当今大模型在处理长文本时,注意力计算随长度二次增长,算力与显存压力巨大。DeepSeek的最新模型DeepSeek-OCR提出用“视觉—文本”通道进行“光学压缩”:把长文本渲染为高分辨率图像,经视觉编码器压成少量“视觉token”,再由解码器还原为文本。作者以端到端OCR为试验台,系统名为 DeepSeek-OCR,核心是轻激活、少视觉token且能高分辨输入的 DeepEncoder,配合 DeepSeek-3B-MoE 解码器。实证表明:在文本token与视觉token之比约≤10×时,OCR解码精度可达≈97%;即使压到≈20×,仍有≈60%精度,显示“以视助文”的长上下文压缩路线可行。该体系在真实文档解析基准 OmniDocBench 上,使用更少视觉token取得与或优于SOTA的表现,并具备图表、化学式、几何图形等“深解析”能力。
论文作者为HaoranWei, Yaofeng Sun, Yukun Li,来自DeepSeek。
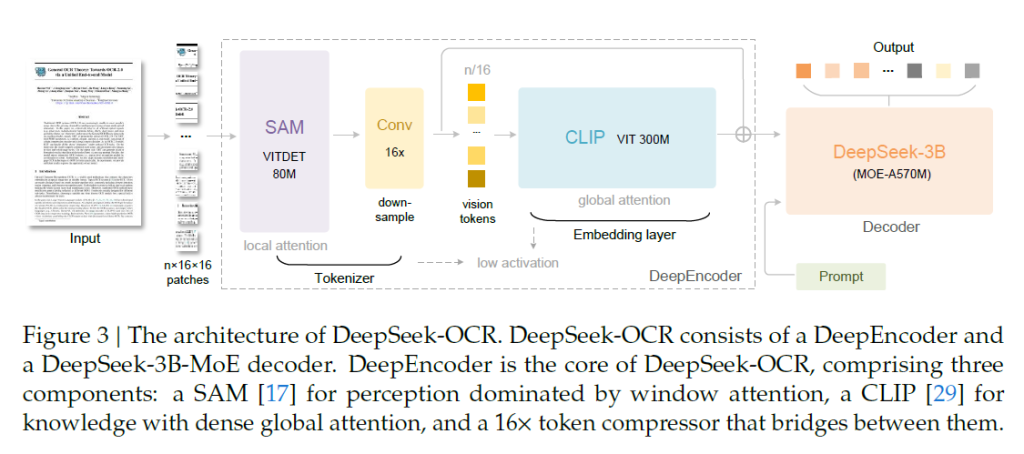
一、整体架构与数据流
系统是典型的“视觉编码器 + 语言解码器”两段式:
1)DeepEncoder:串联两种注意力风格的视觉主干(前半为以窗口注意力为主的 SAM-base,后半为稠密全局注意力的 CLIP-large),中间插入一个“16×卷积压缩器”把视觉token数降为原来的1/16,从而在保持高分辨输入的同时控制激活与token规模。
2)MoE 解码器:采用 DeepSeek-3B-MoE,推理时激活约570M参数(6/64路由专家+2共享专家),以小模型推理成本获得接近3B表达力。
推理时,图像→DeepEncoder(产生少量视觉token)→MoE解码器按提示生成文本或结构化结果。
二、DeepEncoder 的关键设计
1)双段主干的动机:窗口注意力段承担“局部/密集感知”,激活开销小;经16×卷积压缩后,再交给全局注意力段(CLIP-large)做“全局/知识整合”。用1024×1024输入示例:初始patch为4096个token,经压缩为256个,显著降低下游激活与序列长度。
2)16×卷积压缩器:两层卷积(kernel=3, stride=2, padding=1),通道从256→1024;在不牺牲过多可还原性的前提下,直接把token数缩16倍。
3)多分辨与多模式:原生 Tiny/Small/Base/Large 分别对应512²/640²/1024²/1280²输入,输出视觉token为64/100/256/400;为兼顾超高分辨文档,又引入“Gundam”动态分辨率(n块局部tile+1幅全局视图,n∈[2,9]),输出token为 n×100+256(或更大Master模式)。Base/Large采用padding保持纵横比,并给出“有效视觉token”计算公式以反映padding后的有效信息密度。
三、压缩—还原能力的定量结果与边界
作者在 Fox 文档基准的英文600–1300文本token页面上系统测评(100页):
• 当视觉token=64(Tiny,512²)时,文本/视觉≈10.5×时精度≈96.5%;≈15–19.7×时精度降至≈59–86%。
• 当视觉token=100(Small,640²)时,≈6.7–12.6×区间精度≈87–98.5%。
结论:≈10×附近可达“近无损”OCR解码;超过10×后开始“可控退化”,到≈20×仍能保持≈60%文本近似可还原。这为“历史对话转图像→多级降采样”的记忆衰退/遗忘机制提供了经验上限与设计抓手。
四、在 OmniDocBench 上的实用表现
OmniDocBench 综合评估“整体/纯文本/公式/表格/顺序”等维度的编辑距离(越小越好)。DeepSeek-OCR 在视觉token更少的前提下达到或逼近SOTA:
• Small(100 token)已显著优于若干端到端模型;
• Base(256;有效≈182)/Large(400;有效≈285)逼近或对标更大开销模型;
• Gundam(<800 token)整体优于 MinerU2.0(≈6790 token);
• 把原图统一到200dpi的 Gundam-M 可进一步降误差。
此外,不同文档类型对token预算极不均匀:幻灯片只需64 token即有很好效果;书籍/报告在100 token表现优良;报纸因每页文本token常达4–5k,需要 Gundam 或 Gundam-M。实践上据此可按“页内文本密度”与“版式复杂度”自适应分配视觉token预算。
五、“深解析”与多任务能力
除常规“版面+文字”外,模型还能以统一提示对页内子图进行二次解析:
• 图表:转为结构化HTML表格;
• 化学式:渲染识别→SMILES 还原;
• 几何图:以“慢感知”式字典结构输出线段、端点与类型;
• 自然图像:致密描述、目标定位、检测与OCR混合任务。
这些能力来自“OCR 2.0”与“通用视觉数据”的联合训练,虽非通用VLM,但保留了必要的视觉接口,方便扩展。
六、数据引擎与配比
训练数据占比:OCR≈70%、通用视觉≈20%、纯文本≈10%,序列长度统一到8192。
• OCR 1.0:多语PDF(≈30M页,含≈2M中英精标布局+识别交错标注),场景文字(中英各≈10M,PaddleOCR自动标注)。
• OCR 2.0:图表(≈10M,matplotlib/pyecharts渲染→HTML表)、化学式(≈5M,SMILES→RDKit渲染)、几何(≈1M,“翻译不变”增强+慢感知编码)。
这套“粗标+精标+飞轮自举”的数据工程,是端到端OCR可落地与可扩展的关键。
七、训练流水线与工程实现
两阶段训练:
1)先训 DeepEncoder:以紧凑LM做“下一token预测”,在OCR 1.0/2.0与LAION采样数据上训练,2个epoch,batch=1280,AdamW+余弦退火,lr=5e-5,序列长4096。
2)再训整模 DeepSeek-OCR:用PP=4的流水线并行(SAM+压缩器在PP0并冻结;CLIP在PP1可训;MoE的12层在PP2/PP3各6层),20节点×8×A100-40G,DP=40,全局batch=640;多模态日吞吐≈70B token,文本≈90B。Gundam-M 通过在已训模型上继续训练得到。
八、与典型视觉编码方案的对比
• 双塔并行(如Vary系):需要双重预处理、训练并行复杂。
• 平铺切块(如InternVL2系):能上极高分辨率,但原生分辨率低易碎片化、token数膨胀。
• 自适应分辨率(如Qwen-VL/NaViT):灵活但大图激活内存极高,序列打包也拉长训练序列。
DeepEncoder 以“窗口注意力→16×压缩→全局注意力”的串联式折中,既保留高分辨,又把激活与token规模压到“结构合理”的范畴。
九、理论启发:从“光学压缩”到“记忆遗忘”
作者提出把对话历史渲染成图像并随时间下采样:近期高分辨、远期低分辨,配合视觉token预算递减,模拟人类记忆衰退曲线,形成“成本可控、信息随时衰减”的无限上下文框架雏形。当前在≈10×附近接近“无损”,>10×呈“优雅退化”,为分层缓存/回放提供硬指标。
十、局限性与风险点
1)版式/字体极复杂、长页超密时仍需较高token(Gundam家族),吞吐会受限。
2)图像渲染与压缩链路中的“微模糊/锯齿/插值误差”会累积到文本误差,尤其>10×区间。
3)缺少专门的对话级针堆检索(NIH)与数字—光学交替预训练验证;跨域泛化到非文档知识检索场景仍需额外证据。
4)MoE 路由稳定性与部署复杂度在超大规模服务下需更多工程实践。
十一、工程落地建议(给研发与产品团队)
1)自适应token预算:上线时以“页内文本密度估计+版式类别识别”路由到 Tiny/Small/Base/Large/Gundam;报纸、公告、年报等高密文档优先Gundam。
2)提示模板库:统一“Free OCR”“带版面Markdown”“Parse the figure”等模式,按任务自动切换输出协议(纯文、HTML表、SMILES、几何字典)。
3)数据飞轮:把线上解析结果的人审纠错回灌到细标集;图表/几何/化学式持续合成增强,控住长尾。
4)训练/推理编排:保持SAM+压缩器冻结,CLIP端与MoE端按新域小步微调;服务侧以PP+TP混合编排,视觉token上限做弹性配额。
5)评测与回归:除OmniDocBench外,补充按业务场景构造的页级E2E指标(结构还原F1、字段召回、表格单元格ED),并随分辨率/压缩比绘制“代价—质量”曲线。
十二、关键公式与指标解读
1)有效视觉token:当采用padding保持纵横比时,有效token ≈ ⌈实际token × [1 − (max(w,h)−min(w,h))/max(w,h)]⌉,用于估算真正承载内容的token比例。
2)压缩比定义:文本token数 / 视觉token数。建议以“页级文本token估计器”在上线时先估,再给出目标视觉token上限,力争落在≤10×带宽内。
3)编辑距离(ED):用于OmniDocBench整体与子任务(文本/公式/表格/顺序)评估,越小越好,便于跨模型、跨token预算的公平比较。
十三、与同类方法的量化对照摘要
• 相对 GOT-OCR2.0(256 token/页):DeepSeek-OCR 以100 token/页即能在多项指标上超越。
• 相对 MinerU2.0(≈6790 token/页):DeepSeek-OCR 的 Gundam(<800 token/页)整体更优,性价比优势显著。
• 与更大参数通用VLM(InternVL/Qwen-VL/…)相比:在文档解析这一密集文本任务上,专门化视觉编码与token压缩策略带来更好的“质量/成本”平衡。
十四、总结与展望
DeepSeek-OCR 以“窗口注意力→16×卷积压缩→全局注意力”的DeepEncoder,加上高效MoE解码,展示了“视觉承载长文本、≈10×近无损压缩”的可行路径,并在实际文档任务中以更少token达到与或优于SOTA的效果。后续值得推进:数字—光学交替预训练、针堆检索场景验证、跨域知识抽取、以及把“分层分辨率+token配额”落到对话系统的长期记忆管理中,形成可解释、可配置、可度量的“视觉化上下文内存”。
DeepSeek–OCR on GitHub: https://github.com/deepseek-ai/DeepSeek-OCR