一、研究背景与动机
生成式人工智能(Generative AI)近年来在图像合成、自然语言处理、分子设计等多个领域取得显著进展,例如GAN、VAE、Diffusion Model 和 LLM 等模型。随着这些模型规模不断扩大,其在推理阶段的能耗、延迟和计算资源需求也急剧上升,限制了其在边缘计算或低功耗设备中的应用。因此,研究人员亟需开发一种兼具可扩展性和高能效的生成式模型替代方案。
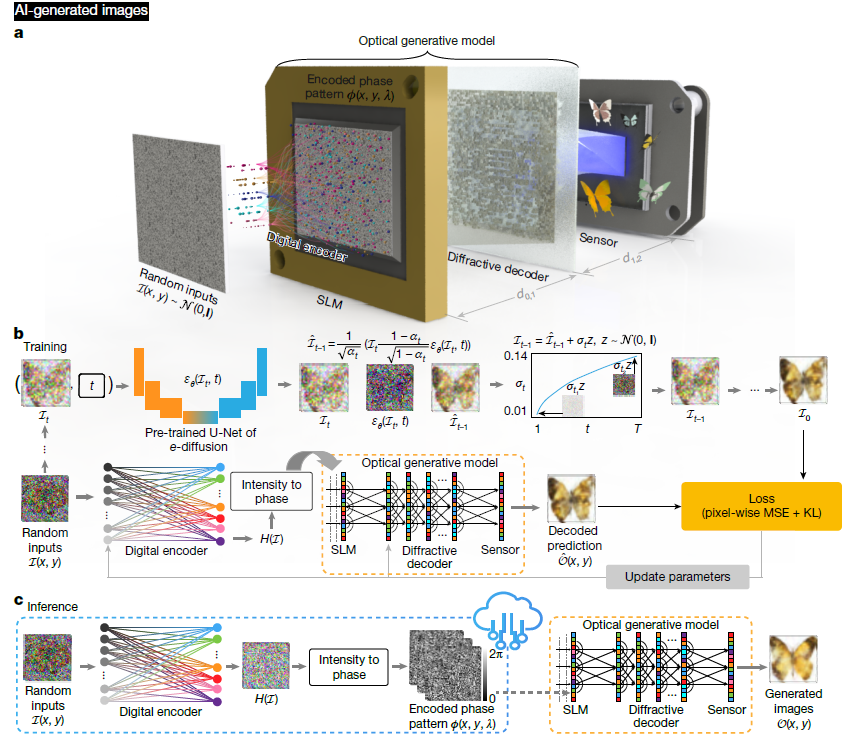
论文Optical generative models论文提出了一种新颖的“光学生成模型”(Optical Generative Model, OGM),以光学硬件为基础,通过自由空间光传播和可重构的衍射结构替代传统数值计算过程,从而实现无需能耗的图像生成。这种方法以浅层数字编码器将随机高斯噪声编码为相位图案,再利用光学衍射网络生成图像,目标是在保留生成质量的同时,大幅降低计算能耗。
论文作者为Shiqi Chen, Yuhang Li, Yuntian Wang, Hanlong Chen & Aydogan Ozcan,来自University of California Los Angeles。
Optical generative models
二、总体架构与核心思想
OGM 的整体结构由两个部分构成:
- 数字相位编码器:使用一个浅层数字网络(例如三层全连接网络)将随机二维高斯噪声编码为二维相位图案(optical generative seed),并加载至空间光调制器(SLM);
- 自由空间衍射解码器:固定的多层光学衍射解码器将上述光学种子通过自由空间传播转换为图像,最终由图像传感器采集。
该结构的主要创新点在于:
- 图像生成几乎完全在光学域完成,数字部分仅用于一次性的相位种子编码;
- 图像生成延迟仅由SLM帧率限制;
- 支持快照式生成与迭代式生成两种模式;
- 模型支持在无需更改物理硬件的情况下,通过替换种子和解码器即可切换生成目标分布。
三、快照式光学生成模型(Snapshot OGM)
该模型通过一次性光学传播完成图像合成过程,步骤如下:
- 随机噪声输入由浅层数字编码器H(I)转换为二维相位图ϕ(x,y),投射到SLM上;
- 相干激光照射SLM,携带相位信息的光场通过衍射网络传播;
- 经过优化的解码器将光场转换为目标图像,传感器采集图像强度O(x,y)。
训练过程:
- 首先训练一个数字去噪扩散概率模型(DDPM)作为教师网络;
- 利用DDPM生成的样本指导光学模型的优化,最小化像素均方误差(MSE)和KL散度;
- 编码器与解码器联合训练,最后固定解码器。
评估实验:
- 使用 MNIST 与 Fashion-MNIST 数据集进行训练;
- 生成图像的 Inception Score(IS)和 Fréchet Inception Distance(FID)表现良好;
- 分类器实验显示,使用100%光学生成图像训练的模型在MNIST上能达到99.18%的精度,几乎与原始数据训练的模型持平;
- 多层解码器(如5层)能提高图像质量与光功率衍射效率(可达50%)之间的权衡。
四、迭代式光学生成模型(Iterative OGM)
相比快照式模型,迭代式OGM模拟了完整的扩散过程,具体流程如下:
- 初始为随机噪声图像I_T;
- 每一轮迭代将上一步输出加入高斯噪声作为输入,经由光学传播输出新的图像I_t-1;
- 通过T轮迭代逐步将噪声映射为目标图像分布I_0。
关键特点:
- 同样使用多波长(三通道RGB)进行彩色图像生成;
- 解码器为固定结构,数字编码器为浅层网络;
- 支持去除数字编码器的版本,通过SLM实现相位映射。
实验结果表明,迭代模型生成的图像质量更高、背景更清晰,并且不会发生“模式崩溃”(mode collapse),显示了良好的多样性与稳定性。
五、实验系统与实物验证
作者构建了一个工作于可见光波段的实验平台,主要硬件包括:
- 激光光源(520nm);
- 两个SLM分别实现编码种子投影和固定解码器;
- 图像传感器采集最终生成的图像。
关键实验结果:
- 成功生成 MNIST 与 Fashion-MNIST 图像;
- 分别获得实验FID值为 131.08 和 180.57;
- 探索了输入相位编码空间与解码器位深(例如从8-bit降为4-bit)对图像质量的影响;
- 多次实验结果显示,提升SLM相位编码范围与解码器位深有助于生成更高质量图像。
六、高分辨率图像与艺术风格生成
为进一步展示OGM的能力,作者使用 Van Gogh 风格画作作为目标数据集,开展了以下实验:
- 训练使用Stable Diffusion模型微调vangogh2photo数据集作为教师模型;
- 数字编码器参数提升至5.8亿,生成分辨率提升至1000×1000;
- 实验中展示了既与教师模型相似,也风格迥异的新图像,显示出生成模型的创造性;
- 彩色图像生成使用 {450, 520, 638}nm 三种波长;
- 光学生成图像的语义一致性通过CLIP评分进行评估,结果表现稳定且与数字模型一致。
七、性能分析与模型对比
作者将光学生成模型与数字生成模型进行如下对比:
- 在模型深度、FLOPs、参数量、IS值等维度进行评估;
- 结果表明:浅层OGM可以达到等同于9层数字网络的图像生成质量;
- 光学生成模型的图像更加多样且能效高。
此外,通过引入训练时模拟硬件限制(如SLM相位位深),可以提高实际系统鲁棒性。
八、未来展望与挑战
本研究验证了在无需能耗计算的条件下,OGM可以生成高质量图像,其潜在应用包括:
- 边缘计算设备(如AR/VR显示);
- 高速图像合成;
- 多图像并行生成;
- 多通道三维图像生成等。
但也存在挑战:
- 硬件误差、光学对准问题;
- SLM与解码器的物理位深限制;
- 成本与系统复杂度问题。
为应对这些挑战,作者建议:
- 在训练中融合物理约束;
- 使用离散相位层(如三相位:0, 2π/3, 4π/3)可制造简单被动解码器;
- 借助双光子聚合、纳米光刻等技术制造微型固定解码器。
九、总结
本文提出的光学生成模型,在数字与光学联合训练的框架下,利用浅层编码器与自由空间衍射解码器,实现了无需传统计算资源即可高质量图像生成的全新路径。无论是快照式还是迭代式模型,在MNIST、Fashion-MNIST、Butterflies-100、Celeb-A及Van Gogh画风等多种分布上均取得了媲美甚至优于数字模型的生成效果。该研究不仅在AI内容生成能效方面开辟新思路,也为光学-人工智能融合领域奠定了坚实基础。