论文VisRAG: Vision-based Retrieval-Augmented Generation on Multi-Modality Documents主要探讨了一个名为VisRAG的新型检索增强生成(RAG)管道,旨在解决传统RAG仅基于文本的局限性,无法有效利用文档中的视觉信息(如布局和图片)。通过引入视觉语言模型(VLM),VisRAG能够直接以视觉形式嵌入整个文档,从而保留原始文档中的所有信息,避免文本解析过程中引入的信息损失。
论文作者为Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, Maosong Sun,来自Tsinghua University(清华大学),ModelBest Inc.(面壁智能),Rice University和Northeastern University。
以下为论文内容介绍:
1. 背景与研究动机
1.1 检索增强生成(RAG)的限制
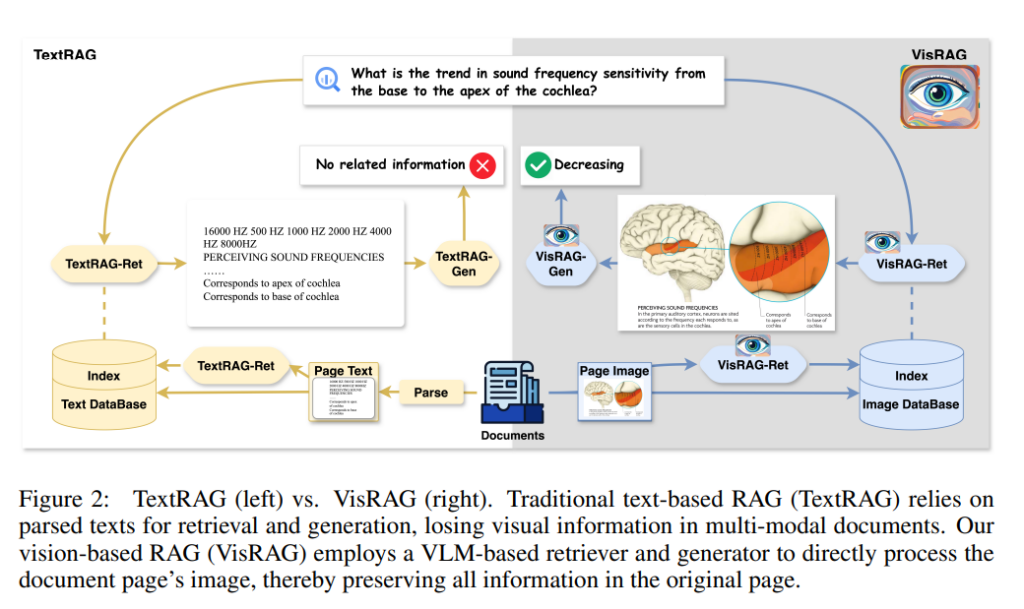
传统的RAG系统(如TextRAG)广泛应用于文本领域,其主要思想是通过检索外部知识库中的信息来增强大型语言模型(LLMs)的生成能力。这些系统在处理纯文本知识时表现良好,尤其是在针对像Wikipedia这样经过整理和清洗的纯文本数据时。然而,在现实场景中,知识常常以多模态形式呈现,例如书籍、手册、图表等,这些文档不仅包含文本,还包括布局、图像、表格和图表等其他视觉元素。
1.2 多模态信息的挑战
在多模态文档处理中,传统RAG系统面临信息丢失的问题。例如,文档解析需要使用布局识别、光学字符识别(OCR)等步骤,这些步骤容易引入错误和噪声,从而影响检索与生成的质量。此外,这些解析过程只能提取文本信息,而无法有效利用文档的视觉元素,这些元素对理解文档上下文有至关重要的作用。
1.3 VisRAG的提出
为了解决这些问题,论文提出了一种名为VisRAG(Vision-based Retrieval-Augmented Generation)的新型管道。VisRAG利用视觉语言模型(VLM)直接对文档的图像进行检索和生成,无需文本解析过程,从而最大化保留文档中的原始信息。VisRAG通过直接将文档嵌入为视觉形式,并利用这些嵌入进行检索和生成,使其在处理多模态文档时,表现出更好的性能和鲁棒性。
2. VisRAG的系统框架与方法细节
VisRAG系统由两大核心组件构成:VisRAG-Ret(用于检索)和VisRAG-Gen(用于生成),两者均基于视觉语言模型。
2.1 VisRAG-Ret:基于视觉语言模型的检索
2.1.1 双编码器结构
VisRAG-Ret采用了与文本检索相似的双编码器结构,但与传统的文本编码器不同,VisRAG-Ret使用VLM对查询和文档直接进行视觉编码。该模型首先将查询编码为文本嵌入,将文档图像编码为视觉嵌入。然后,通过加权均值池化(weighted mean pooling)对最终层的VLM隐状态进行处理,以生成用于检索的嵌入。加权的方式是根据位置赋予后续token更高的权重,这样能够更好地捕捉视觉和文本的相关性。
2.1.2 优化目标
VisRAG-Ret通过信息对比损失(InfoNCE loss)进行训练,用于最大化查询与正样本文档之间的相似性,最小化与负样本之间的相似性。具体的损失函数如下:
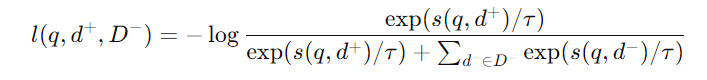
其中,d+表示正样本文档,D−为负样本文档集,s(q,d)为查询和文档之间的相似度得分,τ为温度参数,用于调整对比度。
2.2 VisRAG-Gen:基于视觉语言模型的生成
VisRAG-Gen的目标是在给定查询和检索到的文档的情况下,生成正确的答案。VisRAG-Gen可以处理单幅图像输入和多幅图像输入,具体策略包括以下几种:
2.2.1 页面拼接(Page Concatenation)
对于只能接受单幅图像输入的视觉语言模型(如MiniCPM-V 2.0),VisRAG-Gen通过将多页文档进行水平拼接的方式,将它们合并为一幅图像进行输入。
2.2.2 加权选择(Weighted Selection)
对于多个检索到的文档,VisRAG-Gen还采用加权选择的策略,即对每一页生成一个答案,然后基于生成的置信度来选择最终答案。生成置信度通过生成概率与检索得分的加权计算得到,公式如下:
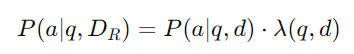
其中,P(a∣q,d)是生成答案的概率,λ(q,d)是检索得分的归一化权重。
2.2.3 多图像输入的VLM
对于能够接受多幅图像输入的模型(如MiniCPM-V 2.6和GPT-4o),VisRAG-Gen直接将多个检索到的文档输入模型,这样可以进行跨页面的推理,特别是在需要多跳(multi-hop)推理的情境中。
3. 数据构建与实验设置
3.1 数据集构建
为了评估VisRAG在多模态文档中的表现,论文构建了一个包含多种视觉问答(VQA)数据集和合成数据的综合数据集。这些数据集包括:
- MP-DocVQA:用于工业文档的问答。
- ArXivQA、ChartQA、InfographicsVQA、PlotQA:分别用于科学文献图表、图表、信息图和科学图表的问答。
- SlideVQA:用于演示文稿幻灯片的问答。
3.2 查询过滤
为了保证检索的有效性,VisRAG对从VQA数据集中提取的查询进行了过滤,去除了那些依赖上下文且缺乏明确指向性的查询(如“会议在哪里举行?”这类问题)。通过过滤,保留了那些具有较强文档特异性的查询,以便更有效地进行开放检索任务。
3.3 实验设置
论文设计了多组实验来验证VisRAG在检索和生成中的性能。实验分为三类设置:
- Off-the-shelf模型:直接测试现有的文本和视觉检索模型的性能。
- Out-of-domain设置:模型仅在合成数据上进行训练,评估其在VQA数据集上的泛化能力。
- In-domain设置:模型在VQA数据集和合成数据上进行联合训练,以评估其在域内监督条件下的性能。
4. 实验结果与分析
4.1 检索性能
VisRAG-Ret在检索性能上显著优于传统的文本和视觉检索模型。在Out-of-domain的情况下,VisRAG-Ret超过了现有的最先进文本检索模型NV-Embed-v2,尽管后者使用了更多的数据进行训练。这表明VisRAG-Ret具有很强的泛化能力,特别是在处理未见过的多模态数据时,表现出色。
4.2 生成性能
VisRAG-Gen在生成阶段同样表现优异。通过直接处理文档图像,VisRAG-Gen相比传统的基于文本的生成器,如MiniCPM(OCR)和GPT-4o(OCR),表现出更高的准确率。在处理包含多幅图像的场景下,多图像输入的VLM(如GPT-4o)表现出了随检索到的文档数量增加而性能提升的趋势,这表明这些模型在多页面推理上具有潜力。
4.3 端到端性能
在端到端的性能比较中,VisRAG相比TextRAG实现了大幅提升。在检索阶段,VisRAG-Ret的表现明显优于TextRAG的检索器,而在生成阶段,VisRAG-Gen能够更好地利用检索到的文档信息,显著提高了最终的问答准确率。特别是在InfographicsVQA数据集上的测试中,VisRAG的整体性能较TextRAG提升了接近两倍。
5. 未来工作与挑战
论文还讨论了VisRAG未来的发展方向,包括:
- 提高多页面推理能力:当前的多图像推理能力虽然已经有显著提升,但仍存在进一步优化的空间,特别是在处理需要复杂跨页面逻辑推理的问题时。
- 扩展数据集规模:为了进一步验证VisRAG的泛化能力和鲁棒性,未来需要在更大规模的数据集上进行实验。
VisRAG on GitHub: https://github.com/openbmb/visrag