论文In-Context Fine-Tuning for Time-Series Foundation Models聚焦“将多条相关时间序列的少量样例在推理时作为上下文提供给基础模型”,以在零样本/少样本场景下提升预测精度,并避免逐数据集微调的昂贵代价。作者提出一种“上下文内微调(In-Context Fine-Tuning, ICF)”的方法:把基础的 TimesFM 继续预训练,使其学会在推理时利用来自多条相关序列的示例块(examples),从而对目标域分布在线适配。论文摘要宣称:ICF 在常见基准上优于统计模型与深度监督方法,也优于其他时间序列基础模型,并且其表现可与逐数据集微调的 TimesFM-FT 相当。
论文作者为Matthew Faw, Rajat Sen, Yichen Zhou, Abhimanyu Das,来自Georgia Institute of Technology和Google Research。
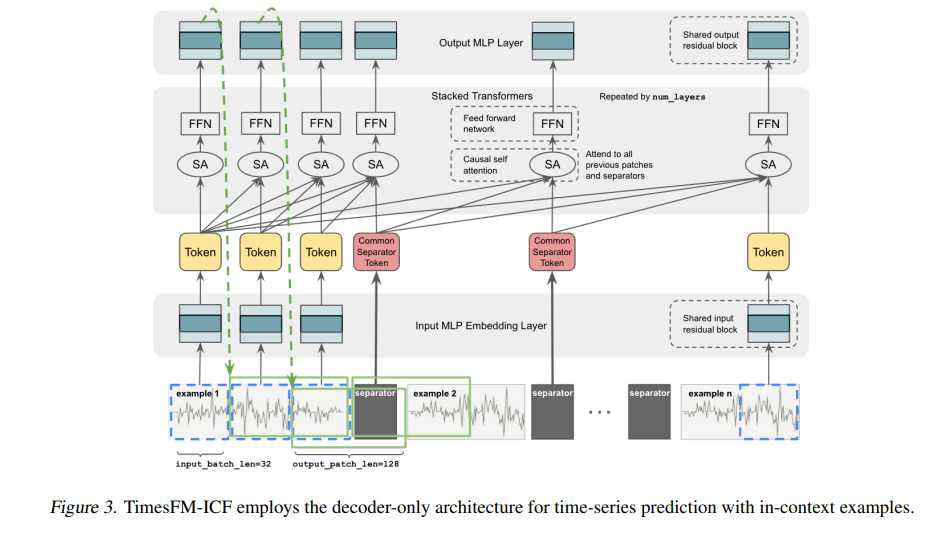
一、总体方法与模型框架
方法以 TimesFM(base) 为起点,通过继续预训练得到 TimesFM-ICF,核心是改造解码器式堆叠 Transformer,使其能够接收“目标序列历史 + 多条上下文示例”。训练阶段先按 TimesFM 原法获得 TimesFM(base),再在构造了上下文样例的数据上继续训练,得到 TimesFM-ICF。
整体仍沿用 TimesFM 的分块—残差块嵌入—解码器堆叠—残差块输出流程,只是为支持 ICF 在架构层面加入了新的组件与约束。
二、关键架构改造
1)示例分隔符(Separator):简单串接多条示例会让模型把“多条线性趋势的拼接”误认为一种新模式(如三角波),因此作者在每条示例结尾插入一个可学习的分隔符 token,显式标注样例边界,防止模式“混叠”。
2)跨示例注意力(Cross-Example Attention):Transformer 在因果注意力中允许关注此前所有补丁及分隔符 token,使模型能数清已处理的示例段,并用分隔符位的输出 token 在深层对本示例信息进行“汇总/边界传递”。
3)位置编码策略(NoPE 与长度泛化):为更好地处理跨示例与变长度,基础模型预训练时采用**不显式位置编码(NoPE)**的做法;实验显示 NoPE 在训练验证上不逊于 APE 等能泛化长度的位置编码(如 FIRE)。
三、上下文构造与继续预训练数据
设 TimesFM(base) 的最大历史 Lmax=512、输出补丁长度 h=128,则单条示例的总长度 T=Lmax+h=640。作者对每条序列以滑窗步长 1 生成长度为 T 的示例,并把 n 条示例打包为一个上下文。分组有两种:
(a)序列级:把一条长序列切成多段示例再选 n 段组成上下文;(b)数据集级:从同一数据集任意序列切出 n 段组成上下文。两法都保证模式相近、可互借信息。
继续预训练时,每个上下文最多 n=50 个示例,并从两种分组方式同时采样;考虑组合数过大,作者随机生成约 20N 组作为训练上下文;真实:合成数据按 90%:10% 混合,并在不同频率组之间均衡采样。
示例选择策略很朴素:每个上下文取5 条来自目标序列的“近历史”示例,其余从同数据集的其他序列随机抽取;其他简单策略在附录也有对比,但随机 + 近历史已足以带来显著增益。
四、推理时的提示与代价
推理时把“目标序列历史 + 最多 50 条上下文示例(其中尽可能含 5 条同序列近历史示例)”串接,并以分隔符界定样例边界。由于注意力计算随示例数增加而增长,存在“精度 ↑ vs 计算时延 ↑”的权衡。
五、实验设置与评价指标
作者在 Chronos 零样本集合(覆盖 27 个数据集)中选取训练未见过的 23 个数据集,构成OOD Benchmark;另在 ETT Rolling Window上做滚动评估。评价采用MASE,并对每个数据集用季节性朴素法的 MASE 归一化后取几何平均(GM),以消除量纲与尺度差异。
六、主要结果
1)OOD Benchmark 总结:
· TimesFM-ICF 在零样本推理下“匹配”逐数据集微调的 TimesFM-FT;
· 相比 TimesFM(base) 几何平均 Scaled-MASE 提升 6.8%;
· 相对最强的非微调基线 PatchTST 再优 5%。
2)ETT Rolling Window:多数数据集和不同地平线下,TimesFM-ICF 的 MAE 优于或接近强监督与零样本基线(如 iTransformer、TimesNet、PatchTST 等),细表给出逐数据集对比。
3)时间与成本:
在顺序处理全部数据集的设定下,ICF 无需微调,仅推理约 25 分钟;而 TimesFM-FT 需要微调 29–84 分钟 + 推理 57–418 分钟(随设定不同),且并不总能超过 ICF 的表现。
七、消融与权衡
1)示例数量 vs 误差/时延:在 OOD 的“短上下文”数据集上,随着上下文示例数增加,Scaled-MASE 单调下降,同时总推理时间上升,呈现清晰的精度-时延权衡。
2)更长历史是否等价于更多示例? 作者对比“延长基础模型历史上限”与“加入上下文示例”,显示 ICF 的收益并非仅来自“更长上下文”,而是来自跨示例迁移与对齐。
3)示例选择策略:随机 + 近历史已很强,附录给出多种策略(含基于 DTW 的相似度选择)对比;总体差异有限,简单策略足以稳定获益。
八、位置编码与长度泛化
在继续预训练时采用 NoPE 的设计在验证上与 APE 或其他“可长度泛化”的位置编码(如 FIRE)持平或更优,支持了“不显式绝对位置”在 ICF 框架里的稳健性。
九、结论与局限
作者证实:让时间序列基础模型学会在推理时利用上下文示例,能在零样本条件下取得与微调相当的性能,同时节省大量微调时间与运维成本。未来工作包括:把 ICF 的适配推广到其他基础模型,以及探索更好的相对位置编码与更优的示例选择。
十、实践启示与落地建议
1)何时选 ICF:当新域数据难以集中微调或需快速上线时,优先考虑 ICF;它在23 个未见过的数据集上的效果与逐数据集微调相当,且无需训练时延。
2)上下文大小与时延权衡:示例数带来近似单调的精度收益与线性增长的推理耗时,可在 10–50 的范围内按预算取舍;若需最优点,作者在验证上观察到总 34 个示例、其中 11 个同序列近历史的组合最优(供参考)。
3)示例选择:优先纳入同序列近历史(≈5–11 条),并配以随机的跨序列示例即可获得稳定收益;复杂相似度检索(如 DTW)并非必要条件。
4)数据工程:构造示例长度 T=640(由 512 历史 + 128 预测块)的滑窗片段;对短序列做合理左/右填充并确保注意力不误读填充区域。
5)架构落地:务必实现可学习分隔符与跨示例注意力;位置编码上,NoPE/FIRE 等长度稳健方案更利于跨示例、跨长度的一致性。