论文A decoder-only foundation model for time-series forecasting提出了一种解码器专用的时间序列基础模型 TimesFM,通过大规模时间序列数据的预训练,使其具备强大的零样本预测能力,能够高效适应不同任务,减少计算成本,并在多个时间序列预测基准上取得接近 SOTA 的性能。
论文作者为Abhimanyu Das, Weihao Kong, Rajat Sen, Yichen Zhou,来自Google。
一、引言
时间序列数据广泛应用于零售、金融、制造、医疗健康和自然科学等多个领域。在这些领域,时间序列预测是一项关键任务,涉及供应链优化、能源和交通流量预测、天气预报等。在过去的几年里,深度学习模型已逐渐取代传统的统计方法,如 ARIMA 或 GARCH,成为时间序列预测的主流方法。
与此同时,自然语言处理(NLP)领域的基础模型(如 GPT-3、Llama-2)取得了巨大进展。大规模语言模型(LLM)可以用于生成文本、翻译语言、回答问题等,并且往往能够在零样本学习模式下表现出色。这引发了一个重要问题:是否可以利用相似的方法,构建一个大规模预训练的时间序列基础模型,使其在从未见过的数据集上也能实现接近最优的预测性能? 这样的模型如果可行,将极大降低下游预测任务的计算成本和训练负担。
本文提出了一种仅基于解码器(Decoder-Only)的时间序列基础模型 TimesFM,通过大规模时间序列数据的预训练,使其能够在不同的预测任务上实现零样本预测,且其性能接近于专门为特定任务训练的最优监督学习模型。我们的方法基于:
- 大规模时间序列数据集,包括真实世界数据(如 Google 搜索趋势、Wikipedia 页面访问量)和合成数据,确保了足够的训练数据多样性和规模。
- 基于 Transformer 解码器的架构,采用输入分块(patching) 机制,提高训练效率和推理速度。
相比于最新的 LLM 直接用于时间序列预测的方法(如 TimeGPT-1),我们的模型在较小的参数规模(200M)和训练数据规模(100B 级别数据点)下,仍然能实现出色的零样本预测性能,同时大幅降低计算成本。
二、相关工作
1. 时间序列预测模型的发展
过去十年,深度学习模型在时间序列预测任务上逐步超越传统统计方法,如:
- 局部单变量模型:包括 ARIMA、指数平滑等传统统计方法,每个时间序列单独训练一个模型。
- 全局单变量模型:如 DeepAR、Temporal Convolutional Networks(TCN)、N-BEATS,这些模型在多个时间序列数据上进行联合训练,但在推理时仅利用当前时间序列的数据进行预测。
- 全局多变量模型:如经典的 VAR 模型,以及基于深度学习的方法(如 Transformer、Graph Neural Networks),可以同时使用所有时间序列的历史数据进行联合预测。
虽然部分方法(如 PatchTST 和 N-BEATS)展示了一定的跨数据集迁移学习能力,但至今没有一个统一的时间序列基础模型能够实现跨多个领域的零样本预测。
2. 预训练大模型在时间序列上的应用
近来,有研究尝试利用大语言模型(LLM)进行时间序列预测,例如:
- TimeGPT-1:专门针对时间序列的零样本预测模型,但未公开关键的模型细节和数据集。
- 直接微调 GPT-3 或 Llama-2:已有研究表明这些 LLM 可用于时间序列预测,但效果远不及专门预训练的时间序列模型,且计算成本较高。
相比之下,我们的模型从零开始 训练,专门针对时间序列数据进行优化,在零样本预测能力和计算效率 之间达成更优的平衡。
三、问题定义
我们希望构建一个通用的零样本预测模型,能够接受过去 C个时间步长的数据,并预测未来 H个时间步长的值。数学上,可以表示为:
f:(y1:L)→ŷL+1:L+H
其中,y1:L表示上下文历史数据,ŷL+1:L+H为模型预测的未来值。
模型的目标是在没有任何任务特定训练的情况下,实现与最优监督学习模型相当的预测精度。
四、模型架构
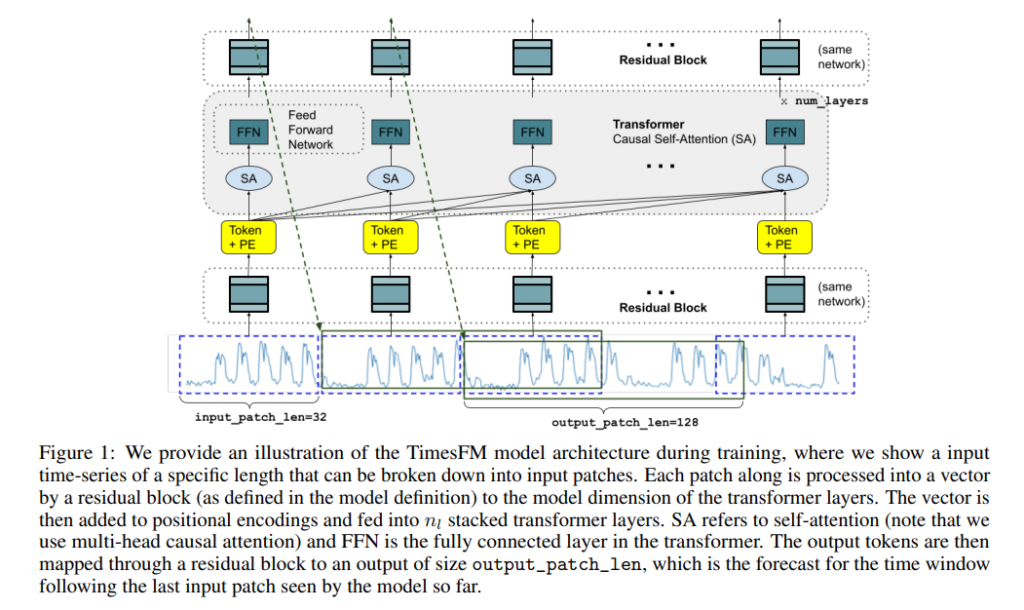
我们的TimesFM 模型 基于 Transformer 架构,采用仅解码器(Decoder-Only) 结构,并针对时间序列数据进行了专门优化。关键设计包括:
1. 输入分块(Patching)
受到 NLP 领域中 token 化方法的启发,我们将时间序列划分为固定长度的非重叠片段(patches),类似于 NLP 中的 token。这样可以:
- 提高训练和推理速度(减少 Transformer 需要处理的 token 数量)。
- 避免过长的自回归序列,提高长期预测的准确性。
2. 仅解码器(Decoder-Only)架构
与 PatchTST 的全 Transformer 结构不同,我们采用仅解码器模式,即:
- 仅利用过去时间片段的信息来预测未来片段。
- 允许模型适应不同的历史长度,提高泛化能力。
3. 输出片段长度优化
在 NLP 任务中,LLM 生成文本时通常采用自回归逐步生成,但在时间序列预测中,我们发现一次性预测较长序列的效果更优。因此,我们设计了:
- 输入片段长度较短(如 32),用于捕捉局部特征。
- 输出片段较长(如 128),减少自回归步数,提高长时预测精度。
4. 片段掩码(Patch Masking)
如果仅基于固定长度片段进行训练,模型可能只能学习到特定长度的输入。因此,我们在训练时随机屏蔽部分输入片段,使模型能够适应任意历史长度 的输入。
五、预训练数据集
我们构建了一个大规模、多样化的时间序列数据集,包括:
- Google Trends(0.5B 数据点):涵盖 22K 个热门搜索关键词,时间跨度 2007-2022,包含小时、日、周、月 级别数据。
- Wikipedia Pageviews(300B 数据点):记录 2012-2023 年所有维基百科页面的访问量。
- 合成数据(3M 序列,每个 2048 时间步):基于 ARMA 过程、正弦曲线、趋势变化等生成。
- 其他公开数据集:包括 M4 竞赛数据集、交通流量、电力负荷、天气数据等。
数据集混合策略:我们在训练时按照80% 真实数据 + 20% 合成数据 的比例进行混合,以确保模型的泛化能力。
六、实验结果
1. 零样本预测能力
我们在 3 组公开数据集上进行了测试:
- Monash 时间序列存档(30 个数据集)
- Darts 基准测试(8 个单变量时间序列)
- Informer 长时预测数据集(ETT 数据集)
实验结果表明:
- TimesFM 的零样本性能接近于或优于专门训练的 SOTA 监督学习模型。
- 在 Monash 和 Darts 数据集中,TimesFM 的预测精度超过 LLM 直接微调的方法(如 llmtime)。
- 在长时预测任务(如 ETT),TimesFM 可与专门的深度学习模型(如 PatchTST)媲美。
2. 模型消融实验
我们研究了模型架构的影响:
- 参数规模增加时,预测精度持续提升。
- 较长的输出片段能有效提高长时预测的性能。
- 合成数据的引入能显著提升模型在罕见时间粒度上的泛化能力。
TimesFM on HuggingFace: https://huggingface.co/google/timesfm-2.0-500m-jax
TimesFM on GitHub: https://github.com/google-research/timesfm