论文 VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation 关注一个现实瓶颈:类人机器人很难在真实环境中长期、稳定地完成“边走边干活”的自主任务。这里的“边走边干活”指机器人需要在移动过程中完成抓取、放置、搬运、转身等操作,并且依赖机载视觉传感器在环境中做判断。现有系统往往要么只擅长“盲走路”、要么只做“固定桌面操作”,要么高度依赖人类遥操作与外部传感器,因此离真正可用的自主生产力还有距离。
论文作者为Tairan He, Zi Wang, Haoru Xue, Qingwei Ben, Zhengyi Luo, Wenli Xiao, Ye Yuan, Xingye Da, Fernando Castañeda, Shankar Sastry, Changliu Liu, Guanya Shi, Linxi Fan, Yuke Zhu,来自NVIDIA, CMU, UC Berkeley, CUHK。
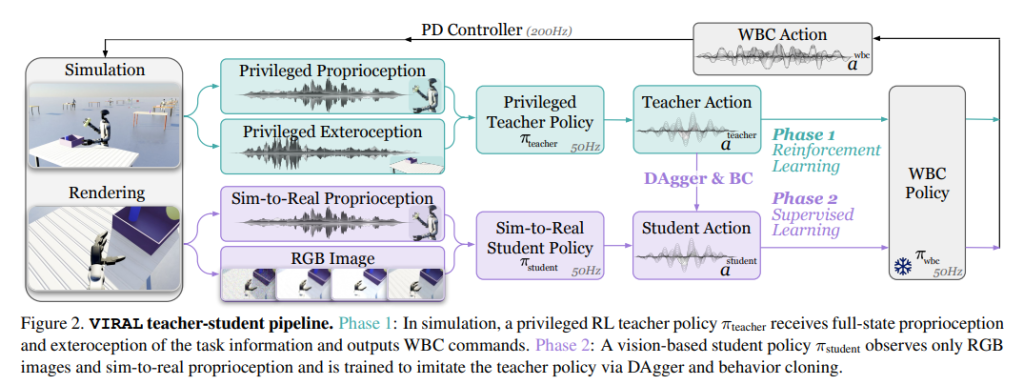
一、VIRAL 的整体思路
作者提出 VIRAL,目标是实现:完全在仿真中学会类人机器人移动操作技能,并且无需真实世界微调就能直接部署到真机(零样本 sim-to-real)。它的关键不是提出某个全新算法,而是提供一套“从仿真到真机可工作的工程配方”,并通过大量消融实验说明哪些环节是刚需、哪些会导致失败。
VIRAL 的主线是一个典型但被“规模化推进”的教师-学生框架:
- 教师策略:在仿真里使用“特权信息”(可获得完整状态与任务信息),通过强化学习学会长时程的移动操作。
- 学生策略:只看真实机器人可获得的输入(RGB 图像与自身传感器信息),通过模仿蒸馏学会复现教师的行为,然后直接上真机。
二、训练“教师策略”的关键设计(为何能学会长时程任务)
论文强调:如果没有一套正确的工程设计,类人移动操作的强化学习很容易学不出来或学得很脆。作者总结了几项对教师训练非常关键的要点:
- 把复杂任务分成阶段目标
把任务拆成“走近目标、放置、抓取、转身”等阶段,让奖励更容易引导策略逐步学会完整链路,而不是盲目探索。 - 用“增量式控制指令”而不是一次性给绝对目标
教师输出的是相对变化的控制意图,更容易稳定学习、加快收敛。论文的消融显示:不用这种增量式表示,训练往往很难达到高成功率。 - 把底层运动控制交给成熟的全身控制器当作“安全 API”
教师不直接学底层电机技能,而是输出高层命令,交给一个预训练的全身控制器执行。这相当于把策略动作空间限制在更安全、更可部署的区域,显著降低“学到仿真技巧但真机不可用”的风险。 - 用示范片段做“参考状态初始化”来解决长时程探索难题
作者在仿真中收集了遥操作示范,然后在每次训练重置时,从示范轨迹中抽取中间状态来初始化场景,让策略从一开始就能接触到“任务中后段的关键状态”(比如接近物体、准备抓取的姿态)。消融结果显示:没有这一步,教师成功率会长期停留在很低水平;加入后能显著提升到高成功率。
三、训练“学生策略”的关键设计(让 RGB 策略能在真机上跑)
学生策略只使用RGB 图像 + 真实可获得的本体传感信息,通过模仿教师学会任务。论文强调学生训练的难点在于:视觉学习昂贵、分布偏移严重、策略容易在真实执行中“越错越离谱”。为此作者给出一套组合拳:
- 在线纠错式模仿 + 传统行为克隆的混合
只用“干净示范”学得快,但容易脆;加入“学生自己滚动产生的状态并纠错”,能显著提升部署成功率。作者通过实验选择了一个折中比例,使训练速度与鲁棒性兼顾。 - 强视觉骨干网络 + 视觉与本体信息融合
用更强的图像编码器提取视觉特征,再与本体信息融合做决策。实验显示:更强的视觉表征能带来更高的成功率与更稳定的训练。 - 引入“历史信息”的策略结构更稳
只看单帧会不稳定;加入短时间历史(例如带记忆的结构或显式历史窗口)能更好处理延迟、遮挡与误差积累,成功率更高。 - 大规模分布式仿真训练系统
视觉渲染使仿真吞吐大幅下降,作者实现了可扩展的分布式训练方案,并强调“规模”不是锦上添花,而是让训练可靠的必要条件之一。
四、Sim-to-Real 的关键:既要“仿真随机化”,也要“真机对齐”
论文认为仅靠随机化不够,还要尽量减少一些结构性差异:
- 大规模视觉域随机化
训练时对光照、材质、颜色、相机参数、画质扰动、相机位姿扰动、传感延迟等进行广泛变化,避免策略过拟合某个“仿真外观”。消融显示:去掉随机化会显著掉性能;去掉任何一个重要分量也会退化,说明它们是互补的。 - 对灵巧手做系统辨识(缩小高减速比手指的真实差异)
Unitree G1 的三指灵巧手由于传动特性,仿真与真实差异明显。作者用真实动作序列做对齐,调整仿真中的关键参数,使仿真手指轨迹更贴近真实。 - 相机视场与外参对齐 + 训练时继续随机化
真实机器相机安装会有误差和漂移,作者做了轻量对齐,并在训练中继续随机化相机外参,让策略对这些误差不敏感。
五、真实机器人效果:能持续循环执行,并具备场景泛化
作者在 Unitree G1 上做了真实部署:机器人在两张桌子之间来回行走,完成放置、抓取、搬运、转身等循环任务。结果显示:在连续多次真实试验中完成了 54 次成功循环,表现接近熟练遥操作员;同时在桌子高度、桌布颜色、光照、物体类别、起始位置等变化下仍能稳定完成任务,体现出较强泛化。
六、论文最强调的结论:计算规模是“成败分水岭”
一个很突出的信息是:算力规模直接决定训练是否可靠。
- 教师阶段:GPU 从少到多,学习速度和最终成功率都会显著提升;算力不足时会长期卡在低成功率。
- 学生阶段:更多 GPU 让训练更快、更平滑、更稳定,最终成功率也更高。
作者把这点作为“现代视觉 sim-to-real”的核心经验:不是只要方法对就行,训练的吞吐与并行规模本身就是系统的一部分。
七、局限与讨论:为何离“通用家务机器人”仍有距离
作者在讨论中非常直白地指出,想把 sim-to-real 扩展到“到处走、什么都能看、什么都能操作”的通用场景,仍存在四类覆盖缺口:
- 物理多样性缺口:柔性物体、食物、复杂接触与材料属性很难在大规模上精确建模。
- 任务长尾缺口:真实世界任务种类与状态变化极多,仿真内容生产成为瓶颈。
- 奖励工程缺口:为大量任务手工设计稳定有效的奖励不具备可扩展性。
- 硬件差距缺口:灵巧手等硬件在摩擦、回差、噪声、热衰减等方面仍难以被仿真完整覆盖。
因此作者倾向认为:未来更现实的路径是把仿真放进一个更大的数据生态里,让仿真与真实数据、模仿学习、基础模型相互补充,而不是指望仿真单独覆盖全部真实分布。
论文项目:https://viral-humanoid.github.io/
类似项目:
https://doorman-humanoid.github.io/
Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer