论文MetaMorph: Multimodal Understanding and Generation via Instruction Tuning提出了一种新的微调框架——Visual-Predictive Instruction Tuning (VPiT),并构建多模态模型 MetaMorph,实现视觉理解和生成的统一。
论文作者为Shengbang Tong, David Fan, Jiachen Zhu, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, Zhuang Liu,均来自Meta。杨立昆(Yann LeGun)教授也是论文作者之一。
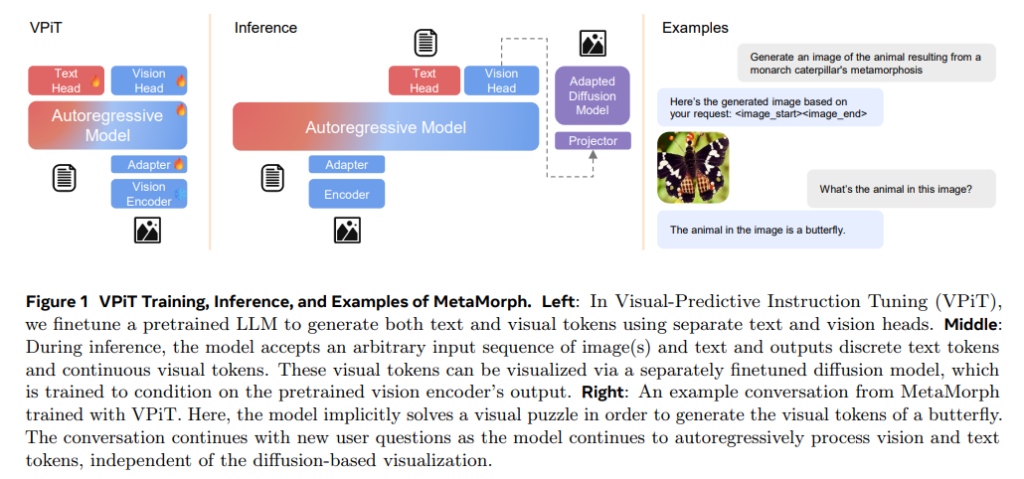
1. 背景与研究动机
1.1 多模态模型的现状
多模态大型语言模型(MLLMs)的发展,使得机器能够同时理解和处理图像与文本。然而,当前模型大多局限于单一任务(如图像理解或生成),且实现这些任务通常需要大规模的数据训练和复杂的模型架构调整。以往的研究表明:
- 视觉理解任务,如图像问答(ImageQA),通过视觉编码器将图像嵌入到语言模型中,可以高效地实现。
- 视觉生成任务则通常被认为是独立于理解的,需要额外的生成模块,如扩散模型(Diffusion Models)。
1.2 存在的问题
- 生成与理解割裂:现有方法中,视觉生成和理解通常被分开处理,这限制了模型的多任务能力。
- 高成本需求:视觉生成任务通常需要大量的数据和计算资源。
- 架构复杂性:实现多模态能力的模型设计往往需要在现有架构上引入大量调整,增加了实现难度。
1.3 研究目标
作者提出的主要目标是:
- 通过轻量级微调(VPiT),在预训练语言模型的基础上实现统一的视觉理解与生成能力。
- 探讨视觉生成和理解任务之间的协同关系,揭示两者的潜在互补性。
- 通过联合多模态数据训练一个模型,实现视觉生成任务所需的数据效率提升。
2. 研究方法
2.1 VPiT(Visual-Predictive Instruction Tuning)
核心思想
通过扩展视觉指令微调(Visual Instruction Tuning),实现统一的视觉理解与生成。具体步骤包括:
- 从单模态到多模态的预测任务:
- 输入扩展为图像和文本的混合序列。
- 输出既包括离散的文本令牌,也包括连续的视觉令牌。
- 多模态数据的令牌化:
- 文本数据通过语言模型的标准令牌器进行离散化。
- 图像数据通过预训练视觉编码器(如 SigLIP)转换为连续视觉令牌,并通过投影层调整维度以适配语言模型。
- 模型架构:
- 在预训练语言模型的基础上增加“视觉头”,用于预测视觉令牌。
- 引入特殊令牌
<image_start>和<image_end>以标识视觉令牌序列。
- 损失函数:
- 文本生成任务采用标准的交叉熵损失。
- 视觉生成任务采用余弦相似性损失,最大化模型预测的视觉令牌与视觉编码器生成的嵌入之间的相似度。
- 令牌可视化:
- 使用扩展的扩散模型将预测的视觉令牌映射回像素空间,实现视觉生成。
2.2 数据类型与处理
VPiT 支持多种类型的多模态数据,涵盖视觉理解和生成任务,具体包括:
- 视觉理解数据:
- 图像问答(ImageQA):例如 Cambrian-7M 数据集,提供图像和对应的问题-回答对。
- 视频问答(VideoQA):如 VideoStar 数据集,输入为视频帧和文本问题。
- 视觉生成数据:
- 通过描述生成图像,如 MetaCLIP 数据集,输入为文本描述,输出为视觉令牌。
- 混合视觉数据:
- 视频预测:根据部分视频帧预测未来帧。
- 图像推理:通过输入图像生成变换后的图像(如 InstructPix2Pix 数据集)。
2.3 可视化视觉令牌
通过一个微调的扩散模型(如 Stable Diffusion),将连续视觉令牌映射为像素数据。此过程需要:
- 使用预训练的扩散模型。
- 引入一个两层的多层感知机(MLP)投影器,用于将视觉令牌维度调整为扩散模型的条件输入维度。
3. 实验设计与结果分析
3.1 实验问题
- 视觉生成能否通过轻量级微调实现?
- 视觉理解与生成任务是否相互补充?
- 增加不同数据类型对模型性能的具体贡献如何?
3.2 实验发现
发现1:视觉生成能力通过联合训练高效解锁
- 单独训练视觉生成任务时,模型需要超过 300 万条数据才能实现较高质量生成。
- 联合训练视觉理解和生成任务后,仅需 20 万条生成数据即可达到相似的性能。这表明视觉生成并非独立能力,而是与视觉理解高度相关。
发现2:理解与生成任务的协同效应
- 增加视觉理解数据(如 VQA 数据)可以显著提升生成质量。
- 增加视觉生成数据也能提升理解任务(如 VQA)的性能,但效果不如增加理解数据显著。
发现3:视觉理解数据贡献更大
通过对不同类型数据的对比实验发现:
- 视觉理解数据(如 ImageQA 和 VideoQA)对生成任务的提升最显著。
- 视觉生成数据的贡献较小,尤其是在理解数据较多的情况下。
发现4:特定任务的贡献差异
- 一般性任务(如高分辨率图像问答)与生成任务的相关性较强。
- 知识密集型任务(如科学问答)的贡献较低,说明生成任务更依赖于视觉内容的直接理解。
3.3 定量结果
在多个基准任务上,MetaMorph 的表现优于现有方法,包括:
- 在视觉理解任务(如 ImageQA)上,与 GPT-4V 等先进模型表现相当。
- 在视觉生成任务上,超过部分专用生成模型(如 Stable Diffusion)。
4. 模型能力展示
4.1 利用 LLM 的知识生成视觉内容
MetaMorph 能够利用预训练语言模型的知识生成复杂的视觉概念,例如:
- 生成“Chhogori”(乔戈里峰,世界第二高峰)的图像。
- 生成“Oncilla”(南美小野猫)等特定领域知识相关的图像。
4.2 隐式多步推理
通过隐式完成多步逻辑推理,MetaMorph 能够直接生成正确的视觉内容。例如:
- 输入“生成科学家爱因斯坦喜欢演奏的乐器”,模型推理出答案为小提琴并生成对应的图像。
5. 意义与未来展望
5.1 意义
- 统一能力:通过简单的微调,MetaMorph 实现了视觉理解与生成的统一。
- 数据效率:联合训练显著减少了视觉生成任务对大规模数据的依赖。
- 潜在能力激活:实验表明,预训练的语言模型中已存在“隐性”的视觉生成能力,通过 VPiT 可以高效激活。
5.2 未来方向
- 探索更多多模态数据类型,进一步提升模型的统一能力。
- 优化微调技术,使其适配更多任务场景,推动通用人工智能的发展。
Metamorph项目主页: tsb0601.github.io/metamorph