论文TextGrad: Automatic “Differentiation” via Text提出了TextGrad框架,该框架以“文本反馈反向传播”为核心,模拟自动微分的思想对AI复合系统进行系统性优化。该方法不仅在多个领域取得领先性能,更展示了LLM结合优化理论在科研、工程与医学中的强大潜力。
论文作者为Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, James Zou,来自STANFORD UNIVERSITY和CHAN ZUCKERBERG BIOHUB。
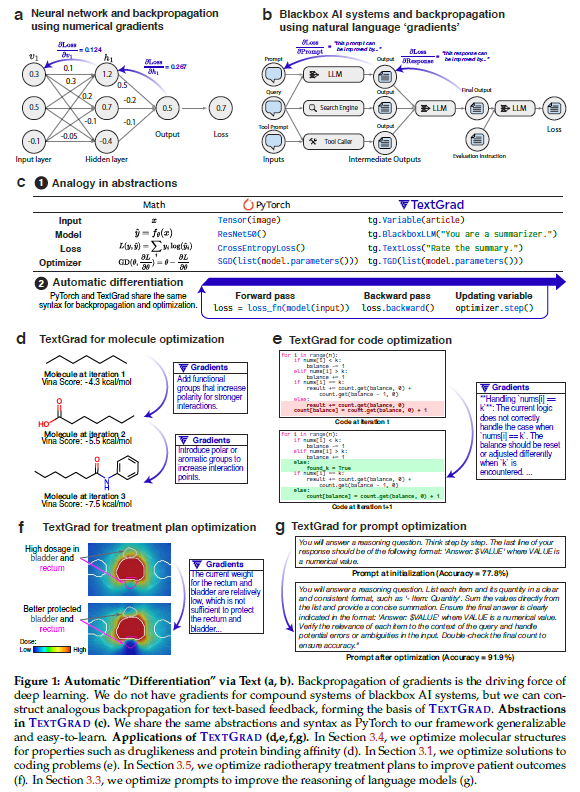
一、引言
当前人工智能(AI)系统正经历范式转变。以大型语言模型(LLM)为核心的系统日益成为复合型AI系统的基石,典型例子包括结合符号推理器、搜索引擎、代码解释器等模块的系统。这类系统通常依赖专家手工调优,使得其开发效率低、可迁移性差。因此,迫切需要一种通用、可自动化的优化框架来提升这类系统的性能。
神经网络在早期也面临类似的困境,直到反向传播(backpropagation)与自动微分(automatic differentiation)技术的出现,实现了对模型参数的系统化优化,彻底改变了AI的发展轨迹。借鉴这一理念,本文提出了创新优化框架——TextGrad。它以“文本反馈”作为“梯度”的类比,从LLM中获得自然语言建议来优化系统中的各个组件。
TextGrad以计算图的形式建模复杂AI系统,并将自然语言反馈作为变量的“文本梯度”传播给相关组件。其适用于多种输入形式,如代码、分子结构、提示词等。该框架不仅保持了与PyTorch类似的语法和抽象结构,使其易于上手和扩展,还在无需人工调整提示或组件的前提下,适用于各种应用场景,具有极强的通用性和实用性。
二、TextGrad框架设计:通过文本反馈进行反向传播优化
TextGrad的核心理念是模拟自动微分中的链式法则,将LLM生成的文本反馈作为梯度,反向传播至各个可优化变量。
- 框架示例(双LLM调用的系统):
考虑一个由两个LLM调用组成的简单计算图:
- 第一步:生成回答
Prediction = LLM(Prompt + Question) - 第二步:评估回答
Evaluation = LLM(Evaluation Instruction + Prediction)
为了优化Prompt,我们首先获取Prediction对Evaluation的影响(即∂Evaluation/∂Prediction),然后再推导Prompt的更新方向(∂Evaluation/∂Prompt)。
在TextGrad中,这些“梯度”通过LLM输出的自然语言反馈获得。例如,“这段代码可以通过处理X问题来改进……”等。
- 文本梯度的获取:
使用一个抽象的梯度算子 ∇LLM(x, y, ∂L/∂y),通过如下提示模板调用LLM获得反馈:
“Here is a conversation with an LLM: {x|y}. Below are the criticisms on {y}: {∂L/∂y}. Explain how to improve {x}.”
- 文本梯度下降(Textual Gradient Descent, TGD):
类似于传统的SGD更新策略:
x_new = x - ∂L/∂x
TextGrad中通过如下LLM调用实现:
“Below are the criticisms on {x}: {∂L/∂x}. Incorporate the criticisms, and produce a new variable.”
- 任意复杂图结构的通用化:
对任意计算图变量 v,梯度通过其所有后继节点 w 聚合得到:
∂L/∂v = ⋃_w∈Successors(v) ∇f(v, w, ∂L/∂w)
变量的更新则统一由TGD.step完成。
- 目标函数的多样性:
TextGrad中的目标函数不仅限于传统的数值损失,还可以由LLM根据自然语言生成。例如:
Loss(code, goal) = LLM("Here is a code snippet: {code}. Here is the goal: {goal}. Evaluate its correctness and runtime complexity.")
- 两类优化任务:
- 实例优化(Instance Optimization):直接优化代码、分子等实例对象。
- 提示优化(Prompt Optimization):优化系统提示以提升模型泛化性能。
- 批量优化与其他技术:
TextGrad支持类似PyTorch的minibatch优化、自然语言约束优化(constrained optimization)、以及带动量的更新策略等。
三、实验结果
TextGrad在五大任务中展现了其卓越的通用性与性能提升能力。
- 编程代码优化(LeetCode Hard)
- 任务:优化LLM生成的代码,使其通过LeetCode平台的隐藏测试用例。
- 数据集:LeetCode Hard。
- 基线方法:Reflexion(通过自反思改进代码)。
- 结果:gpt-4o 零样本为26%,Reflexion提升至31%,TextGrad无示例优化达到36%,提升显著。
- 科学问题解答优化(Google-Proof QA & MMLU)
- 任务:通过LLM自我评估反复修正科学领域多选题的答案。
- 方法:gpt-4o生成初始回答,通过TextGrad迭代三次优化答案。
- 结果:GPQA准确率从51%提升到55%;MMLU的机器学习和物理子集准确率分别从85.7%提升到88.4%,91.2%提升到95.1%。
- 推理任务中的提示优化
- 目标:提升gpt-3.5-turbo在Object Counting、Word Sorting和GSM8k任务上的性能。
- 方法:用gpt-4o提供梯度反馈,通过TGD优化系统提示。
- 结果:在Object Counting任务中从77.8%提升至91.9%;其他两个任务提升至与DSPy持平(81.1%)。
- 分子结构优化(药物设计)
- 目标:同时优化分子的结合亲和力(Vina Score)与药物相容性(QED)。
- 方法:使用SMILES字符串表示分子,每步由LLM给出修改建议,结合Autodock Vina与RDKit计算指标。
- 结果:在58个药物靶标上均获得持续提升。生成的分子在结合亲和力和QED指标上优于临床药物,并具有新颖结构和合理几何构象。
- 放射治疗计划优化(医学应用)
- 任务:优化前列腺癌患者放疗剂量计划中的权重超参数,以同时保证肿瘤照射充分与健康组织保护。
- 方法:将超参数转化为文本变量,通过LLM对matRad生成的治疗计划进行评估并优化。
- 结果:优化后的计划在PTV剂量达标方面优于临床计划,同时显著降低了膀胱和直肠的辐射剂量。
四、相关工作
本研究在多个维度上继承并扩展了前人的探索:
- DSPy 框架强调将LLM系统程序化构建和优化;
- ProTeGi 提出“文本梯度”用于提示优化;
- Reflexion、Self-Refine 等方法利用自反馈进行解答改进;
- 本文将“自动微分”类比机制推广到更多实例和任务,统一建模方式与优化接口。
此外,TextGrad还融合了经典优化理论中的多项技术,如动量、约束优化、批量更新等,使得该框架不仅通用且易于扩展。
五、讨论与展望
TextGrad具有如下优势:
- 通用性强:不仅限于提示优化,可用于优化任意LLM系统中的变量;
- 易于使用:高度类PyTorch抽象设计,学习曲线低;
- 完全开源:可复现与二次开发。
未来工作方向包括:
- 将计算图扩展至更多组件(如工具使用、RAG等);
- 引入更复杂的优化算法(如自适应梯度、方差约束、元学习);
- 在科学与工程等领域实现端到端实验验证,如化学合成与临床计划。
TextGrad on GitHub: https://github.com/zou-group/textgrad