个人健康与日常福祉高度相关,但传统“单体式”对话大模型在面对真实用户的多样化健康诉求(数据解读、医学知识查证、行为改变指导等)时往往力不从心。论文The Anatomy of a Personal Health Agent提出并系统评估了一个面向个人健康的多智能体框架——Personal Health Agent(PHA),目标是在非临床日常场景下,综合可穿戴设备与常见个人健康记录等多模态数据,为个体提供证据支撑的个性化建议与教练式互动。论文基于大规模用户需求分析与以人为本的设计流程抽象出关键用户旅程,并据此设计系统与评测方案。
论文作者为A. Ali Heydari, Ken Gu, Vidya Srinivas, Hong Yu, Zhihan Zhang, Yuwei Zhang, Akshay Paruchuri, Qian He, Hamid Palangi, Nova Hammerquist, Ahmed A. Metwally, Brent Winslow, Yubin Kim, Kumar Ayush, Yuzhe Yang, Girish Narayanswamy, Maxwell A. Xu, Jake Garrison, Amy Armento Lee, Jenny Vafeiadou, Ben Graef, Isaac R. Galatzer-Levy, Erik Schenck, Andrew Barakat, Javier Perez, Jacqueline Shreibati, John Hernandez, Anthony Z. Faranesh, Javier L. Prieto, Connor Heneghan, Yun Liu, Jiening Zhan, Mark Malhotra, Shwetak Patel, Tim Althoff, Xin Liu, Daniel McDuff, Xuhai “Orson” Xu,主要来自Google。
一、总体框架与三类子智能体
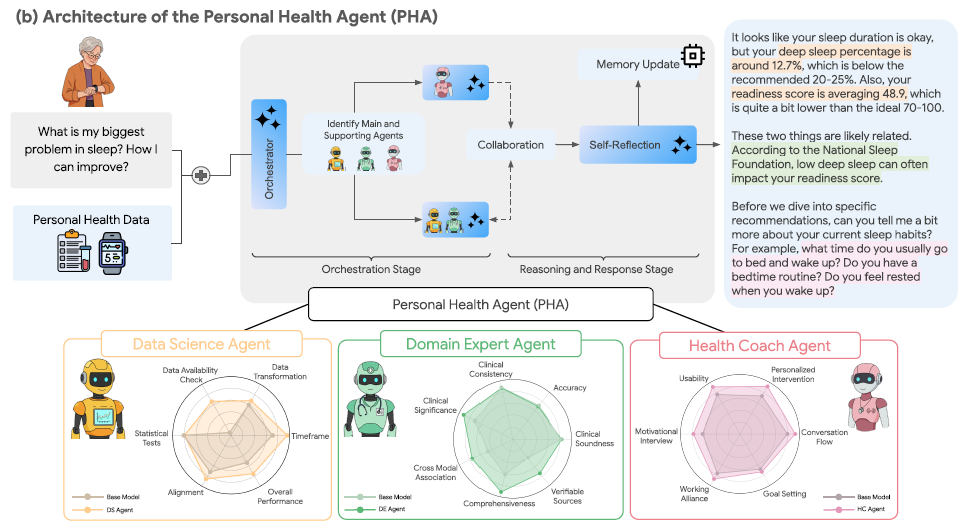
PHA 采用“专长分工 + 动态编排”的多智能体架构:①数据科学智能体(Data Science, DS)——面向个人时间序列与检验指标的数据分析;②领域专家智能体(Domain Expert, DE)——基于权威医学知识库进行多步推理与事实求证;③健康教练智能体(Health Coach, HC)——以心理学方法(如动机式访谈)进行目标设定与行为改变引导。三者由一个“编排器”根据用户问题动态分派主/辅角色,迭代协作、反思与记忆更新,最终生成连贯一致的综合回复。
二、以用户为中心的需求建模
作者先对 1,300+ 条真实健康查询(健康论坛与网络检索)进行分析,结合 500+ 用户问卷与跨学科研讨,梳理出四类高频需求:理解通用健康主题、解读个人数据、获得可执行的福祉建议、进行症状评估。此需求图谱直接驱动了三类子智能体的职能设定与协作接口设计。
三、数据来源与任务设置
评估阶段使用一项经 IRB 审查的真实世界数据集:约 1,200 名用户提供了 Fitbit 可穿戴数据、健康问卷与血液生物标志物等。团队围绕 10 个基准任务进行“自动 + 人工”两层评测,累计 7,000+ 标注与 1,100 小时专家/终端用户评审工时,覆盖从子智能体能力到整机系统效能的全链路。
四、数据科学智能体(DS)机制与成效
DS 子智能体在强大基础模型(如 Gemini)之上叠加“两阶段数据科学模块”:Stage-1 把含糊/欠规范的自然语言提问转译为“统计分析计划”;Stage-2 产出并执行可运行代码,完成稳健的时间序列统计分析。作者构建了两个自动评测:其一对“分析计划质量”进行打分(基于 10 位数据科学家对 354 条问答的标注与细化评分维度,如数据充足性、统计有效性、与用户问题对齐等),结果显示 DS 计划质量得分 75.6%,显著优于同基座的“单模型”基线 53.7%;其二以 173 个单元测试检验代码生成的可执行与正确性,证实其在可穿戴数据分析上的可靠性更高。
五、领域专家智能体(DE)机制与成效
DE 子智能体强调“可核查的医学事实”。其采用多步推理并配备权威外部工具箱(如连到 NCBI/PMC 文献资源)进行证据检索与事实落地。在评测上,团队设置了两类自动评测(如医学/教练类选择题与鉴别诊断任务)与两类人工评测(临床专家与普通消费者),指标涉及个性化、临床相关性、多模态理解等。总体上,DE 在所有基准上均显著优于基线,专家评价其汇总与解读多模态健康数据的临床相关性更强,用户也认为其建议更具个体相关性与可信度。
六、健康教练智能体(HC)机制与成效
HC 子智能体以模块化架构实现教练会话:在“探询—建议”之间取得平衡,遵循专业教练原则并输出可执行行动方案。作者通过两份人工评测(终端用户与健康教练专家)考察会话体验、目标导向、动机支持、建议质量与可信度等维度;结果表明 HC 在多项关键维度上显著优于基线,且研究强调“教练型代理的核心能力与可执行性”对用户感知尤为关键。
七、系统级编排与对照
在系统层面,PHA 的智能编排把 DS/DE/HC 三者协同组织成“人类专家团队”式的工作流,并与两个强基线对比:①强力单智能体(同一基座 + 工具,但在单体内尝试扮演三种角色);②并行多智能体(同样的三子智能体,但只是并行调用后简单汇总)。在多项“综合回答质量与目标达成度”的人工评测中,专家与用户多数场景偏好 PHA,显示“动态协作 + 角色分工”的系统优势。
八、方法学要点与工程实现启示
1)角色清晰与接口稳定:把“统计计划”“证据检索”“行为改变”拆解为可评估子任务,能降低幻觉与不一致。2)工具增强的可重复性:对 DS 引入单元测试与计划评分器是把 LLM-Agent 工程化的重要步骤。3)事实对齐与来源可追溯:DE 强制接入权威医学知识库,显著提升可信度与个性化。4)面向人因的教练策略:HC 引入动机式访谈等可操作框架,让“建议”可落地、可复盘。5)系统编排优于“堆模型”:动态主辅分工与记忆更新机制优于“并行求和”。
九、评测设计的亮点与可能的盲区
亮点:真实世界多模态数据 + 大规模人工评审,覆盖从子模块到整机的层级化评测;对 DS 的“计划—代码—单测”链路,降低了幻觉与算错的风险。潜在盲区:① 评测仍以研究原型为主,尚未覆盖监管、长期疗效、跨人群公平性等;② 数据主要来自可穿戴 + 常见检验,临床高风险决策与医嘱替代并非目标;③ 多智能体在真实部署中的隐私、合规与延迟/成本控制仍待进一步验证。
十、与相关工作的关系
此前学界已有“面向可穿戴数据的健康洞察代理”等方向,但多聚焦单一环节(如仅做数据计算或仅做知识问答)。本文贡献在于以用户旅程为导向,把“数据分析—知识求证—行为教练”三条链路打通,并在统一编排下给出系统级比较全面的实证。
十一、结论与应用前景
作者将 PHA 定位为“研究原型与方法蓝图”,并明确声明这不是任何现有或在研产品的描述;若进入现实应用,还需独立的设计、验证与审查流程。总体而言,论文提供了面向“日常非临床场景”的个人健康智能体设计范式:用可核查的知识、可执行的数据分析、可落地的行为教练三者协作来提升实用价值。对产业落地而言,可将其转译为“角色化微服务 + 工具链 + 评测基座”的工程体系。
十二、可从本文汲取的实践要点(面向实现者)
1)为 DS 明确“统计分析计划”的结构化模板(变量选择、窗口、检验方法、协变量与混杂控制等),并配套单元测试集。2)为 DE 接入权威医学知识源(如 NCBI/PMC)并记录证据链,强化可追溯性。3)为 HC 设定会话流程(目标设定→动机澄清→行动分解→障碍识别→复盘),并加入过程性打分。4)系统编排器需维护“用户态与任务态”的记忆体与决策日志,支持可解释复盘与 A/B 评估。
十三、局限与未来工作
作者强调后续需面向更广泛人群、更多数据域(如膳食记录、环境暴露、心理量表)、更长期追踪,以及隐私保护、合规治理与医疗安全边界的系统性研究;此外,还需对“多智能体协作成本/时延”与“单体模型能力增强”的折中进行量化。
十四、关键信息速览
• 多智能体三角色:DS(个人数据分析)、DE(证据型医学知识)、HC(教练式行为改变)
• 数据与评测:IRB 数据(≈1,200 用户);10 个任务;7,000+ 标注与 1,100 小时人评
• 关键数值:DS 的“分析计划质量”75.6% vs 基线 53.7%;代码生成经 173 个单测校验
• 结论:PHA 在多数人工评审中优于强单体与“并行三体”基线;研究原型,非产品声明