论文BitNet Distillation提出 BitNet Distillation(BitDistill)框架,将现成全精度大模型(如 Qwen 系列)以极低成本微调为 1.58-bit(三值 {-1,0,1})权重量化模型,用于具体下游任务,同时在 CPU 上实现约 10× 内存缩减与 2.65× 推理加速,并把精度维持在接近 FP16 的水平。核心做法包含三阶段:在 Transformer 层内新增 SubLN 稳定训练;使用少量通用语料做继续预训练以消除随模型规模扩大的性能差距;最后进行“logits 蒸馏 + 多头注意力关系蒸馏(MiniLM 风格)”。在分类(MNLI/QNLI/SST-2)与摘要(CNN/DailyMail)上,BitDistill 的 1.58-bit 模型与同规模 FP16 微调结果基本持平但显著更省资源。
论文作者为Xun Wu, Shaohan Huang, Wenhui Wang, Ting Song, Li Dong, Yan Xia, Furu Wei,来自微软。
一、研究动机与问题界定
极低比特(如 1.58-bit)BitNet 已证明能大幅降低内存与算力,但以往要想在下游任务上有好效果,常需“从零预训练”巨量语料(例如数万亿 tokens),代价高昂。另一路径是直接对现成全精度 LLM 做 1.58-bit 的 QAT 再在任务上微调,但作者观察到:这种“直转直训”的稳定性差、与 FP16 的精度差距明显且“越大模型差距越大”的可扩展性问题突出。因此论文目标是:不从零训练,只靠轻量流水线把全精度 LLM 可靠地压到 1.58-bit,并在不同模型规模与任务上保持接近 FP16 的可扩展性能。
二、方法总览(BitDistill 三阶段)
1)建模改造(Stage-1):在每个 Transformer block 的 MHSA 输出投影前与 FFN 输出投影前插入 SubLN,使量化后激活方差受控、训练更稳定。
2)继续预训练(Stage-2):用一小部分通用语料(文中示例为 FALCON 语料抽样 10B tokens)对“已插入 SubLN 并做量化”的模型做短暂语言建模训练,帮助权重分布向“适合三值化”的形态迁移,缓解规模放大时的精度鸿沟。
3)蒸馏式微调(Stage-3):以同任务 FP16 教师指导 1.58-bit 学生,联合使用 logits 蒸馏(KL)与注意力关系蒸馏(MiniLM 思路,对 Q/K/V 的关系矩阵做 KL),配合任务交叉熵形成三项损失的加权组合。
三、量化与反传近似的技术细节
权重量化采用 per-tensor 的 absmean 阈值三值化:先用 Δ=mean(|W|) 归一,再四舍五入并裁剪到 {-1,0,1};激活量化采用 8-bit、per-token 的 absmax/absmean;由于 RoundClip 等操作不可导,反向传播用直通估计(STE)。这些选择在保证实现简单的同时兼顾了训练可行性。
四、Stage-1:SubLN 的作用机制
低比特模型常见激活方差膨胀与优化不稳。作者在 MHSA 与 FFN 的输出投影前各加一层 SubLN,相当于在“进入被量化的线性投影之前”先把表征尺度稳住,从而减小三值化带来的非线性扰动对收敛的破坏。实验证明,引入 SubLN 后的收敛速度更快、最终损失更低,下游效果更好。
五、Stage-2:为何“少量继续预训练”能解决可扩展性难题
直接把全精度权重压到 1.58-bit,有限的下游任务数据不足以把权重调整到“量化友好”的分布,规模越大越难学。继续预训练用少量通用语料进行语言建模,让权重分布从接近高斯,迁移为更像“从零训练 BitNet”时出现的集中分布,尤其在 0↔±1 的阈值附近聚集更多权重,使量化后的小梯度也更容易引起码元翻转,提升可拟合性与收敛性。作者的可视化与损失曲线对这一假设提供了实证支持。
六、Stage-3:蒸馏设计与损失函数
1)Logits 蒸馏:对教师与学生的温度化 softmax 输出做 KL(τ=5)。
2)注意力关系蒸馏:沿 MiniLM 系列,只在单个精选层进行(而非全层),分别对 Q/K/V 的“归一化后关系矩阵”(scaled dot-product + softmax)做 KL;实验证明“仅一层且靠后的层”更优,给学生留出足够的自适应自由度。
3)总损失为 L = LCE + λ·LLD + γ·LAD。分类任务建议 λ=10, γ=1e5;摘要任务 λ=1, γ=1e3。
七、实验设置与评价
基座模型以 Qwen3(0.6B/1.7B/4B)为主,并在 Qwen2.5 与 Gemma 上验证普适性;训练序列长 512,batch 32;继续预训练阶段使用 10B tokens(相对从零训练 BitNet 需约 4T tokens 的成本几乎可忽略);微调与评测覆盖 GLUE 的 MNLI/QNLI/SST-2 与 CNN/DailyMail 摘要,生成评测用 BLEU/ROUGE;效率评测在 16 线程 CPU 上统计 tokens/s 与内存占用。
八、主要结果与指标解读
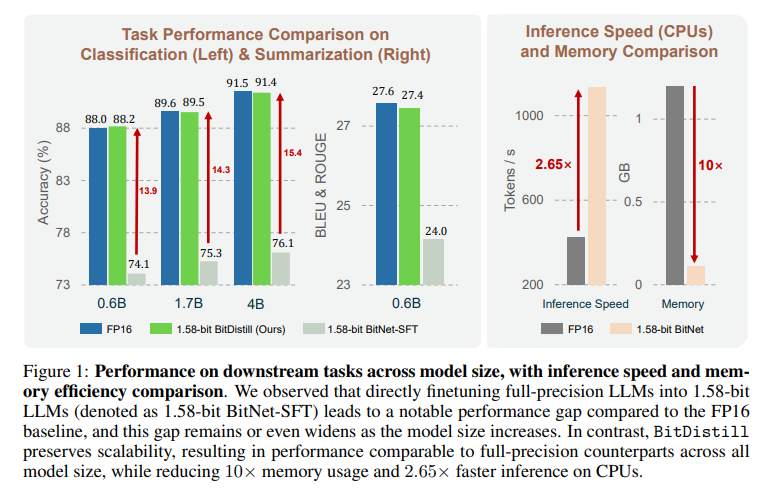
1)精度:在三种规模与两类任务上,BitDistill 的 1.58-bit 学生与 FP16 微调教师的差距通常在统计波动范围内(如 MNLI/QNLI/SST-2 的表 1,CNNDM 的表 2),对比“直接 SFT 的 1.58-bit”有大幅提升,且“随模型变大仍能跟上 FP16”的可扩展性得以保持。
2)效率:CPU 推理吞吐约 2× FP16(示例:427 tokens/s → 1,135 tokens/s),显存/内存约 10× 节省(1.20 GB → 0.11 GB)。
3)普适性:更换为 Gemma、Qwen2.5 等基座仍复现“接近 FP16”的趋势;与 Block-Quant、GPTQ、AWQ 等量化技术组合也能稳健增益。
九、消融与诊断性分析
1)阶段消融:去掉任一阶段(SubLN、继续预训练、注意力/Logits 蒸馏)都会显著掉点,三者互补、全链路最优。
2)蒸馏成分:单用 logits 或单用注意力关系皆有效,但二者并用最稳健。
3)蒸馏层位:单层优于全层,且靠后层最佳——兼顾“对齐能力”与“适配自由度”。
4)教师规模:更强的 FP16 教师能把同规模 1.58-bit 学生进一步“带上去”,甚至在少数设置中超越同尺寸 FP16。
十、实践落地与复现实操建议
1)模块改造:在每层 MHSA out-proj 与 FFN down-proj 前插入 SubLN;保持其余结构不变,便于复用权重。
2)量化策略:权重用 per-tensor absmean 三值化,激活用 per-token 8-bit(absmax/absmean),反传用 STE。
3)继续预训练:抽取 ~10B 通用语料做 LM 训练,epoch 不必多,观察损失稳定与权重分布的“阈值附近聚集”现象。
4)蒸馏微调:与任务监督一起训练;默认 τ=5;分类用 λ=10, γ=1e5,摘要用 λ=1, γ=1e3;从靠后某层挑一层做注意力关系蒸馏,必要时网格搜索该层;若可用更强教师,优先用强教师。
5)评测与部署:CPU 16 线程下可得 2× 吞吐、10× 内存收益;对服务侧推理与边缘设备落地(内存/能耗敏感)尤其友好。
十一、与相关工作的关系
BitDistill 并非与 GPTQ/AWQ 等 PTQ 或其它 QAT 互斥,而是“可叠加”的训练-蒸馏流程;相较“从零训练 BitNet”极大降低了预训练成本;相较仅做 QAT 的直接 SFT,解决了稳定性差与规模放大掉点的问题;相较仅做 logits 蒸馏或层对齐蒸馏,加入“注意力关系蒸馏 + 单层选择”是关键细节。
十二、局限性与潜在改进
1)继续预训练仍需少量通用语料与若干算力,尽管远低于从零训练;2)论文主要验证在中小规模(≤4B)与典型 NLP 任务上,跨模态、长上下文与更大规模(≥7B/13B)的系统性评估仍需补齐;3)当前注意力关系蒸馏的层选择依赖经验/搜索,未来可探索学习式或自适应的层选策略。
十三、结论与启示
BitDistill 给出一条“轻量、稳健、可扩展”的道路:用最小的额外训练(SubLN+少量继续预训练+双重蒸馏)把现成 FP16 LLM 压到 1.58-bit,而且不牺牲任务精度,还能在 CPU/边缘端获得显著吞吐与内存优势。对于追求“任务专用 + 端侧高效”的应用团队,这是当前工程上性价比极高的方案之一。
BitNet on GitHub: https://github.com/microsoft/BitNet