Nvidia这两天发布了MambaVision,即一种新型混合Mamba-Transformer视觉Backbone。针对的MambaVision的研究在论文《MambaVision: A Hybrid Mamba-Transformer Vision Backbone》有具体阐述。
作为一种新型混合Mamba-Transformer视觉Backbone,MambaVision旨在提高视觉任务中的建模能力。论文的核心贡献包括重新设计Mamba模型,以增强其对视觉特征的高效建模能力,并综合研究了Vision Transformer(ViT)与Mamba的集成可行性。研究结果表明,在Mamba架构的最终层中加入若干自注意力块能够显著提升捕获长距离空间依赖性的能力。基于这些发现,提出了MambaVision模型系列,具有分层架构,以满足不同的设计标准。在ImageNet-1K数据集上的图像分类中,MambaVision模型变体在Top-1准确率和图像吞吐量方面达到了新的SOTA(State-of-the-Art)性能。在MS COCO和ADE20K数据集上的目标检测、实例分割和语义分割等下游任务中,MambaVision的表现优于类似规模的主干网络。
论文的内容概要如下:
一、相关工作
- ViT:Vision Transformer利用自注意力层提供了更大的感受野,但初期缺乏CNN的某些优势,如归纳偏置和平移不变性,需要大规模训练数据集来达到竞争性能。
- Mamba:引入了一种新的状态空间模型(SSM),实现了线性时间复杂度,在不同语言建模任务中表现优异,但在计算机视觉任务中效率较低。
二、方法
- 宏观架构:MambaVision的宏观架构包括四个不同的阶段。前两个阶段使用基于CNN的层进行高分辨率特征的快速提取,而第三和第四阶段包括MambaVision和Transformer块。具体来说,输入图像首先转换为重叠的patch,并通过stem投影到嵌入空间中。每个阶段之间的降采样器包括一个3×3的CNN层。
- 微观架构:重新设计了Mamba混合器,替换了因果卷积层,并增加了对称路径以增强全局上下文的建模能力。通过使用选择机制和输入依赖的序列处理来扩展S4公式,Mamba模型能够根据输入动态调整参数B、C和∆。
三、实验
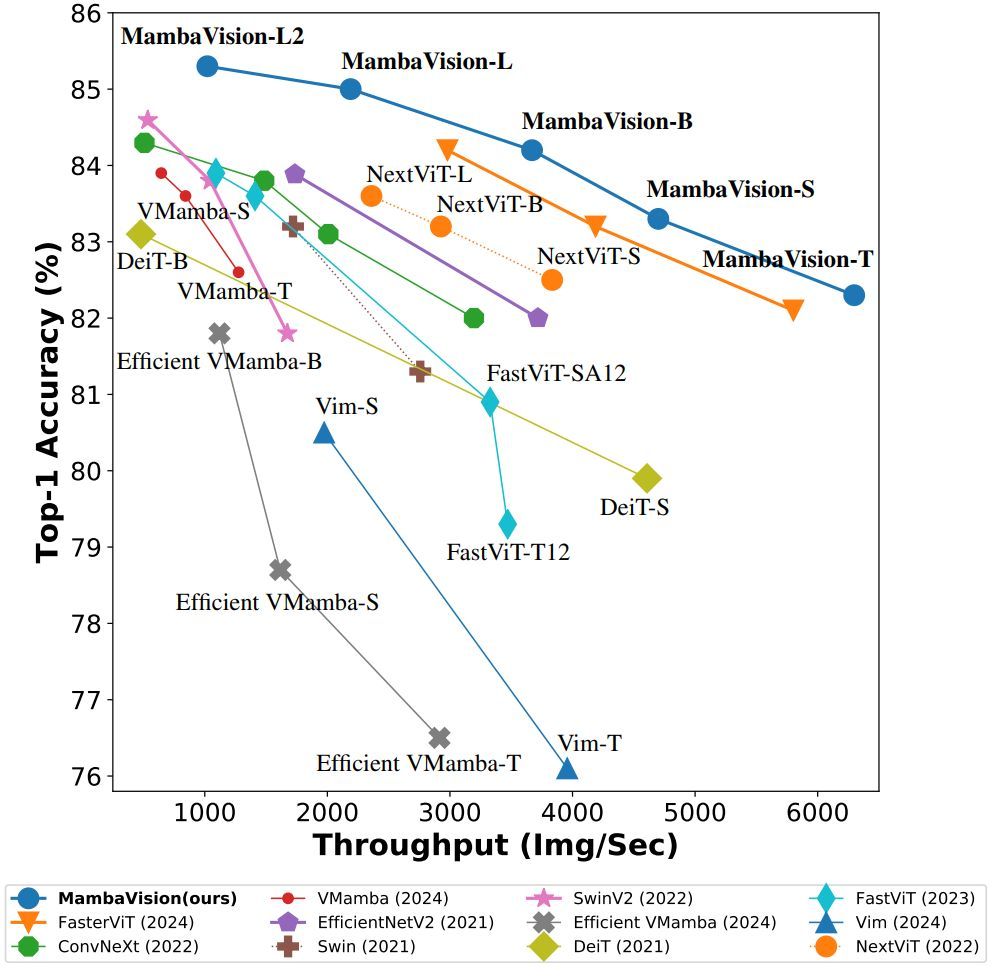
- 图像分类:在ImageNet-1K数据集上的分类结果表明,MambaVision-B在Top-1准确率和图像吞吐量方面都优于ConvNeXt-B和Swin-B等流行模型。
- 目标检测和分割:在MS COCO数据集上的目标检测和实例分割结果显示,MambaVision-T在box AP和mask AP方面优于ConvNeXt-T和Swin-T。Cascade Mask-RCNN网络的结果也表明,MambaVision在各个尺寸的模型中都表现优异。
- 语义分割:在ADE20K数据集上的语义分割基准测试中,MambaVision模型在mIoU方面也优于类似规模的竞争模型。
四、结论
本文介绍了MambaVision,这是第一个专为视觉应用设计的Mamba-Transformer混合主干网络。通过重新设计Mamba公式,增强了全局上下文表示学习能力,并系统地研究了混合设计的集成模式。MambaVision在Top-1准确率和图像吞吐量方面达到了新的SOTA,显著超越了基于Transformer和Mamba的模型。
MambaVision on GitHub: https://github.com/NVlabs/MambaVision