-16T09-10-00Z.mp4
processed/
radar/
chunk_{000001}/
processed.bin
qc.json
pipeline.json
products/
scene/
tileset/...
findings/
findings.json
alerts/
alerts.json
reports/
weekly_{2025W50}.pdf
package_{stage_03}.zip
metadata.json 建议固定结构(平台统一),并保留 vendor 字段用于厂商扩展。
七、接口设计:用 REST 管“事实”,用 WebSocket 推“实时”
1) API 设计原则
- REST:会话/设备/任务/成果对象的增删改查(可审计、可重放)
- WebSocket:实时进度、实时指标、告警推送、移动端订阅
2) JSON 示例(可直接当对接契约)
A) 注册设备
POST /api/v1/devices
{
"device_id": "gpr-array-01",
"type": "GPR_ARRAY",
"vendor": "MALA",
"model": "MIRA_HDR",
"interfaces": [
{"kind": "FILE_DROP", "path": "/data/inbox"},
{"kind": "ETHERNET", "ip": "10.0.0.10", "port": 5000}
],
"capabilities": {
"channel_count": 32,
"center_frequency_mhz": 400,
"supports_time_slice": true
}
}
B) 开始采集会话
POST /api/v1/sessions
{
"project_id": "p-001",
"tunnel_id": "t-zhongshan-01",
"mode": "construction",
"segment": {"chainage_start_m": 1230.0, "chainage_end_m": 1280.0, "line": "left"},
"devices": ["gpr-array-01", "cam-02", "odometer-01"],
"coordinate_frame": {"origin": "chainage", "zero_ref": "crown"},
"rollover_policy": {"by_meters": 20.0}
}
C) 上传一个数据块(文件范式)
POST /api/v1/sessions/{session_id}/chunks
{
"chunk_id": "000001",
"timestamp_start_ms": 1765881000000,
"timestamp_end_ms": 1765881060000,
"chainage_start_m": 1230.0,
"chainage_end_m": 1250.0,
"files": [
{"name": "metadata.json", "uri": "s3://.../raw/radar/chunk_000001/metadata.json"},
{"name": "payload.rd3", "uri": "s3://.../raw/radar/chunk_000001/payload.rd3"},
{"name": "vendor_head.rad", "uri": "s3://.../raw/radar/chunk_000001/vendor_head.rad"}
]
}
D) 触发处理流水线
POST /api/v1/pipelines/run
{
"session_id": "s-abc",
"chunk_id": "000001",
"pipeline_version": "gpr-v1.0.3",
"steps": {
"time_zero": {"method": "first_break", "shift_samples": 0},
"dewow": {"window_ns": 20},
"bandpass": {"f_low_ratio": 0.1, "f_high_ratio": 2.0},
"gain": {"mode": "agc", "agc_window_traces": 50},
"background": {"mode": "mean_trace_sub"},
"migration": {"enabled": false},
"t2z": {"eps_r": 6.0},
"voxelize": {"dx_m": 0.02, "dz_m": 0.01}
}
}
E) 告警推送(WebSocket 消息体)
{
"type": "ALERT",
"alert": {
"alert_id": "a-001",
"level": "high",
"target": {"tunnel_id": "t-zhongshan-01", "chainage_m": 1242.3},
"trigger": {"rule": "settlement_rate", "value": 3.2, "threshold": 2.0, "unit": "mm/day"},
"evidence_refs": ["s3://.../products/findings/f-778", "s3://.../raw/video/cam-02/...mp4"],
"created_at_ms": 1765881088000
}
}
八、平台侧能力如何“拼起来”:从三维可视化到预警仿真闭环
1) 三维可视化(不是“炫”,是“可解释”)
核心交互应服务于工程判断:
- 任意剖切(里程/环向/法向)
- 局部放大与“凝视”(锁定变形点持续刷新)
- 多期对比(同里程段不同日期叠加/差分/趋势)
- 病害点标注联动证据包(雷达片段 + 视频/照片)
2) 雷达 + 视频融合取证
建议以“事件”为中心做融合:
- 雷达识别出疑似异常 → 触发相机抓拍/录像片段
- 视频检测到异物入侵 → 触发雷达局部高频扫描(可选)
- 证据包包含:时间、里程、位置、等级、关键帧、雷达切片、原始片段引用
3) 仿真预测:做成“作业系统”,别做成“脚本”
更现实的工程路线是:
- 仿真模板库(几何/材料/边界条件/工况)
- 参数管理与版本化
- 作业调度(排队、资源分配、失败重试、结果解析)
- 结果回写可视化:应力/位移云图叠加到三维场景,并与实测对比
4) 预警:阈值只是起点,趋势与一致性更关键
建议规则引擎支持:
- 阈值 + 迟滞 + 去抖 + 持续时间
- 趋势规则(增长率/加速度超限)
- 一致性规则(实测 vs 仿真偏差超限)
- 告警风暴抑制(聚合/降噪/升级策略)
通知通道按场景选择:声光/短信/邮件/移动端推送。
九、部署与运维:施工要“低延迟”,运营要“可存档”
1) 三种常用部署形态
- 中心化:适合运营(统一归档、统一分析)
- 边缘 + 中心:适合施工(边缘节点实时预处理+告警,中心做深度分析与归档)
- 完全离线:内网/断网环境(本地一体机,阶段性导出报告包)
2) 可观测性(别等出事才知道哪里慢)
建议至少监控:
- 采集:在线率、丢包率、延迟、会话成功率
- 处理:队列堆积、作业耗时、QC 指标(噪声、配准残差)
- 告警:告警量、误报率、通知送达率、处置闭环时长
十、迭代路线:先跑通闭环,再把智能做扎实
MVP(最小闭环)
- 采集接入(文件/流)
- 三维可视化(剖切/定位/局部放大)
- 阈值告警 + 证据包
- 报告导出(PDF/Excel/图像)
V1(可运营/可施工)
- 多期对比与趋势
- GIS 联动与多项目协同
- 施工实时链路与移动端推送
- 质量检测(厚度/超差分区)
V2(提高决策价值)
- 仿真作业体系完善
- 实测-仿真闭环一致性预警
- 识别算法迭代(数据集/标注/版本管理)
- 误报率优化与处置建议自动化
尾声:把“测量”变成“叙事”,把“叙事”变成“决策”
一个好的监测平台,不是把数据堆到屏幕上,而是把数据变成一条可解释的“故事线”:
- 今天这里发生了什么(事件)
- 为什么判断它重要(证据 + 规则)
- 它在变好还是变坏(趋势)
- 如果继续发展会怎样(预测/仿真)
- 我们应该做什么(处置建议/闭环)
当隧道变成一个可计算的对象,我们就不再只是“看到”,而是开始“理解”。这也是工程里最踏实的一种安全感:来自数据,但不止于数据。
相关广告:隧道状态监测系统