论文Large Concept Models: Language Modeling in a Sentence Representation Space设计了一种新型语言模型——大型概念模型(LCM),该模型在语言和模态无关的高层语义表示(“概念”)空间中进行推理和生成。
论文作者为The LCM team, Loïc Barrault, Paul-Ambroise Duquenne, Maha Elbayad, Artyom Kozhevnikov, Belen Alastruey, Pierre Andrews, Mariano Coria, Guillaume Couairon, Marta R. Costa-jussà, David Dale, Hady Elsahar, Kevin Heffernan, João Maria Janeiro, Tuan Tran, Christophe Ropers, Eduardo Sánchez, Robin San Roman, Alexandre Mourachko, Safiyyah Saleem, Holger Schwenk,均来自Meta。
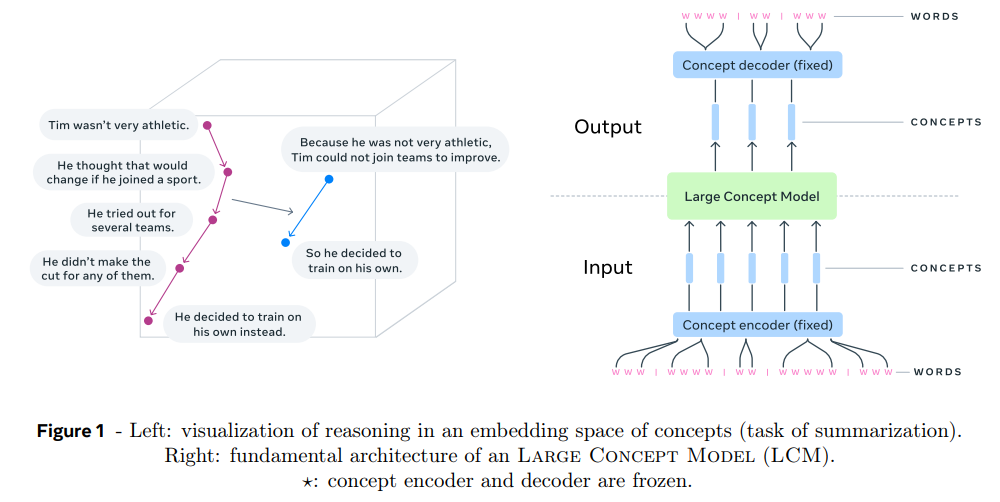
一、背景与研究动机
当前的大型语言模型(LLMs)(如GPT、Llama、Bloom等)依赖于Transformer架构,通常基于子词或单词级别进行生成和预测。然而,与人类语言处理的方式相比,这种架构存在以下不足:
- 缺乏多层次抽象能力:人类在处理复杂任务时,往往先进行高层次规划,然后再逐步细化。例如,在准备演讲或写作时,先形成大纲,然后扩展细节。而现有LLMs仅隐式地学习层次结构,无法显式进行抽象推理。
- 数据和语言依赖:现有LLMs往往需要大量数据,并且模型在不同语言和模态之间的迁移成本较高。
- 缺乏长文本的层次化推理能力:处理长文本时,现有LLMs通常面临上下文窗口长度的限制,导致模型难以捕捉长文本中的逻辑依赖关系。
研究动机:该研究旨在设计一种新型语言模型——大型概念模型(LCM),通过在语言与模态无关的嵌入空间中进行概念级推理,克服上述不足。
二、核心贡献
1. 概念建模
- 概念的定义:在LCM中,“概念”被定义为抽象的语义单元。一个概念可以是一个句子(文本)或对应的语音单元。这种表示比单词级别更接近人类的语言处理方式。
- 使用SONAR嵌入空间:
- SONAR是一种高维句子嵌入空间,支持200种语言文本和76种语言语音的编码/解码。
- SONAR通过去噪自编码器和机器翻译目标进行训练,具有语义对齐的特性。
2. 新型语言建模架构
LCM摒弃了传统的基于单词预测的生成方式,直接在SONAR句子嵌入空间中进行建模。这种方式的主要优势包括:
- 模态无关:模型不依赖于具体语言或模态。
- 显式层次结构:支持长文本的分层推理和生成,易于进行局部修改和交互。
- 零样本泛化:在多语言和多模态任务中无需额外数据即可实现良好性能。
3. 模型模块化与可扩展性
- 编码器和解码器可以独立优化,不存在模态之间的竞争。
- 可以方便地扩展到新语言或模态,例如目前已经实验性支持手语。
三、方法与技术细节
1. 模型设计
LCM的架构由三个主要部分组成:
- 概念编码器与解码器(SONAR):
- 输入文本被分割为句子,每个句子通过SONAR编码为高维概念嵌入。
- 输出概念嵌入通过SONAR解码为子词序列。
- 概念级生成模块:
- 在概念嵌入空间中完成句子预测和生成。
- 模型通过多种架构实现,包括基础的Transformer、扩散模型和量化模型。
- 多种生成策略:
- 均方误差回归(MSE):直接预测下一句嵌入。
- 扩散模型:通过去噪过程逐步生成目标嵌入。
- 量化建模:将连续嵌入离散化,便于生成。
2. 数据预处理
为了在SONAR空间中进行建模,模型需要将原始文本转换为句子嵌入序列,这涉及以下步骤:
- 句子分割:
- 采用SaT Capped技术,结合概率预测和规则限制,确保句子分割的鲁棒性。
- 使用AutoBLEU指标评估分割质量,优化长句的处理。
- 嵌入转换:
- 将分割后的句子通过SONAR编码为嵌入序列。
3. 模型变体
(1)基础模型(Base-LCM)
- 使用标准Transformer解码器,通过MSE损失优化预测嵌入。
- 使用归一化和反归一化层(PreNet和PostNet)调整输入和输出。
(2)扩散模型
扩散模型基于噪声添加和去噪过程进行生成:
- 单塔架构:使用单个Transformer完成上下文编码和嵌入去噪。
- 双塔架构:分离上下文编码器和嵌入去噪器,通过交叉注意力连接。
(3)量化模型
- 使用残差向量量化(RVQ)将SONAR嵌入离散化。
- 提供离散目标(Quant-LCM-d)和连续目标(Quant-LCM-c)的生成方式。
四、实验与结果
1. 预训练评估
数据集:
- 使用ROC-stories、C4、Wikipedia-en和Gutenberg等数据集进行评估。
- 指标包括欧几里得距离(L2)、对比准确率(CA)、互信息(MI)等。
结果:
- 扩散模型在一致性(CA)和生成质量(MI)上优于量化模型和基础模型。
- 双塔架构的扩散模型在多个数据集上表现最佳。
2. 微调与下游任务
任务:
- 在Cosmopedia数据集上微调,用于生成连贯的故事。
- 评估指标包括ROUGE-L(生成与参考文本的重叠)和一致性分数(文本逻辑连贯性)。
结果:
- 扩散模型(尤其是双塔架构)在生成一致性和流畅性上接近或超过现有LLMs(如Llama)。
3. 超参数与噪声调度分析
影响因素:
- 噪声调度(如Cosine、Sigmoid)对生成质量有显著影响。
- 宽谱Sigmoid调度在对比准确率和互信息上表现优越。
五、总结与展望
1. 当前成果
- LCM通过概念级推理克服了LLMs的许多局限性,尤其是在长文本生成、多模态泛化和语言无关性上。
2. 局限性
- SONAR嵌入空间可能对部分低资源语言的支持存在偏差。
- 当前的扩散模型在推理效率上仍有改进空间。
3. 未来方向
- 探索更高层次的抽象表示(如段落或章节级别)。
- 提升模型的推理效率,例如通过稀疏注意力机制优化扩散模型。
- 开发更通用的嵌入空间,适应更复杂的多模态任务。
LCM(Large Concept Models) on GitHub: https://github.com/facebookresearch/large_concept_model