论文LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models提出的LLaMAFactory,是当前最全面、可扩展性极强的LLM高效微调框架之一,兼具技术深度与实用性。在解决统一性、易用性与训练效率这三大难题方面提供了系统化、工程化的解决方案,并通过丰富实验证明其有效性,代表了当前开源LLM微调工具的发展前沿。
论文作者为Yaowei Zheng(郑耀威), Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, Yongqiang Ma,主要来自Beihang University(北京航空航天大学)。
一、研究背景与动机
当前大语言模型(LLM)在诸多自然语言处理任务中展现出卓越能力,但将它们高效地微调到下游任务仍面临显著挑战,尤其在资源有限的条件下。尽管社区已经提出多种参数高效微调方法(如LoRA、QLoRA、DoRA等),但缺乏一个统一的、模块化的平台来整合这些方法并适配不同模型结构。此外,大多数现有工具链仍需较高的代码门槛,这限制了非专业用户的使用。
二、LLaMAFactory框架概述
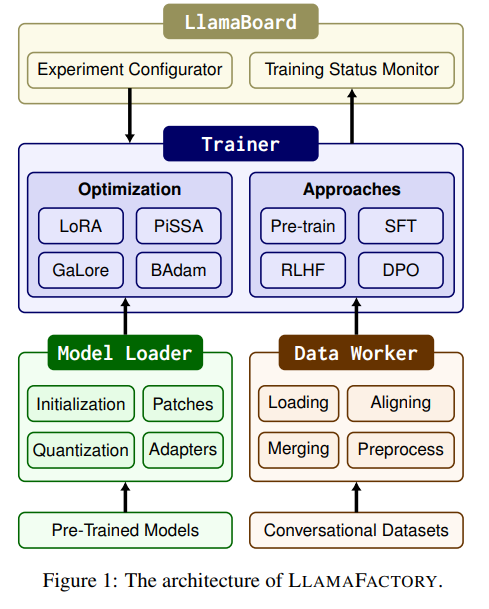
LLaMAFactory是一个统一的高效微调框架,支持超过100种主流开源LLM模型,并整合了多个高效微调技术。该框架的核心优势包括:
- 模块化设计:分为Model Loader、Data Worker与Trainer三大模块,互相解耦,便于扩展与维护。
- 可视化界面LLaMABoard:基于Gradio构建,用户无需编程即可配置和监控微调任务。
- 广泛支持模型与方法:兼容LoRA、QLoRA、DoRA、PiSSA、GaLore、BAdam等微调方法,以及SFT、RLHF、DPO、KTO、ORPO等训练策略。
三、高效微调方法详解
论文将微调方法分为两类:
- 优化效率导向(Efficient Optimization):
- Freeze-tuning:冻结大部分参数,仅训练少量解码器层。
- LoRA / QLoRA:引入可训练的低秩矩阵,同时QLoRA结合权重量化进一步降低内存。
- DoRA:对预训练权重分解为方向与模长,仅更新方向部分。
- LoRA+ 与 PiSSA:分别通过改进低秩初始化与主成分初始化加快收敛。
- GaLore:将梯度投影至低维子空间以减少内存。
- BAdam:基于块坐标下降的优化器,适合全参数微调。
- 计算效率导向(Efficient Computation):
- 混合精度训练(bfloat16/float16)、激活检查点、FlashAttention、S2 Attention等。
- Unsloth:用于LoRA反向传播的优化技术,大幅加速训练。
- 量化支持:4/8-bit 权重量化支持与LoRA兼容。
四、三大核心模块设计
- Model Loader:
- 支持自动初始化、模型打补丁(如启用Flash/S2 Attention)、权重量化(GPTQ、AWQ、AQLM)及适配器挂载(LoRA等)。
- 支持不同设备的精度适配策略(CUDA、AMD、Ascend等)。
- Data Worker:
- 数据加载支持本地与远程,兼容HF Hub。
- 支持多种数据结构(Plain、Alpaca、ShareGPT、Preference、标准格式),通过对齐规范统一结构。
- 支持多数据集合并与模板预处理,自动选择Chat模板与Tokenizer进行编码。
- Trainer:
- 集成Transformers与TRL库的训练器,实现预训练、SFT、RLHF与DPO等。
- 提出“模型共享型RLHF”,首次支持在单消费级设备上完成RLHF全流程(一个模型轮换担任Policy、Reward等多角色)。
- 支持DeepSpeed分布式训练(ZeRO优化器),极大降低内存。
五、LLaMABoard界面系统
- 易配置:通过Web UI配置所有参数,内置推荐值与数据预览功能。
- 训练监控:实时可视化训练日志与loss曲线。
- 评估功能:支持BLEU、ROUGE、MMLU、CMMLU、C-Eval等自动评估,或通过对话进行人工评估。
- 多语言支持:目前支持中文、英文与俄语。
六、实验验证
- 训练效率评估:
- 使用PubMed数据集,分别对Gemma-2B、Llama2-7B与13B模型进行微调。
- 比较了Full-tuning、Freeze、GaLore、LoRA、QLoRA等方法在内存、吞吐与困惑度(PPL)上的差异。
- QLoRA内存占用最低,LoRA在小模型上效果更优,GaLore在大模型表现更佳。
- 下游任务效果评估:
- 在CNN/DM、XSum、AdGen三个摘要与生成任务上进行实验,使用ROUGE作为评估指标。
- 在大多数任务中,LoRA与QLoRA能取得最优或次优结果,展示出极强的适应性。
- Llama3-8B整体性能最佳,Yi-6B与Mistral-7B在同规模模型中表现出色。
七、未来工作展望
作者提出三点未来扩展方向:
- 扩展多模态模型支持(如语音、视频模型)。
- 引入更多并行训练策略(如序列并行与张量并行)。
- 加强对话模型的微调能力,如引入自博弈(self-play)机制。
八、社会影响与开源生态
LLaMAFactory在GitHub已获得超2.5万Star与3千Fork(截至2025年7月,已获得超5.34万Star与6.5千Fork),并被收录至HuggingFace的Awesome Transformers列表。其可视化、模块化、支持广泛模型与方法的特点,极大促进了普通用户与研究人员对LLM的探索与创新。同时作者强调严格遵守开源协议,避免滥用。
LLaMAFactory on GitHub: https://github.com/hiyouga/LLaMA-Factory