论文Exploring Network-Knowledge Graph Duality: A Case Study in Agentic Supply Chain Risk Analysis针对“供应链风险分析”这一强网络属性、强多模态的数据场景,批判了传统做法:其一,依赖专项微调的领域模型,更新慢、成本高、对时效性差;其二,常见的向量检索式 RAG 将关系语义过度简化为“相似度近邻”,忽视了供应链天生的图结构与路径语义。作者提出以“网络—知识图谱(Network–KG)二重性”为理论抓手:把供应链网络同时视为知识图谱(实体—关系三元组),在推理时用网络科学(中心性、路径)指导检索,再把提取到的“经济上最有意义”的子图用自然语言模板(context shells)显式喂给一个“冻结”的通用 LLM,实现低成本、可解释、可实时更新的风控叙述。
论文作者为Evan Heus, Rick Bookstaber, Dhruv Sharma,来自UC Berkeley和MSCI。
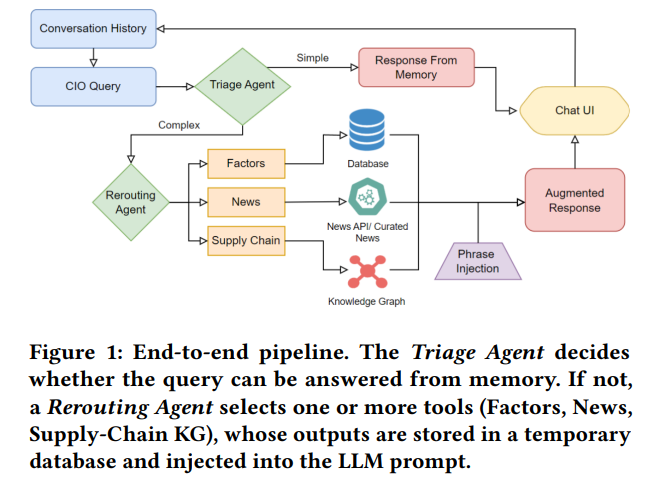
一、方法框架总览(Agentic RAG 的三段式回路)
论文提出两层轻量代理协同的一条龙流程:首先由“分诊代理(Triage Agent)”判断问答是否可直接由记忆回答;否则交给“重路由代理(Rerouting Agent)”在三种工具中选择检索:因子数据(Factors)、新闻(News)、供应链 KG 遍历(Supply-Chain KG)。三类数据各自建独立 FAISS 索引,检索结果写入临时库,再与用户问题一起注入“冻结”的 GPT-4o,生成“增强回答”。该解法以工具调用的 JSON stub 组织数据,避免了专门图数据库运维与模型再训练成本。
二、Network–KG 二重性与为什么“图检索优先”
供应链中的边(如 Company—Produces→Product、Product—Has Input→Product、Product—Manufactured In→Location)既是网络的连边也是知识图谱的语义关系。传统向量相似度把事实当“点”,而供应链风险“活在边上与路径上”。把 KG 当作图 𝐺=(𝑉,𝐸) 后,检索的基本单位从“相似段落”变为“可解释路径”,例如 Apple→Smartphones→Integrated Circuits→Shanghai。这让 LLM 在提示词中直接读取“公司—产品—地点”的经济叙事骨架(及可能的边权如收入占比、成本占比),从而减少臆测、提升可解释性与决策相关性。
三、三类数据通道与对应工具
(一)因子数据(MAC Factors)
对组合内每只证券的多资产因子暴露进行语义包装,既保留数值,也在嵌入中编码解释文本,便于语义检索时召回“数字+含义”而非孤立数字。工具:get_factors。
(二)新闻(Curated News)
引入宏观长周期与逐日个股新闻(如 LexisNexis),分块、嵌入、保留时间与来源元数据,支持“当日/近期”过滤。工具:get_news。
(三)供应链知识图谱(Supply-Chain KG)
包含 Company / Product / Input Product / Industry / Location 五类节点与多种关系,原型图谱通过 LLM 管道合成(方法学上借鉴 AIPNet),用于在线遍历、抽取“高显著性风险路径”。工具:graph traverser。
四、Context Shell:把“冷数字”变成“可推理语言原子”
LLM 对生硬的数字 token 不敏感。作者将每行因子表封装成若干短段落模板:把数值(如 z-score)嵌进解释句(“当该因子为高时意味着……为低时意味着……”),让“数字邻域”的词语共同被嵌入,进而在检索与注意力中赋予数值语义。这种“语言化数字”让冻结的通用模型也能进行数量化推理叙述,无需额外微调。
五、网络科学指导的“排—取—述”三步遍历
(一)种子与匹配
从用户问题中抽取公司/产品/地点字符串,用与节点相同的嵌入模型做向量检索,得到最贴近经济语义的种子节点。
(二)中心性驱动的自适应深度
对所有节点预计算三类无权中心性:度中心性(局部连接数)、接近中心性(到全图平均最短距离)、中介中心性(处于最短路的频率)。论文用三者平均作为“结构显著性”,决定从某个种子向外扩展的跳数:枢纽与瓶颈附近一跳就很“信息密”,外围节点可能需要两跳。这样既控窗口长度,又优先经济相关高的子图。
(三)路径转述与语义模板
把抽到的加权路径(如“Apple→Desktop Computers→Integrated Circuits→Shanghai”,边权示意 10%/19%/13%)转述为“Apple 的 Desktop Computers 收入占比 10%,其生产成本中 19% 来自集成电路,其中 13% 产自上海”这类固定语式,随后与因子壳、新闻片段共同注入提示词,成为 LLM 的“可解释支架”。
六、与相关工作的比较定位
论文把自身定位在两端之间:一端是“自底向上的 KG 课程与专项微调”(如将多跳路径口述成训练题监督 32B 模型),另一端是“GraphRAG 与层次化社区摘要”这类重预处理、重离线汇总的方法。作者选择在“推理时”以轻量遍历+语义模板组装证据:无需持续微调、也不必维护大型图数据库与层级摘要仓,因而更贴实时、运维成本低、解释性更强。
七、样例对话的风控叙事能力
示例从“DRC 的钶钽铁矿(coltan)问题”切入,系统把“coltan”定位为上游矿产产品节点,沿路径关联到 Apple/Tesla 的电池线与钴/钽供应风险,再调用当日/近期新闻,输出“供应中断、ESG 声誉、成本挤压利润”的三类影响,并能将“组合权重最高的 Apple”置于叙事中心。这展示了该体系把“文本线索—图路径—新闻因子”一体化的证据链构造能力。
八、优点与创新点
- 可解释性强:以“公司—产品—地点/投入品”的自然语言路径为骨架,显式呈现依赖链路与潜在瓶颈。
- 低运维与低时延:避免重型图数据库与大型离线汇总管线,工具调用与 FAISS 检索即可响应实时查询。
- 多模态融合自然:因子“语言壳”+新闻+图路径同屏,冻结 LLM 即可生成数量化且上下文充足的风控文字。
- 上下文经济性:中心性控制遍历深度与节点数,缓解“长上下文丢失中部信息”的已知问题。
九、局限性与改进方向(论文自述+实务建议)
- 图谱质量与覆盖:原型图由 LLM 生成,范围与准确度有限。应引入海关申报、提单(B/L)与贸易数据库校验与扩充,形成“LLM 生成—结构化数据校准”的闭环。
- 仅用无权中心性:可能忽视“结构边缘、但财务权重极高”的节点。可引入加权最短路、价值加权中心性(如 revenue-weighted betweenness)或电阻距离等指标。
- 边权静态:建议把营收拆分、成本结构、地区产能、物流时效、舆情打分等流入实时特征,动态刷新边权与路径打分。
- 事实一致性与幻觉治理:对“路径转述模板”增加可验证字段与来源标签,在回答中附带证据引用与时效戳。
- 组合维度的归因:把图路径与持仓权重、因子暴露联立,输出“风险贡献分解”(边/路径→单证券→组合层级)与情景压测结果。
十、可落地实施蓝图(面向企业风控团队)
- 数据层
- 结构化:证券主数据、财报口径的营收按产品/地区拆分、BOM/HS-Code 映射。
- 半结构化:合规采购清单、供应商名录、合同条款。
- 非结构化:合规/舆情/突发事件新闻流。
- 知识构建
- 以规则+LLM 双轨抽取实体与关系,优先“Company↔Product↔Location/Inputs”。
- 为节点/边生成 context shell(含单位、口径、时间戳、置信度)。
- 检索与遍历
- FAISS 建三库(因子/新闻/KG),节点预计算多类中心性(含加权版)。
- 遍历策略:按问句触达的“实体簇”自适应跳数+跨模态召回(新闻/因子作为路径先验)。
- 提示组装与回答
- 组合快照置顶,随后拼接“路径壳 + 因子壳 + 新闻片段”,输出“证据对齐-可追溯”风控叙事与行动清单。
十一、与传统 GraphRAG/Neo4j 工作流的取舍
- 若你已有成熟 Neo4j 集群与 Cypher 生态,LangChain Graph Retriever 能在毫秒级返回模式匹配结果,但要付出图服务的持续运维与内存缓存成本。本文方案把“遍历”降到“按需抽子树+语义转述”,以工程最小化换取时效与可解释输出。适合中小团队或需要快速试点的风控场景;大型机构可采用“线上轻量遍历 + 离线图服务兜底”的混合架构。
十二、结论
论文以“网络—知识图谱二重性”为理论基座,提出“中心性驱动的路径检索 + 数字语言化模板 + 轻量代理编排”的供应链风控 RAG 框架。它不追求大而全的离线图与专模微调,而是在推理时把“最经济相关的子图”送进 LLM 的注意力核心,使回答既短而准、又带来高度可解释的经济叙事,对实时性要求高的金融与供应链场景具有良好落地前景。