Meta近日发布了Llama 3基础模型组,模型支持多语言、编程、推理和工具使用。最大的模型具有4050亿参数,能处理长达128K tokens的上下文。与Llama 2相比,Llama 3在数据质量、训练规模和复杂性管理方面做了显著改进。模型在多个任务上的性能与GPT-4相当。公开发布的Llama 3包括预训练和后训练版本,以及Llama Guard 3模型以确保输入和输出的安全性。
Meta同时发布了研究论文The Llama 3 Herd of Models,介绍了该模型组的研发过程及其相关技术细节。
如下是该论文概要内容(由ChatGPT 4o生成):
1. 概述
现代人工智能(AI)系统由基础模型驱动。本文介绍了一组新的基础模型,称为Llama 3。这是一组原生支持多语言、编程、推理和工具使用的语言模型。我们最大的模型是一个拥有4050亿参数和最多支持128K tokens上下文窗口的稠密Transformer。本文对Llama 3进行了广泛的实证评估。我们发现,Llama 3在众多任务上的质量与GPT-4等领先的语言模型相当。我们公开发布了Llama 3,包括预训练和后训练版本的4050亿参数语言模型,以及用于输入和输出安全的Llama Guard 3模型。本文还介绍了通过组合方法将图像、视频和语音功能集成到Llama 3中的实验结果。我们观察到这种方法在图像、视频和语音识别任务上与最先进的技术竞争力相当。由于这些模型仍在开发中,尚未广泛发布。
2. 模型开发的三个关键因素
论文强调了数据、规模和复杂性管理在高质量基础模型开发中的重要性:
- 数据:相比Llama 2,Llama 3在预训练数据量从1.8T tokens增加到15T tokens。改进的数据预处理和筛选流程确保了数据的高质量。
- 规模:Llama 3主力模型使用了3.8×10^25 FLOPs,几乎是Llama 2的50倍,训练了4050亿参数的模型,处理了15.6T文本tokens。
- 复杂性管理:选择了标准的稠密Transformer架构,并采用了简单的后训练程序以确保稳定性和可扩展性。
3. 模型架构和训练
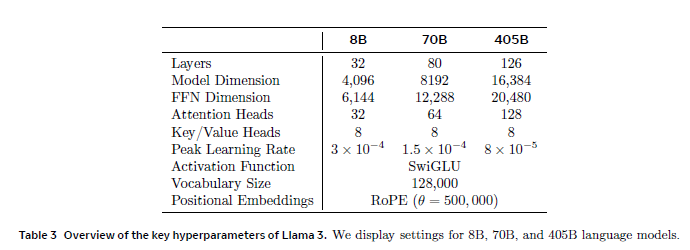
Llama 3使用标准的稠密Transformer架构,进行了若干次小的修改以提高推理速度和长上下文处理能力。这些改进包括使用分组查询注意力(GQA),调整RoPE的基频参数以支持更长的上下文长度,并优化了token词汇表以更好地支持非英语语言。
3.1 预训练数据
- 数据筛选:从多个数据源收集数据,并进行去重和清理,以确保数据的高质量。移除含有大量个人身份信息(PII)和成人内容的域名。
- 数据混合比例:通过知识分类和缩放定律实验确定数据混合比例,最终的混合比例包括50%的通用知识、25%的数学和推理tokens、17%的代码tokens和8%的多语言tokens。
- 退火(Annealing):在高质量数据上进行退火,以提高模型在关键基准测试上的性能。
3.2 模型架构
Llama 3采用稠密Transformer架构,进行了一些小改动:
- 使用分组查询注意力(GQA)以提高推理速度和减少解码期间的键值缓存大小。
- 使用新的token词汇表,提高了对英语和非英语数据的压缩率。
3.3 训练基础设施和效率
Llama 3的训练在Meta的生产集群上进行,使用了大量的GPU和高效的并行计算方法,以确保训练过程的稳定性和效率。
- 训练基础设施:使用Meta的生产集群和Tectonic分布式文件系统进行大规模训练。
- 网络:采用RoCE和Infiniband网络,优化了集群内的网络通信,以减少延迟和拥堵。
- 并行计算:采用了4D并行方法(张量并行、流水线并行、上下文并行和数据并行)以高效分配计算任务。
3.4 训练配方
训练过程分为初始预训练、长上下文预训练和退火三个阶段:
- 初始预训练:使用余弦学习率调度,并在训练过程中逐步增加批处理大小和序列长度。
- 长上下文预训练:逐步增加上下文长度,最终支持长达128K tokens的上下文窗口。
- 退火:在最后40M tokens上进行退火,并进行模型检查点的平均计算,以生成最终的预训练模型。
4. 后训练
Llama 3的后训练过程包括多轮的监督微调(SFT)和直接偏好优化(DPO),以与人类反馈对齐。后训练数据由人类注释数据和合成数据组成。
4.1 模型
后训练策略包括训练奖励模型和语言模型:
- 奖励模型:训练奖励模型以评分不同的响应,并用于拒绝采样。
- 监督微调(SFT):使用拒绝采样和合成数据对预训练语言模型进行微调。
- 直接偏好优化(DPO):使用最新的偏好数据进行进一步优化,以确保模型能够更好地遵循人类指示。
4.2 数据处理和质量控制
- 数据清理:应用规则和模型基于的方法清理低质量样本。
- 数据分类和评分:使用Llama 3模型进行话题分类和质量评分,以确保数据的多样性和高质量。
5. 安全性和责任
Llama 3在输入和输出安全性方面做了显著改进,推出了Llama Guard 3模型。论文详细讨论了模型的安全性评估和缓解措施。
6. 公开发布
Llama 3模型在经过严格评估后,公开发布了三个版本(8B, 70B, and 405B)的模型及其社区许可证,以推动研究社区的创新,并加速人工智能的发展。