Apple 在其 2024 年全球开发者大会上介绍了 Apple Intelligence,这是一种集成在 iOS 18、iPadOS 18 和 macOS Sequoia 中的个人智能系统。该系统由多个高性能生成模型组成,能够快速、高效地执行各种任务。AFM 分为两个主要模型:AFM-on-device(适用于设备的 30 亿参数模型)和 AFM-server(适用于私有云计算的大型服务器模型)。这些模型旨在高效、准确和负责任地执行各种任务。AFM的详情要点如下:
- 使用GQA、SwiGLU和RoPE构建的密集解码器架构 → 非常类似于Llama
- 预训练数据包括许可数据、公开数据集(代码)和由Applebot抓取的数据
- 使用Safari的阅读器从HTML中提取文本,并通过模型分类、过滤、模糊去重和去污处理
- AFM设备端模型有49k词汇量,AFM服务器端模型有100k词汇量
- 三阶段预训练:核心阶段(网络)、继续阶段(高质量)、上下文扩展阶段(长上下文)
- AFM服务器在TPUv4上训练了7.4T(核心阶段6.3T;继续阶段1T;扩展阶段0.1T)个tokens
- AFM设备端模型由经过修剪的6.4B(从零开始训练)LLM在第一阶段(核心阶段)训练的6.3T tokens蒸馏而来
- 预训练后的最大序列长度为32k
- 生成合成数据,特别是用于数学、工具使用和编码的合成数据
- 后训练使用了SFT + RLHF → 随后进行适配器训练
- RLHF使用了iTeC(新的拒绝采样方法)和MDLOO(类似于RLOO)
- 在后训练中使用RS、DPO、IPO训练了不同的模型,然后生成“最佳”合成数据用于SFT
- AFM设备端模型在超过100万个由“模型委员会”生成的高质量响应上进行了训练
- 使用LoRA适配器结合Apple智能功能的全线性架构
- 结合4-bit量化和适配器训练以恢复质量(在预训练和后训练的10B tokens上训练),然后进行产品特定的适配器训练
- AFM设备端模型运行在iPhone上的Apple神经引擎(ANE)上
- 使用了常见基准测试、MMLU、IFEval、Gorilla功能调用和GSM8k进行评估
- 使用1393个样本与人类专家一起评估通用模型能力
- 使用LLM-as-a-Judge进行任务特定评估,如摘要撰写
Apple发布了报告“Apple Intelligence Foundation Language Models”,该报告详细描述了 AFM 模型的架构、预训练和后训练过程、优化技术以及评估方法,同时强调了负责任的 AI 原则在模型开发中的重要性。通过这些措施,Apple 确保其 AI 模型能够高效、准确地执行各种任务,同时保护用户的隐私和安全。
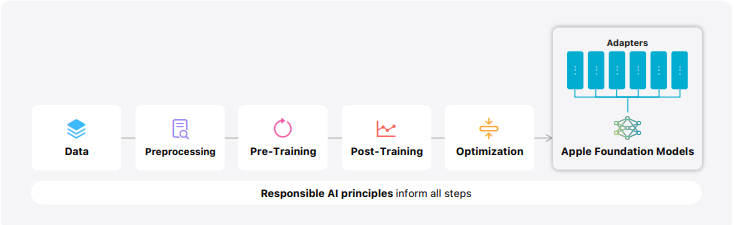
1. AFM架构
AFM 基础模型是基于 Transformer 架构的密集解码器模型,具有以下设计特点:
- 共享输入/输出嵌入矩阵以减少参数的内存使用。
- 使用 RMSNorm 进行预归一化以提高训练稳定性。
- 使用 GQA(分组查询注意力)减少 KV-cache 内存占用。
- 采用 SwiGLU 激活函数以提高效率。
- 使用 RoPE 位置嵌入支持长上下文。
AFM-on-device 模型的具体参数如下:
- 模型维度:3072
- 头部维度:128
- 查询头数量:24
- 键值头数量:8
- 层数:26
- 非嵌入参数数量(十亿):2.58
- 嵌入参数数量(十亿):0.15
2. 预训练
AFM 预训练过程涉及高效的数据质量管理,以确保模型的高质量和低延迟。预训练数据集包括:
- 授权出版商数据
- 公开和开源数据集
- Applebot 爬取的公共数据
预训练分为三个阶段:
- 核心阶段:主要处理大量的网页数据。
- 继续阶段:提高高质量数据(如代码和数学数据)的权重,降低低质量数据的权重。
- 上下文扩展阶段:在长序列长度上进行训练,并包含合成的长上下文数据。
3. 后训练
后训练阶段包括监督微调(SFT)和从人类反馈中进行的强化学习(RLHF)。主要方法包括:
- 使用 iTeC(迭代教师委员会拒绝采样)和 MDLOO(镜像下降策略优化和留一法优势估计)。
- 合成数据生成,特别是数学、工具使用和编码领域。
- 进行人工注释和偏好反馈收集,以改进模型的指令跟随能力和对话能力。
4. AFM-on-device 优化
AFM-on-device 经过精心设计,能够高效地在设备上运行。其优化技术包括:
- 使用 LoRA 适配器进行特定任务的微调,同时保留基础模型的通用知识。
- 应用 4-bit 量化技术以减少内存占用和推理成本,同时保持模型质量。
5. 评估
AFM 模型通过多种基准测试进行评估,包括预训练和后训练阶段的评估,以及特定功能的评估。主要评估指标包括:
- 预训练后的最大序列长度为 32k
- 使用常见基准测试(如 MMLU、IFEval、Gorilla 功能调用、GSM8k)进行评估
- 人工评价模型在实际用例中的表现
6. 负责任的 AI 原则
Apple 在开发 AFM 模型时遵循负责任的 AI 原则,包括:
- 赋能用户,提供智能工具
- 真实地代表用户,避免刻板印象和系统性偏见
- 谨慎设计,预防 AI 工具的误用或潜在伤害
- 保护用户隐私,确保用户的私人数据不会用于模型训练
这些原则贯穿于模型开发的每一个阶段,从数据收集到模型训练,再到最终的产品部署。通过不断的用户反馈和安全评估,Apple 致力于持续改进其 AI 工具,确保它们能够安全、可靠地为用户服务。