论文Harnessing the Universal Geometry of Embeddings提出了首个无需配对数据、编码器或预定义匹配集合,即可实现文本嵌入(text embeddings)在不同向量空间之间转换的方法。提出的无监督方法可以将任意嵌入转换为通用潜在表示,或从中还原(即一种由“柏拉图表示假说”所推测的通用语义结构)。该方法在具有不同架构、参数规模和训练数据集的模型对之间,依然能实现高度的余弦相似性。能够在保留几何结构的前提下将未知嵌入转换到另一嵌入空间,这一能力对向量数据库的安全性具有重大影响。攻击者即使只获得嵌入向量,也可能提取出原始文档中的敏感信息,足以执行分类或属性推断任务。
论文作者为Rishi Jha, Collin Zhang, Vitaly Shmatikov, John X. Morris,来自Cornell University。
一、研究背景与动机
本论文研究解决不同语言模型生成的文本嵌入不可兼容的问题。尽管这些模型在语义上表达相同内容,其输出的嵌入向量却处于不同的几何空间,无法直接比较或转换。为此,作者提出了一种全新的无监督嵌入翻译方法 vec2vec,能够在完全不依赖配对数据、编码器结构或训练细节的前提下,将一种模型的嵌入转换为另一种模型的嵌入空间,同时保留原始语义结构。
本方法基于“强柏拉图表示假说(Strong Platonic Representation Hypothesis)”,该假说认为:只要神经网络模型在相同任务上训练(如文本建模),即便使用不同架构与数据,其嵌入空间背后也共享某种可学习的“通用几何结构”,可作为中介进行跨模型转换。
二、问题定义与挑战
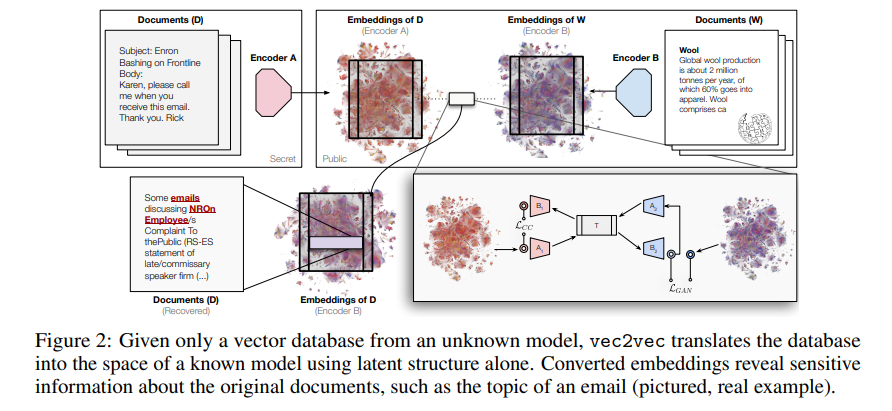
给定一组来自未知模型 M₁ 的嵌入向量 {u₁, …, uₙ},目标是提取其原始文档的语义信息。但我们无权访问 M₁,也无法获得其训练数据或编码器细节。同时我们拥有另一个模型 M₂,可以随意查询,且其输出空间为我们已知。
目标是通过某种“无监督的嵌入翻译器”,将未知空间中的向量 uᵢ 映射到 M₂ 的嵌入空间,使得其结果尽可能接近 M₂(di)。此前的工作大多依赖“配对嵌入”或已知的候选集合,本方法完全不假设这些条件,提出了更困难也更具普适性的设定。
三、方法设计:vec2vec
本方法设计上受 CycleGAN 等图像领域无监督翻译方法的启发,结合循环一致性与对抗损失(GAN)进行训练。其核心结构包括:
- 两个输入适配器 A₁ 和 A₂:将来自模型 M₁、M₂ 的嵌入映射到统一的潜在空间;
- 一个共享变换器 T:对统一空间内的表示进行深度映射;
- 两个输出适配器 B₁ 和 B₂:将潜在表示转换回原始模型的嵌入空间。
从而形成以下映射:
- F₁ = B₂ ∘ T ∘ A₁(M₁ → M₂ 空间)
- F₂ = B₁ ∘ T ∘ A₂(M₂ → M₁ 空间)
- R₁ = B₁ ∘ T ∘ A₁(M₁ → M₁ 空间)
- R₂ = B₂ ∘ T ∘ A₂(M₂ → M₂ 空间)
训练目标函数结合以下几项损失:
- 对抗损失 L_adv:鼓励生成向量与真实向量在分布上无法区分;
- 重建损失 L_rec:输入嵌入经潜在空间回到原空间应能复原;
- 循环一致性 L_CC:经两次映射(M₁→M₂→M₁)应与原始向量一致;
- 向量空间保持 L_VSP:跨空间的几何关系保持一致。
四、实验设置
实验使用多种语料及嵌入模型验证 vec2vec 的有效性:
- 训练语料:Natural Questions(NQ);
- 测试语料:TweetTopic(推文主题分类)、MIMIC(医学病历数据)、Enron(电子邮件)。
嵌入模型涵盖 T5(gtr)、BERT(e5, gte, stella)、RoBERTa(granite)及多模态模型 CLIP,参数规模从百余M至近300M,输出维度包括512与768。vec2vec 被训练在任意两组模型之间,从而实现空间翻译。
五、实验结果与分析
- 翻译质量评估:
在不同模型对之间,vec2vec 显著优于 Naïve 基线(F(x)=x)与 Oracle-Aided Optimal Assignment(已知目标集合的匹配算法)。在同架构模型间(如 e5 ↔ gte),性能接近最优;在跨架构模型间(如 gtr ↔ granite),vec2vec 明显胜出,表现出良好的几何对齐能力。 - 泛化能力评估:
vec2vec 训练自 Wikipedia 风格数据(NQ),但在医疗(MIMIC)与社交语言(TweetTopic)上依然取得良好结果,证明其在不同分布间的迁移能力。 - 多模态扩展性:
vec2vec 可将纯文本嵌入映射至多模态模型 CLIP 的嵌入空间,尽管性能略弱,但依然优于传统匹配方法,展示了跨模态嵌入对齐的潜力。
六、信息提取能力
vec2vec 不仅保留了几何关系,还保留了语义信息,体现在以下两个任务中:
- 属性推断(Attribute Inference):
通过计算嵌入与标签之间的余弦相似度,实现 zero-shot 多标签分类。vec2vec 翻译后的向量在多个任务中显著优于 Naïve 基线,甚至超过同模型嵌入下的理想推断。 - 文本反演(Embedding Inversion):
将翻译后的嵌入输入至预训练的零样本反演模型(如 GPT),能还原出输入文本的关键信息,如姓名、事件、公司、时间等。Enron 邮件测试显示,有的模型对可实现高达 80% 的恢复率,暴露了潜在的隐私风险。
七、相关工作比较
本工作与多个研究方向密切相关,包括:
- 表征对齐(如 CCA、SVCCA、CKA);
- 无监督翻译(如图像 CycleGAN、词向量 Procrustes);
- 嵌入反演(如 GPT 解码、信息泄露评估);
- 模态桥接(如 ImageBind、DreamLLM)。
vec2vec 的创新点在于完全不依赖配对数据,仅通过嵌入空间几何结构实现翻译,且对下游任务有效。
八、讨论与未来展望
作者验证了强柏拉图表示假说在文本嵌入上的成立,并首次展示了通用嵌入空间的构建与利用可在完全无监督设定下实现嵌入翻译。未来的改进方向包括:
- 更稳定的训练策略与架构;
- 扩展至更多数据分布和模型类型;
- 精细化的嵌入反演机制;
- 拓展至更多模态(如图像、音频)及跨模态翻译。