论文MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts介绍了MoMa这种新颖的架构,旨在提高混合模态早期融合语言模型预训练的效率。MoMa通过将专家模块划分为文本和图像特定的组来处理图像和文本的统一序列,从而显著提高预训练效率和性能。
论文作者为Xi Victoria Lin, Akshat Shrivastava, Liang Luo, Srinivasan Iyer, Mike Lewis, Gargi Gosh, Luke Zettlemoyer, Armen Aghajanyan,来自Meta FAIR。
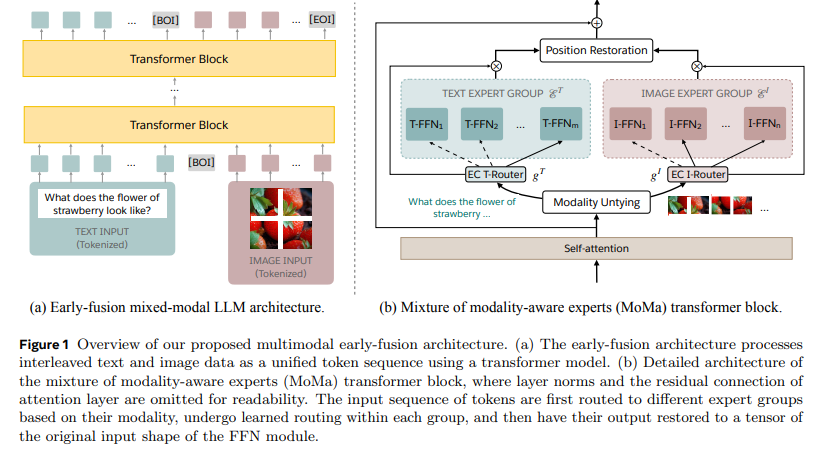
以下为论文内容概要:
一、主要贡献
- MoMa架构的引入:
- 将专家模块划分为文本特定和图像特定的组。
- 在每个组内使用学习的路由保持语义自适应性。
- 效率提升:
- 与计算等效的密集基线相比,MoMa实现了3.7倍的总体FLOPs节省。
- 具体节省:文本处理提升2.6倍,图像处理提升5.2倍。
- 与深度混合(MoD)的结合:
- 进一步将预训练效率提高到4.2倍,尽管这种结合在因果推理任务中对路由器准确性敏感性增加。
二、研究内容介绍
1. 引言
论文讨论了现有的混合模态基础模型在集成模态特定编码器或解码器时的局限性,例如扩展时的挑战和跨模态信息集成的低效性。MoMa通过将稀疏架构应用于混合模态早期融合模型,解决了这些问题。
2. 模型
早期融合:
- 基于Chameleon架构,MoMa将图像和文本标记化为离散的标记,从而在Transformer模型中实现统一处理序列。
宽度扩展与模态感知专家混合:
- 在每个MoE层中实现模态特定的专家组,使得文本和图像标记能够进行专门化处理。
- 分层路由机制将标记首先引导至模态特定的组,然后在这些组内根据学习的标记到专家的亲和度评分进行路由。
深度混合(MoD):
- 在深度维度引入稀疏性,允许标记根据学习的路由函数跳过某些层。
- 提高了效率,但由于动态标记跳过,增加了推理过程的复杂性。
推理与再利用:
- 在推理过程中,辅助路由器通过预测标记路由确保因果性。
- 再利用技术从简单的稀疏架构开始,并将其演化为更复杂的架构,改善路由器学习和整体效率。
3. 效率优化
负载平衡:
- 通过平衡标记混合比例,确保跨GPU的计算资源高效利用。
高效的专家执行:
- 根据标记负载和专家专门化,选择顺序或并行运行专家的方法,以优化吞吐量并减少延迟。
额外优化:
- 通过梯度通信量化、GPU内核融合以及预先计算标记索引等技术,提升训练吞吐量。
4. 实验
设置:
- 在超过1万亿标记上进行广泛的预训练,使用各种模型配置比较密集和稀疏架构。
计算性能的扩展:
- 与密集模型相比,MoMa配置在预训练损失收敛方面表现出显著提升,特别是在图像标记处理方面表现出显著的效率。
专家数量的扩展:
- 实验不同模态专家数量的影响,发现超过一定数量后回报递减,强调了平衡专家分配的重要性。
再利用:
- 当从较小、较简单的架构再利用模型时,显示出1.2x到1.16x的FLOPs增益。
吞吐量分析:
- 虽然稀疏模型提供了效率增益,但引入了开销。在吞吐量和质量之间的权衡进行了讨论。
推理时性能:
- 在保留的数据集和常识推理任务上的评估显示,MoMa在文本到文本任务中表现出色。
5. 相关工作
该论文将MoMa与其他早期融合、稀疏多模态语言模型进行对比,突出了其在参数效率和跨模态集成功能方面的进步。
6. 限制
负载平衡跨GPU的挑战、推理过程中动态标记路由的复杂性以及辅助路由器的优化都是需要解决的挑战。
7. 结论
MoMa利用模态感知稀疏性显著提高了混合模态早期融合模型的预训练效率,展示了相对于密集和标准MoE架构的显著改进。其可扩展性和效率提升为资源更高效和功能更强大的多模态AI系统铺平了道路。