计算机图像和模式识别2024年度大会(Computer Vision and Pattern Recognition 2024 conference, CVPR2024)上,论文“Rich Human Feedback for Text-to-Image Generation”获评最佳论文。论文作者包括 Youwei Liang(加利福尼亚大学圣地亚哥分校)、Junfeng He(Google 研究院)、Gang Li(Google 研究院)、Peizhao Li(布兰代斯大学)、Arseniy Klimovskiy、Nicholas Carolan、Jiao Sun、Jordi Pont-Tuset、Sarah Young、Feng Yang、Junjie Ke、Krishnamurthy Dj Dvijotham、Katherine M. Collins(剑桥大学)、Yiwen Luo、Yang Li、Kai J Kohlhoff、Deepak Ramachandran 和 Vidhya Navalpakkam(以上均隶属于 Google 研究院)。👍👍
Rich Human Feedback for Text-to-Image Generation
论文内容概述如下:
论文摘要:尽管最近的文本生成图像(T2I)模型如 Stable Diffusion 和 Imagen 在根据文本描述生成高分辨率图像方面取得了显著进展,但生成的图像仍存在伪影/不合理性、与文本描述不对齐和美学质量低等问题。受强化学习与人类反馈(RLHF)在大型语言模型中的成功启发,本文提出了通过收集丰富的人类反馈(RHF)来解决这些问题。RHF 包括对生成图像中不合理或不对齐的区域进行详细注释,并收集了 18,000 张图像(RichHF-18K)的此类反馈数据。训练了一个多模态 Transformer 模型来自动预测这些丰富的反馈,可以用于改进 T2I 生成模型。这些改进可以推广到不同的模型,表明反馈机制具有鲁棒性。
一、引言
文本生成图像模型在艺术、设计和广告等创意领域变得越来越重要。尽管取得了进展,生成的图像仍存在伪影、文本不对齐和美学质量低的问题。现有的自动评估指标往往无法捕捉这些细微差别。本文引入了一个数据集(RichHF-18K)和一个多模态 Transformer 模型,提供比单一评分指标(如 IS、FID 和 CLIP-Score)更细致和可解释的评估。
二、相关工作
本文将其贡献放在文本生成图像和评估的广泛背景下,强调了从 GANs 和 VAEs 到扩散模型的发展。批评了现有评估方法的二元性质和缺乏详细反馈,提出了更丰富的反馈机制作为显著改进。
数据收集
RichHF-18K 数据集包括:
- 点注释:标记图像中存在伪影或不对齐的区域。
- 关键词注释:识别文本提示中被误解或缺失的词语。
- 评分:四种细化评分,包括合理性、图文对齐、美学和整体评分。
注释过程涉及每个图像-文本对由三名注释者标注,以确保可靠性,并设计了详细的网络用户界面(UI)以提高数据收集效率和全面性。
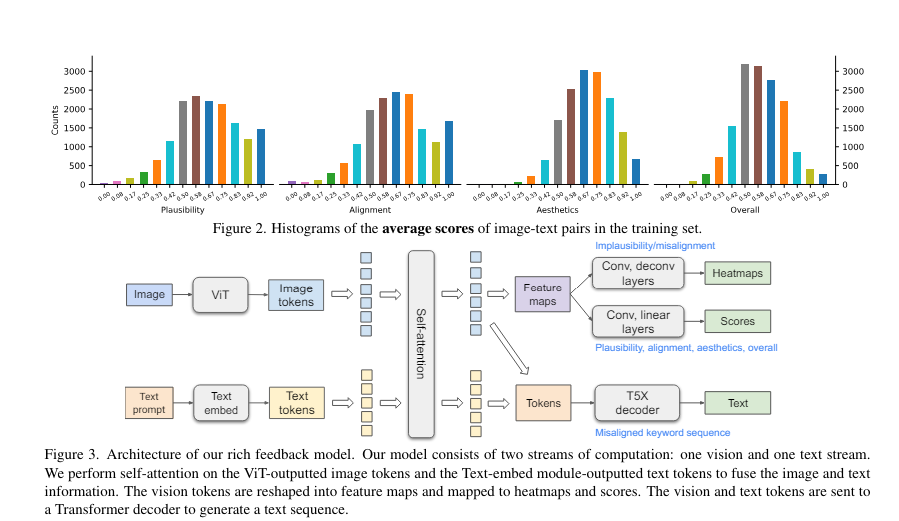
三、模型架构
提出的模型使用了基于 ViT 和 T5X 模型的视觉-语言架构,实现了双向信息传播。这使得模型能够预测不合理和不对齐的区域、错配的关键词以及细化评分,从而提供更详细和可解释的图像质量评估。
四、实验与结果
模型在 16K 个训练样本上训练,并在 RichHF-18K 数据集的 1K 验证和 1K 测试样本上进行评估。评估指标包括皮尔逊线性相关系数(PLCC)和斯皮尔曼秩相关系数(SRCC)用于评分预测,以及各种显著性指标用于热图预测。结果显示,与 ResNet-50 和 CLIP 等基线相比,模型在预测评分和热图方面显著改进。
五、应用
- 改进图像生成:使用预测的热图对问题区域进行修补,并使用评分微调模型(如 Muse)。
- 跨模型泛化:改进能很好地推广到不同的模型,表明反馈机制具有鲁棒性。
六、结论与局限性
本文介绍了一个新颖的文本生成图像丰富人类反馈数据集和模型,展示了在图像质量方面的显著改进。局限性包括对齐注释的挑战和数据集主体的多样性。未来工作将探索更多样化的数据集和丰富人类反馈的额外应用。
七、主要贡献
- RichHF-18K 数据集:一个包含 18K 张图像的详细人类反馈综合数据集。
- 多模态 Transformer 模型:一个预测丰富人类反馈的模型,提高图像生成质量。
- 实际应用:展示了利用丰富反馈增强生成模型的实用性。
八、伦理考虑
数据收集过程已获得机构审查委员会(IRB)的批准,确保在注释和使用数据集方面的伦理标准。
这一详细分析突出了利用丰富人类反馈来解决文本生成图像中持久问题的创新方法,标志着该领域的重要进步。
P.S., RichHF-18K data set on GitHub