论文《VLsI: Verbalized Layers-to-Interactions from Large to Small Vision Language Models》提出了一种新型的视觉语言模型家族——VLsI,针对如何在保持模型性能的前提下实现更高效的视觉-语言模型(VLM)设计。论文提出的VLsI通过创新性地引入自然语言作为中介,实现了从大规模到小规模视觉-语言模型的高效知识迁移,展示了在不增加模型复杂度的情况下保持甚至超越大模型性能的可能性。VLsI模型的逐层蒸馏和逐层对齐方法不仅提高了小模型的推理能力,还展示了自然语言作为知识传递媒介的潜力。这项研究为未来如何通过自然语言来实现AI模型之间的知识迁移提供了新思路,推动了视觉-语言模型在资源受限环境中的实际应用。
论文作者为Byung-Kwan Lee, Ryo Hachiuma, Yu-Chiang Frank Wang, Yong Man Ro, Yueh-Hua Wu,来自Nvidia和KAIST(Korea Advanced Institute of Science and Technology)。
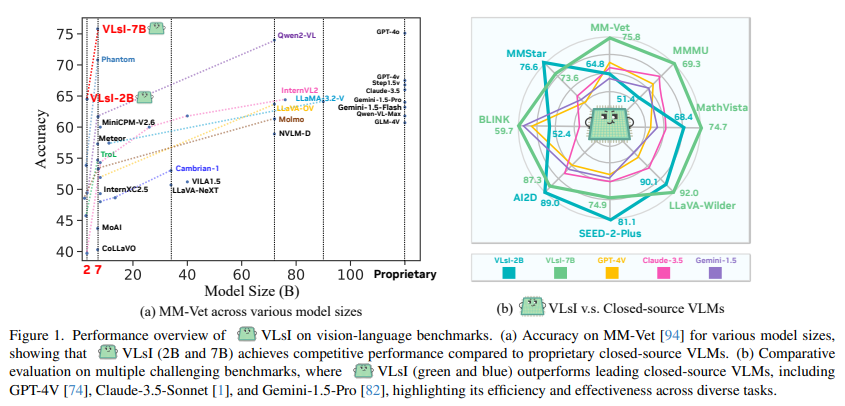
1. 研究背景与动机
近年来,视觉-语言模型(Vision-Language Models, VLMs)的发展极大地增强了视觉系统的解读和处理能力。大型语言模型(LLM)与视觉编码器结合,通过视觉指令调优(Visual Instruction Tuning),实现了对复杂视觉输入的理解。例如,封闭源模型如GPT-4V和Gemini-Pro利用高质量的指令样本,在视觉语言理解任务上取得了前所未有的性能。然而,随着模型规模的扩大,计算成本的急剧增加成为了部署这些模型的主要障碍,尤其是在移动设备和自动化机器人等资源受限的场景中。
传统的解决方案通常涉及添加专门的模块或修改模型架构,这些方法虽然在一定程度上解决了性能问题,但增加了工程复杂度,导致在部署过程中的兼容性问题,特别是在低延迟和内存效率至关重要的场景中。由此可见,现有的方法虽然在理论上提升了模型能力,但在实践中却存在显著的应用障碍。
因此,本文提出了一个关键问题:“如何在不扩大模型规模或进行结构变更的情况下,实现与大模型相似甚至更高的视觉-语言理解性能?”为了解决这一问题,本文提出了一种创新性的逐层蒸馏策略,旨在高效地将大模型中的知识迁移到小模型中,且不损失性能。
2. VLsI 模型概述
论文提出的模型家族名为VLsI(Verbalized Layers-to-Interactions),是一种新型的视觉-语言模型,重点在于通过自然语言为中介进行逐层蒸馏,以实现小模型对大模型推理过程的模仿。该模型在2B和7B两个规模上进行设计和实验验证,分别对应不同的应用场景和资源限制。
与传统的蒸馏方法直接模仿大模型最终输出不同,VLsI引入了一种逐层对齐的过程,通过中间层的语言化表达(即“口述器”),让每一层的输出都能够映射到自然语言空间。这种方法的独特之处在于,每一层的对齐不再仅仅是数值特征的简单映射,而是通过自然语言的描述实现更为直观的特征表达。这种方法不仅能够在逐层的语义空间上实现小模型与大模型的高效对齐,还避免了输出模仿过程中常见的不稳定性问题。
3. VLsI的核心方法与步骤
VLsI的核心方法是逐层蒸馏,分为三个主要步骤:
3.1 Verbalization Step(口述化步骤)
口述化步骤是整个逐层蒸馏的基础。在这一步骤中,每个目标中间层通过引入“口述器”(Verbalizer),将中间特征投射到自然语言空间。具体而言,口述器由一个前馈神经网络(verb-FFN)和语言头(Language Head)组成,用于处理每一层的输出并将其映射为可理解的自然语言文本。这样的设计使得中间层不再仅仅是深度特征的表示,而是可以生成文字描述,帮助小模型理解大模型的推理逻辑。
为了确保这些口述化输出能够正确对齐目标响应,论文采用了自回归损失(Autoregressive Loss),使得每一层的口述化输出与预期的文本相匹配。这一过程通过将中间层的特征变得可解释化,从而使得小模型在逐步学习大模型推理逻辑的过程中能够更好地模仿其行为。
3.2 Interaction Step(交互步骤)
交互步骤是整个逐层对齐的核心,旨在使小模型能够模仿大模型的推理进展。具体来说,小模型的每一层会在大模型中寻找一个对应的层来对齐,这种对齐不仅仅是简单的逐层对应,而是通过一种自适应的层匹配策略动态实现的。论文提出了一种基于KL散度(Kullback-Leibler Divergence)的多项式采样策略,确保小模型每一层所匹配的目标层都是与其推理进展最为相符的。
为了实现这一点,论文提出了一种逐步搜索与自适应匹配的方法。例如,当小模型的第2层与大模型的第4层匹配时,小模型的第3层将在大模型的第5到第7层之间进行搜索。这种逐步对齐的方法确保了推理逻辑的连续性和逐步深入性。
3.3 Reinforcement Step(强化步骤)
在逐层蒸馏完成后,还需要进一步通过强化学习的方法来微调整个小模型,以更好地吸收大模型的知识。强化步骤主要通过自回归损失来增强小模型的任务特定指令跟随能力,从而进一步提高其在具体视觉-语言任务中的表现。这一过程的灵感来源于基于剪枝的蒸馏方法,通过额外的训练来弥补结构变化可能带来的性能下降。强化步骤不仅能够使小模型在结构不变的情况下更好地对齐大模型,还提高了小模型在生成响应时的准确性和一致性。
4. 实验与结果分析
论文在十个具有挑战性的视觉-语言基准测试上验证了VLsI的有效性,展示了显著的性能提升:
- 性能比较:在不增加模型规模或更改架构的情况下,2B和7B规模的VLsI模型相较于GPT-4V分别取得了11.0%和17.4%的性能提升。这样的结果表明,VLsI在保持模型高效性的同时能够达到甚至超越现有的大规模模型。
- 实验设置:实验在八台NVIDIA A100 80GB GPU上进行训练,使用了LoRA(Low-Rank Adaptation of Large Language Models)来优化模型参数,采用AdamW优化器和余弦退火调度来控制学习率。这些技术设置确保了训练过程中的高效性和稳定性。
- 基准测试:在视觉-语言基准如MM-Vet、MMMU、MathVista等测试中,VLsI模型表现出色,尤其在资源受限的情况下,相较于其他开放源模型和封闭源模型都展现了显著的优势。表格1和表格2中展示了VLsI相较于其他模型的具体表现,VLsI模型不仅在模型大小上有优势,其在对视觉和语言的综合理解能力上也表现得更加突出。
5. 口述器与层次对齐策略的效果
论文中展示了VLsI如何通过口述器逐层生成语言化输出,从而追踪各层次的推理进展。图3中举例说明了如何使用口述化的输出来追踪每一层的解读过程,并比较了传统小模型和使用VLsI的模型在推理能力上的差异。浅层次时,两种模型生成的描述大多是对简单形状和颜色的描述,但随着深度增加,VLsI模型能够识别和描述更复杂的视觉结构,最后一层甚至能够准确描述出目标响应,而传统小模型则无法捕捉到这一特定模式。这表明,逐层语言化的蒸馏方法在改善推理的准确性和一致性方面具有明显优势。
6. 层匹配策略的深入分析
在交互步骤中,论文提出了一种新的层匹配策略,利用KL散度来选择每一层的匹配。这种方法通过多项式采样确保了小模型能够尽可能选择最优的匹配层,避免了传统逐层匹配中可能存在的次优选择。论文通过对比不同的匹配策略,证明了KL散度结合逐步匹配的优越性,这样的策略在实验中显示出了显著的性能提升。此外,强化步骤进一步增强了小模型的推理能力,使得它能够更好地对齐并吸收大模型的知识。
7. 限制与未来工作
尽管VLsI在实验中展示了良好的性能,论文也指出了一些局限性:
- 共享分词器:目前,大小模型之间必须共享相同的分词器和词汇索引顺序,这限制了VLsI在某些特定场景中的适用性。未来的研究方向将探索如何在不同的分词器和词汇索引顺序下实现VLsI的通用性。
- 计算资源要求:虽然VLsI减少了模型规模,但在训练阶段仍然需要较大的计算资源,尤其是需要大模型作为骨干来进行逐层对齐。这对资源受限的用户来说仍是一个挑战。