论文SensorLM: Learning the Language of Wearable Sensors提出了一个名为 SensorLM 的模型,该模型能够通过自然语言理解可穿戴传感器数据。
论文作者为Yuwei Zhang, Kumar Ayush, Siyuan Qiao, A. Ali Heydari, Girish Narayanswamy, Maxwell A. Xu, Ahmed A. Metwally, Shawn Xu, Jake Garrison, Xuhai Xu, Tim Althoff, Yun Liu, Pushmeet Kohli, Jiening Zhan, Mark Malhotra, Shwetak Patel, Cecilia Mascolo, Xin Liu, Daniel McDuff, Yuzhe Yang,来自Google和University of Cambridge。
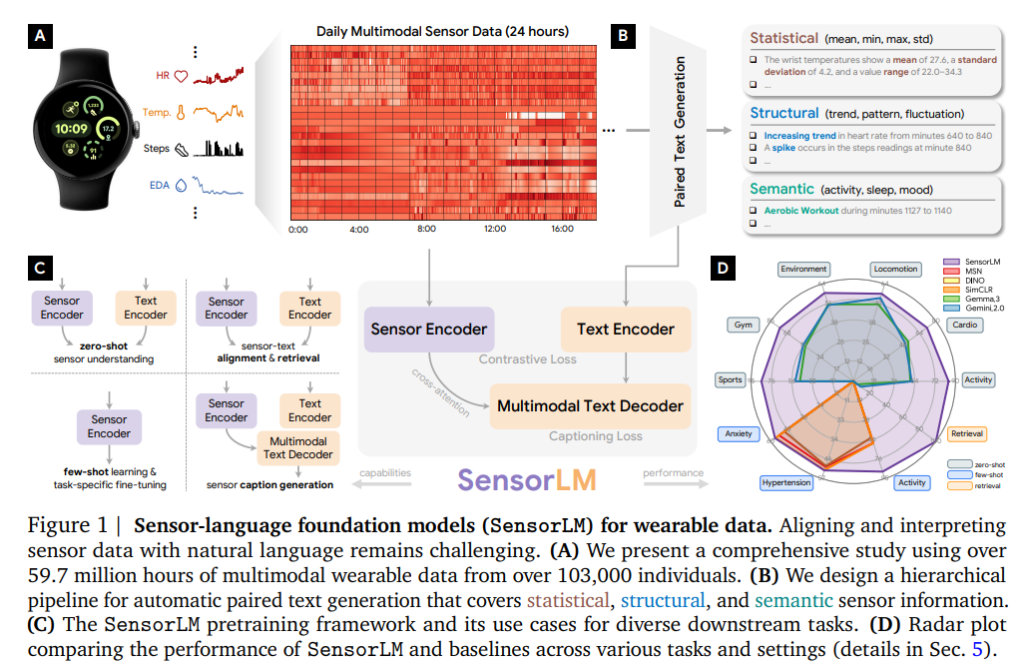
虽然可穿戴设备产生了大量与用户生理、行为相关的多模态时序数据,但由于缺乏大规模、高质量的传感器-文本配对数据,现有方法难以实现精准、通用、可迁移的理解与解释。SensorLM 的核心贡献在于三方面:一是设计了一种分层的自动化传感器文本生成方法,覆盖统计、结构与语义三个层次;二是基于此流程构建了迄今为止最大的传感器-语言数据集,涵盖超过59.7百万小时、逾10万人数据;三是提出了统一架构的预训练模型框架,整合对比式(CLIP)、生成式(Cap)和混合式(CoCa)多模态方法。
在数据方面,SensorLM 使用来自 Fitbit 和 Pixel Watch 的多模态数据,包括心率(PPG)、三轴加速度(ACC)、皮肤温度(TEMP)、皮电反应(EDA)、气压高度(ALT)。模型输入为每日1440分钟、26维特征的二维矩阵。由于原始信号频率高(最高达200Hz),为实现可扩展性和节省存储,研究者提取统计特征而非使用原始波形数据。
在数据配对方面,研究者提出了一种分层文本生成系统,包括三种类型的 caption:
- 统计型:通过模板生成每个特征(如心率、步数、温度)的均值、标准差、最大值、最小值的描述。
- 结构型:捕捉时间序列中的趋势、突变、波动(如“步数在第840分钟出现突增”)。
- 语义型:映射至高层语义活动(如“830-850分钟为椭圆机运动”或“第5-449分钟为睡眠”),还引入用户自报的心情等上下文。
基于这些文本,研究者构建了2,489,570人日数据,涵盖103,643人,分布于127个国家,是迄今为止最大规模的传感器-语言配对数据集。
在模型架构方面,SensorLM 由三部分组成:传感器编码器(基于 ViT,处理二维时间序列 patch)、文本编码器(标准 Transformer)、多模态文本解码器(Causal Masked Transformer with Cross-Attention)。预训练目标函数由对比损失(Lcon)与生成损失(Lcap)加权组合,可调节为三类代表模型:纯对比(CLIP式)、纯生成(Cap式)和混合(CoCa式)。此外,模型按规模划分为四个版本(S/B/L/XL),参数量从3M到1.27B不等。
在下游任务中,研究者在三个方面进行了实证验证:活动识别(Activity Recognition)、健康状态预测(如高血压和焦虑)、跨模态检索。结果显示:
- 在零样本分类中,SensorLM 在 AUROC、F1 分数和 Balanced Accuracy 上远超 LLM(如Gemma-3-27B、Gemini 2.0),即使这些LLM接受了格式化输入,也无法胜任这类任务。
- 在跨模态检索中(传感器到文本、文本到传感器),SensorLM 几乎达到100%准确率,LLM则基本失败。
- 在小样本学习任务中,SensorLM 显著优于现有自监督基线(如SimCLR、MSN、DINO),表现出极高的特征迁移能力。
- 在未知活动泛化任务中,SensorLM 对“滑雪→滑板”等概念相近的新类别依旧具有良好AUROC值,说明模型学习的是概念分布而非记忆具体类别。
- 在传感器描述生成任务中,SensorLM 能直接从输入传感器数据生成语义合理的自然语言文本,且优于 Gemini 和 Gemma 系列LLM。
消融实验进一步探讨了不同 caption 组合对预训练的影响。发现:
- 语义 caption 对零样本活动识别至关重要。
- 结构 caption 的加入有助于提升模型对时序行为的理解,进一步提升表现。
- 统计 caption 单独效果较弱,但在健康状态预测任务(如焦虑)中则提供了补充性信息。
- 在架构对比中,CoCa 式的混合目标表现最优,Cap 式纯生成模型由于缺乏对比对齐,零样本效果较差。
尽管成果显著,论文作者也指出了模型的局限性。首先,SensorLM 尚未经过临床验证,不应作为诊断工具直接使用。其次,模型仅使用 Fitbit 和 Pixel Watch 的数据,尚需扩展至其他设备与数据类型。