论文Octo: An Open-Source Generalist Robot Policy探讨了如何设计和开发一个具备广泛适应性的机器人策略模型,旨在解决传统机器人策略难以泛化的问题。Octo模型由Transformer架构驱动,经过在大规模多机器人操控数据集上的预训练,支持多任务、多传感器输入和多动作空间,能够高效微调并适应新领域的机器人任务。
论文作者为Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, Sergey Levine,均为Octo Model Team团队成员。成员来自UC Berkeley, Stanford University, Carnegie Mellon University和Google Deepmind。
如下为论文概要内容:
1. 引言
传统的机器人学习方法通常需要为每个特定任务和机器人平台从头开始训练,这需要大量的数据采集和计算资源。而且,训练出的策略往往仅能适应狭窄的任务范围,难以泛化到新的任务或环境中。与自然语言处理和计算机视觉中预训练大模型的成功不同,在机器人领域构建“通用策略模型”面临多重挑战,包括处理不同的机器人结构、传感器设置、动作空间、任务规格和环境条件等。
Octo提出的目标是创建一个能够广泛适用于多种机器人操控任务的通用策略模型,具备灵活的输入输出定义,并且能通过少量的领域数据进行高效微调。
2. Octo模型架构
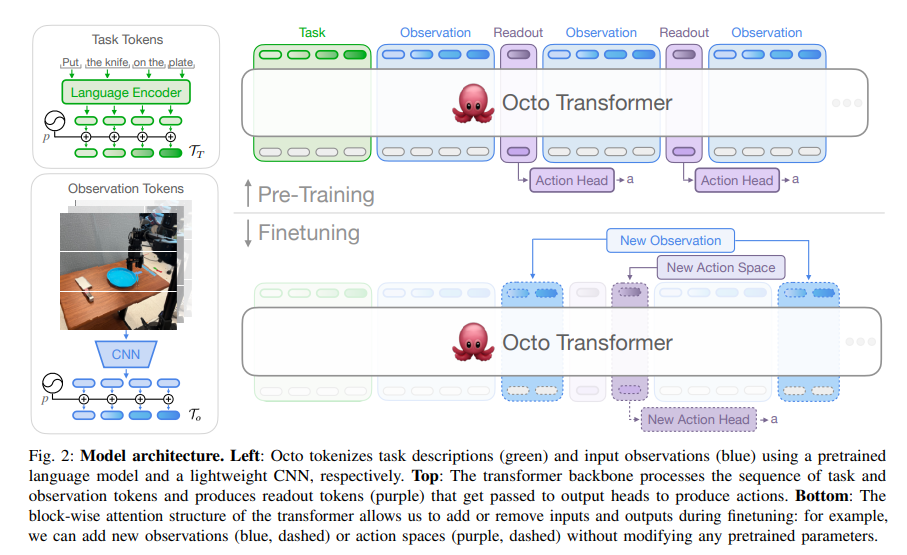
Octo的核心架构是基于Transformer的通用策略模型,模型设计注重灵活性和可扩展性,包括以下三个主要部分:
- 输入Token化器:将任务描述(语言指令或目标图像)和观察(相机图像或其他传感器数据)转化为统一的token序列。
- 语言输入通过预训练的T5模型(111M参数)进行编码。
- 图像输入通过浅卷积网络编码为token。
- Transformer主干网络:处理这些token并生成嵌入向量。Octo的Transformer结构采用了块状的自注意力机制,允许不同时间步的token之间按顺序进行交互。这种模块化设计使得可以在微调过程中增加或移除观察和任务输入。
- 输出头:每个任务或观察序列的token会传递给“读取token”,这些token只被动读取嵌入信息,并通过输出头生成动作。这种设计允许我们在微调过程中灵活添加新的任务或观察输入,而不需要重新训练整个模型。
Octo的架构设计是为了在处理多种不同机器人平台、传感器输入以及任务定义时具有灵活性。这种模块化结构允许用户通过增加新适配器,在微调过程中处理新的观察和动作空间,从而提升策略模型的适应性。
3. 预训练数据
Octo模型预训练基于Open X-Embodiment数据集,这是一个包含150万机器人操作轨迹的庞大数据集。Octo使用了其中80万条机器人示范数据,覆盖了多种机器人任务和环境。该数据集包括:
- 多种不同的机器人类型和任务场景;
- 各种传感器配置(如手腕相机和第三人称相机);
- 丰富的任务标签,包括语言指令和目标图像。
在数据采样方面,论文采用了加权采样方法,优先选择数据多样性较高的任务和场景,同时避免过度重复的任务对训练产生偏差。此外,为了使不同的数据集之间的动作空间保持一致,研究团队对抓手动作进行了标准化处理。
4. 训练目标与优化方法
Octo采用了条件扩散解码头来预测连续的、多模态的动作分布。具体来说,模型的动作预测通过扩散过程完成,每一步生成高斯噪声向量,经过多次去噪后得到最终的动作预测。扩散过程的主要步骤如下:
- 初始输入噪声向量;
- 通过条件化网络逐步去噪,生成准确的动作序列。
与均方误差(MSE)或离散化动作分布的预测方法相比,扩散解码能够更好地捕捉多模态动作分布,提高策略的精度和灵活性。训练过程中使用了标准的DDPM(去噪扩散概率模型)目标函数,这种方法对处理复杂、多模态的机器人任务非常有效。
5. 实验设计与评估
Octo在9个不同的机器人平台上进行了广泛的实验,涵盖了多种不同的任务和场景。实验包括两类评估:
- 零样本评估:在不经过微调的情况下,直接在新的机器人任务上执行,测试模型的泛化能力。
- 微调评估:通过少量的领域内数据对模型进行微调,测试其在新观察空间和动作空间上的适应能力。
在零样本评估中,Octo模型在多个机器人任务上展现了比RT-1-X和RT-2-X(两个现有的机器人策略模型)更高的成功率。特别是在语言指令和目标图像驱动的任务中,Octo能够表现出更强的泛化能力。此外,在多个双臂操作任务中,Octo的表现也优于其他模型。
在微调评估中,Octo能够在少量示范数据(约100条)的情况下,快速适应新的任务环境和机器人平台。实验表明,Octo通过微调能够显著提高任务成功率,尤其是在引入新传感器输入(如力矩传感器)和新的动作空间(如关节位置控制)时表现尤为突出。
6. 消融研究
为了验证Octo设计中的关键因素,论文进行了多项消融实验,研究了模型架构、训练数据和训练目标对最终性能的影响。以下是消融研究的主要发现:
- 模型架构:与传统的ResNet+Transformer架构相比,Octo采用的Transformer-first架构在大规模数据集上的表现更优,特别是在视觉任务中展示了更好的泛化能力。
- 训练数据:Octo在25个数据集的组合上进行训练,实验表明,数据的多样性对于模型的性能提升至关重要。
- 训练目标:扩散解码相比于MSE和离散化动作预测,能够更有效地处理复杂的机器人任务,特别是在多模态动作预测方面具有显著优势。
7. 结论与未来工作
Octo的设计和实现代表了构建通用机器人策略模型的一大进展,能够在多种机器人平台和任务中广泛应用。论文指出未来研究的几个方向,包括改进对手腕相机信息的处理、增强语言指令的理解能力,以及在更多种类的机器人平台上扩展Octo的应用。此外,扩展用于训练的数据集,加入次优数据或在线交互数据,也将有助于进一步提升模型的泛化能力。
Octo Page: https://octo-models.github.io/
Octo on GitHub: https://github.com/octo-models/octo