论文ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills提出ASAP框架,该架构通过两阶段训练和delta动作模型的结合,有效解决了仿真与现实世界之间的动力学不匹配问题,成功实现了人形机器人在现实世界中的高效全身运动控制。实验表明,ASAP能够显著提高机器人在各种复杂运动中的表现,并且具备良好的泛化能力,为未来人形机器人技术的发展提供有价值的参考。
论文作者为Tairan He, Jiawei Gao, Wenli Xiao, Yuanhang Zhang, Zi Wang, Jiashun Wang, Zhengyi Luo, Guanqi He, Nikhil Sobanbab, Chaoyi Pan, Zeji Yi, Guannan Qu, Kris Kitani, Jessica Hodgins, Linxi “Jim” Fan, Yuke Zhu, Changliu Liu, Guanya Shi,来自Carnegie Mellon University和NVIDIA。
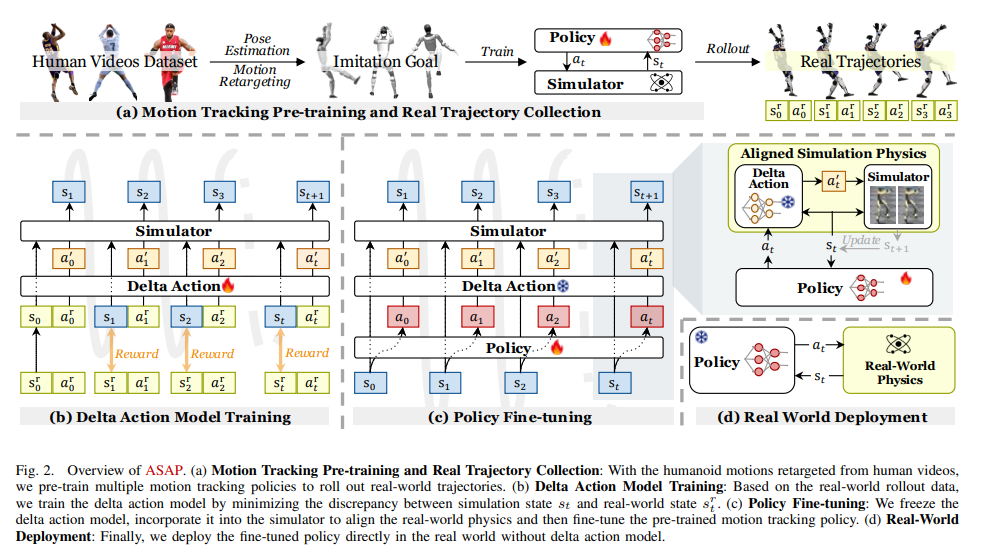
一、引言
随着科技的不断发展,人形机器人在执行复杂、协调的全身运动方面展现了巨大的潜力,尤其是在模仿人类的运动方面。然而,尽管已有不少研究取得了一定成果,实现像人类一样灵活的全身运动仍然是一个极具挑战性的任务。这些挑战不仅来自于机器人硬件的局限性,还来自于仿真环境与现实世界之间的动力学不匹配。这一问题使得很多基于仿真训练的控制策略在实际应用中无法高效执行,尤其是在需要精确协调全身动作时。
目前的研究主要集中在三种方法上来解决这一问题:系统识别(SysID)、领域随机化(DR)和学习动力学模型(Learned Dynamics)。虽然这些方法在一定程度上缓解了仿真与现实之间的差距,但依然存在局限。SysID方法通常依赖于人工设置的物理参数,这些参数往往无法充分捕捉到现实世界中存在的复杂动态。DR方法通过在仿真中随机化参数来增加策略的鲁棒性,但这种方法容易导致过于保守的策略,牺牲了机器人运动的灵活性。另一个问题是这些方法大多依赖手动调节,增加了人工成本,且在面对复杂的动态任务时效果有限。
为此,本文提出了一种名为ASAP(Aligning Simulation and Real Physics)的新框架。该框架通过两阶段的训练策略,旨在解决仿真与现实世界动力学之间的匹配问题,最终实现灵活且协调的全身运动技能。具体而言,ASAP首先在仿真环境中进行预训练,通过模仿人类的运动数据来训练机器人,然后在第二阶段将训练好的策略部署到现实世界,并通过收集现实世界的数据来微调策略,以缩小仿真与现实之间的动态差距。
二、ASAP 方法框架
1. 预训练阶段:学习灵活的人形运动技能
ASAP 的预训练阶段主要在仿真环境中进行,目标是训练一个可以有效模仿人类运动的机器人控制策略。该阶段涉及以下几个关键步骤:
(1)数据生成:重定向人类视频数据
首先,研究人员从视频中收集人类执行复杂运动的序列,并将这些视频转换为3D动作数据。通过TRAM(运动重建工具),可以将2D视频数据转化为3D运动轨迹,并生成SMPL格式的动作数据。这些动作数据经过仿真清洗程序处理,确保其在仿真环境中是物理可行的。处理后的数据用于训练机器人的控制策略。
(2)运动跟踪策略训练
利用这些经过处理的数据,ASAP在仿真环境中训练一个基于相位的运动跟踪策略。该策略的目标是让机器人能够根据人类动作视频数据进行精确的运动模仿。在训练过程中,使用强化学习中的Proximal Policy Optimization(PPO)算法,通过最大化累积回报来优化控制策略。
(3)强化学习策略的设计优化
为了保证训练的稳定性和策略的鲁棒性,ASAP在强化学习过程中采用了一些关键的优化设计:
- 非对称 Actor-Critic 训练:在实际的仿真与现实世界中,一些任务相关的信息(如全局位置、速度等)在现实中是不可观测的。因此,ASAP采用了非对称的Actor-Critic框架,其中Critic网络可以访问这些额外的全局信息,而Actor网络则依赖于机器人自身的感知输入和时间相位变量。这种设计使得训练过程能够更好地适应实际任务。
- 任务容忍度的逐步调整:在仿真中训练灵活的运动控制策略时,面对一些复杂运动(如跳跃)时,策略会倾向于选择保守的动作以避免失败。为了解决这个问题,ASAP引入了终止容忍度的调整机制,逐步收紧容忍度,从而鼓励机器人在训练过程中克服这些困难,提高策略的学习能力。
- 参考状态初始化(RSI):为了防止策略从初始状态开始逐步学习,ASAP采用了随机选择时间相位变量的策略,使得策略可以并行学习不同的运动阶段,从而大大提高训练效率。
2. 后训练阶段:学习 Delta 动作模型并优化策略
预训练阶段训练出的策略能够在仿真环境中跟踪人类的运动轨迹,但由于仿真环境与现实世界的动力学差异,直接在现实环境中执行时会出现较大的性能下降。为了弥补这种差异,ASAP提出了后训练阶段,具体过程如下:
(1)现实世界数据收集
ASAP将预训练的策略部署到现实世界的机器人(如Unitree G1机器人)上,进行实际运动数据收集。通过运动捕捉系统和机器人自身的传感器,记录下机器人的状态信息,包括位置、速度、加速度、关节角度等数据。
(2)Delta 动作模型训练
由于仿真与现实世界之间存在较大的差距,直接在仿真中回放现实世界的轨迹会导致显著的误差。为此,ASAP通过强化学习训练一个delta 动作模型,学习如何补偿这种仿真与现实之间的差异。具体而言,delta 动作模型通过计算仿真状态与现实状态之间的残差,预测出修正动作,并将其添加到仿真控制策略中。
(3)微调策略
通过delta动作模型,仿真环境中的动力学被有效修正。接着,ASAP对预训练的策略进行微调,进一步提升策略在现实世界中的表现。微调过程中,ASAP仍然使用之前定义的奖励函数进行训练,确保策略能够适应现实环境中的各种动态。
3. 策略部署
微调完成后,ASAP将最终的策略部署到现实机器人中,无需再次使用delta动作模型,直接进行实时控制。经过微调的策略在现实世界中表现出更高的运动跟踪精度和更低的误差。
三、实验验证
为了验证ASAP框架的有效性,本文设计了多种实验,主要涵盖了以下几个方面:
1. 仿真到仿真(Sim-to-Sim)评估
在仿真环境中,ASAP进行了仿真到仿真的迁移实验,目的是评估不同方法在解决仿真与仿真环境之间的动力学不匹配方面的能力。实验结果表明,ASAP能够显著减少运动跟踪误差,并且在多个仿真平台之间具有较好的泛化能力。
2. 仿真到现实(Sim-to-Real)评估
在现实环境中,ASAP的策略成功地在Unitree G1机器人上执行了多个复杂的运动任务,如跳跃、侧跳等。与其他方法(如SysID和Delta Dynamics)相比,ASAP表现出了显著的优势:
- 运动精度:在现实世界中,ASAP的策略能够有效减少运动误差,确保机器人能够精确执行复杂动作。
- 鲁棒性:通过delta动作模型的补偿,ASAP能够有效应对现实世界中的动力学差异,提升策略的鲁棒性。
3. 性能评估与对比
为了全面评估ASAP的性能,本文将其与其他几种基线方法进行了对比,包括:
- Oracle(理想情况):假设训练和测试环境完全一致,作为性能的上限。
- Vanilla(基础方法):直接在IsaacGym进行训练,并评估其在不同仿真环境和现实世界中的表现。
- SysID(系统识别):通过在仿真环境中识别和调整物理参数来弥补动力学差异。
- DeltaDynamics(动态残差模型):使用残差动态模型补偿仿真与现实之间的差异。
实验结果显示,ASAP在各项指标(如运动误差、成功率、跟踪精度等)上都显著优于其他方法,尤其是在仿真到现实的迁移能力上,展现了较高的灵活性和准确性。
Human2Humanoid Page: https://agile.human2humanoid.com/
ASAP on GitHub: https://github.com/LeCAR-Lab/ASAP