论文REFRAG: Rethinking RAG based Decoding介绍了一种名为 REFRAG (REpresentation For RAG) 的新型高效解码框架,专为检索增强生成 (RAG) 应用设计。简单来说,REFRAG 的目标是解决大型语言模型 (LLMs) 在使用 RAG 处理大量外部知识时遇到的速度慢和内存占用大的问题。在 RAG 应用中,LLMs 会利用检索到的外部信息来增强回答。然而,当这些检索到的信息(即上下文)很长时,会导致系统显著的延迟和巨大的内存需求。
- 延迟问题: 提示(prompt)越长,生成第一个 token 的延迟(Time-to-First-Token, TTFT)就会二次方级增加,而生成后续 token 的延迟(Time-to-Iterative-Token, TTIT)会线性增加。
- 内存问题: 长提示需要额外的 Key-Value (KV) 缓存内存,这与提示长度呈线性关系。
该论文指出,RAG 上下文有一个独特的结构,使其成为优化的理想目标:大部分检索到的段落通常语义相似度较低(可能是由于多样性或去重操作),导致在解码过程中,LLM 对这些上下文的注意力模式呈现出稀疏的、块对角线状的结构。这意味着,在 RAG 解码过程中,对大部分上下文进行的计算是不必要的浪费。
论文作者为Xiaoqiang Lin, Aritra Ghosh, Bryan Kian Hsiang Low, Anshumali Shrivastava, Vijai Mohan,来自Meta Superintelligence Labs, National University of Singapore, Rice University。
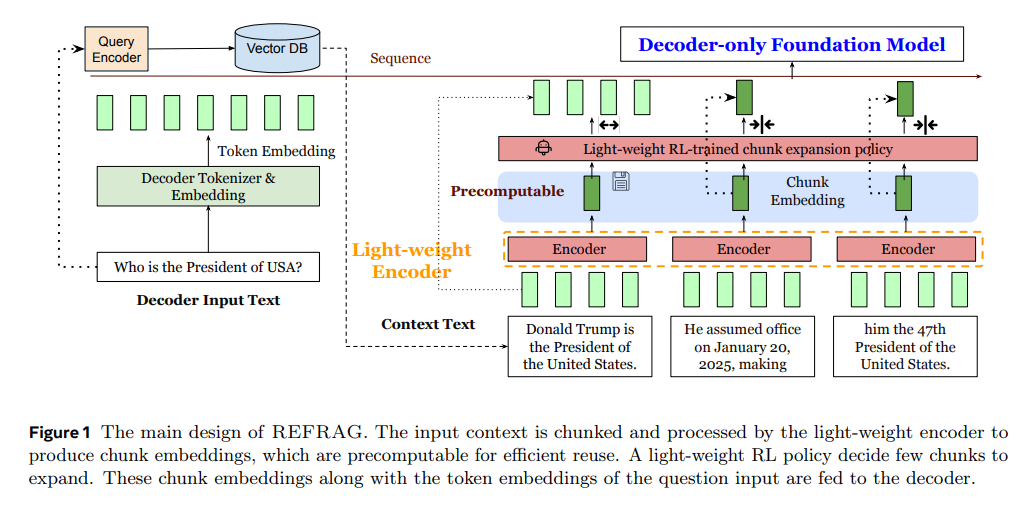
一、核心思想与系统架构:压缩—感知—扩展(compress–sense–expand)
REFRAG的关键做法是:不再把检索到的每个段落按原始token序列喂给解码器,而是先用轻量编码器把每个固定长度的chunk压缩成一个“chunk embedding”,经投影后与问题的token嵌入一起直接输入到原有的解码器中。这样做带来三点收益:①把“解码器输入长度”的度量从“token数”降为“chunk数”,注意力复杂度从按token计缩减为按chunk计;②可重用检索阶段已经可预计算/缓存的chunk表示,避免重复算力;③由于输入序列显著缩短,KV缓存与prefill计算同时降低。更重要的是,REFRAG支持在任意位置进行“按需展开”(保留原始token而非压缩),并用一个轻量RL策略学习“哪些chunk需要以原文token形式保留、哪些用低成本嵌入即可”,从而在保证自回归因果性的前提下实现“随处可压缩、选择性扩展”。
二、训练范式与配方
1)重建任务(Reconstruction)。先冻结解码器,仅训练编码器与投影层:给定前s个token,要求解码器仅凭这些chunk嵌入尽量“重建”原文。这一步把“压缩的语义”与“解码器的token空间”对齐,迫使模型用“外部上下文记忆”而非参数记忆来复原信息。实证表明,没有这一步初始化,后续持续预训练(CPT)很难收敛到足够低的困惑度。
2)课程学习(Curriculum)。从“一个chunk的重建”起步,逐步增加要重建的chunk数与难度,并在数据混合上随训练推进从“简单样本”过渡到“困难样本”。消融显示课程学习对重建任务至关重要。
3)持续预训练(CPT,Next-Paragraph Prediction)。在完成重建对齐后,解冻解码器,令编码器输出辅助解码器预测后续o个token,使“用压缩表征进行生成”与“用原文token生成”的分布尽可能一致。
4)选择性压缩的RL策略。以“下一段预测的困惑度”为负奖励,策略网络根据chunk嵌入与掩码,顺序决策哪些chunk需要“展开”为原始token、哪些保持压缩,从而在既定压缩率下最小化信息损失。实验显示该策略稳定优于基于困惑度的启发式与随机选择。
三、复杂度与系统收益(直觉)
在RAG里,问题token q≪上下文token s,且上下文被分块后,注意力的计算与缓存均按“块数”而不是“token总量”扩展。若每k个token压成1个嵌入,prefill/TTFT的关键路径显著缩短;当上下文很长时,按文中分析,上限可达“接近k或更高阶”的加速。论文报告在中长上下文(如16k级别)下,k=16时TTFT加速超过16×,并随缓存策略变化不同。
四、实验设置与基线
持续预训练以Slimpajama的ArXiv与Books域等长文本为主,评估除自留域外还含PG19与Proof-pile;下游涵盖RAG问答、长文摘要、多轮对话等,基线包括LLaMA-NoContext、Full-Context、LLaMA-32K、CEPE、REPLUG等,统一在LLaMA-2-7B上进行可比性测试。
五、关键结果与量化收益
1)首token时延与吞吐。REFRAG在不牺牲困惑度的情况下,把TTFT加速到30.85×(相对LLaMA),较此前SOTA(如CEPE)再提升约3.75×;压缩率k=32时依然保持与CEPE相当的困惑度。
2)准确性与困惑度。表1显示在s=2048、o∈{512,1024,2048}设置下,REFRAG-8/16在绝大多数任务上优于CEPE与LLaMA截断等基线;同等“解码器token预算”下,REFRAG-8明显胜过仅保留末256 token的LLaMA-256,说明“压缩嵌入”的信息密度更高。
3)超出原生上下文的“有效扩窗”。表2在s∈{4096,8192,16384}, o=2048下评估:REFRAG-8/16在训练仅到6k上下文的前提下,依靠chunk嵌入实现“外推”,在更长上下文仍保持优于CEPE的困惑度。
4)选择性压缩优于固定压缩。用相同“有效压缩率”比较时,基于RL的“按需展开”版本(如REFRAG-16+RL,在目标压缩率≈8时)普遍优于直接训练的REFRAG-8,且优于困惑度启发式或随机策略。
5)端到端RAG性能/延迟等价对比。在强检索器场景下,给定相同检索段数,REFRAG与LLaMA准确率相当;但在“同等延迟预算”(REFRAG可纳入更多段落)时,REFRAG平均提升约1–2个百分点;弱检索器场景下优势更明显,因为能在相同延迟内纳入更多上下文以对冲检索噪声。
6)多轮RAG与长文摘要。REFRAG在多轮对话数据集(TopiOCQA/ORConvQA/QReCC)上,随着轮次与段数增加,相比基于4k上下文的LLaMA微调版更不易“截断历史”,表现更稳;在ArXiv/PubMed长文摘要上,在“相同解码器token预算(同等时延)”下达到最好分数。
六、与相关工作的关系
与CEPE相比:CEPE用交叉注意力接入上下文token嵌入,降低KV开销,但破坏了严格的因果结构,主要适配“前缀上下文”,难以支持“任意位置压缩/展开”的多轮RAG与长文摘要;且CEPE不做token→chunk级压缩,prefill时延降幅有限。REFRAG在“不改解码器架构、不引入新解码器参数”的前提下,以chunk级压缩+按需展开取得更大TTFT收益与更广适用性。
与Prompt压缩(LLMLingua等)互补:提示压缩多基于“删/改token”,而REFRAG以“替代表示”进入解码器,二者可叠加进一步降延。
七、为何“压缩嵌入”不降准?
直觉上,把k个token压成1个向量会损失细节,但RAG上下文的“块对角稀疏”意味着许多跨块交互并不重要;再加上检索与重排本身已提供“与问题对齐”的表征,压缩后仍保留了足够多的可用信号。课程学习与重建任务把“压缩语义”强力对齐到解码token空间,RL再在推理时补上“必须保留原文”的局部,从而在低成本与高质量间取得平衡。
八、局限性与边界
1)压缩率上限:训练曲线显示压到×64开始明显退化,说明“可压缩容量”存在实际边界;×32仍可用,但稳妥区间是×8~×16。
2)编码器规模收益有限:在数据量不大的持续预训练设定下,把RoBERTa从Base换到Large收益并不显著,反而应优先扩大解码器规模(7B→13B)更划算。
3)缓存依赖与工程折中:当不能复用缓存的chunk嵌入时,整体提速仍显著但弱于“带缓存”的上限,部署中需结合实际缓存命中率评估。
九、落地建议(面向工程与产品)
1)在RAG服务侧,把检索阶段的chunk嵌入固化到对象库,并按问题域与时间分片缓存,命中则零开销复用;命中率—延迟—内存三者做A/B权衡。
2)对高价值/高不确定性的chunk启用“RL按需展开”,其余默认压缩;早期可用困惑度启发式近似,后续再以策略学习替换。
3)在弱检索或知识噪声较大的业务上,把“省下的时延预算”转化为“更多检索段数”,通常比精炼少量段落更稳健。
4)多轮/代理型应用优先替换为REFRAG式输入路径,避免因4k上下文上限导致的历史截断。
5)压缩率建议:默认×8起步;若延迟红线更紧张或检索段数多,可试×16并开启“少量关键chunk展开”。×32需结合任务验证,避免质量回退。
十、结论
REFRAG以“用chunk嵌入替代大部分上下文token + 按需展开”的路径,精准命中了RAG的结构性稀疏,显著降低prefill与KV成本。在多种长上下文场景(RAG、多轮对话、长文摘要)上,于不降或提升准确性的前提下,把TTFT加速至30.85×,并把“有效上下文”外推到原生窗口的16×量级,且保持与主流LLaMA系的架构兼容,具备很强的工程可落地性。