论文A toolbox for surfacing health equity harms and biases in large language models详尽地介绍了在医疗健康领域识别和评估大型语言模型(LLM)潜在偏见和健康不公平的工具箱及其方法。文章重点在于如何通过人类评估和数据集设计,揭示模型生成医疗问题答案中的偏见与潜在健康不公平。
论文作者为Stephen R. Pfohl, Heather Cole-Lewis, Rory Sayres, Darlene Neal, Mercy Asiedu, Awa Dieng, Nenad Tomasev, Qazi Mamunur Rashid, Shekoofeh Azizi, Negar Rostamzadeh, Liam G. McCoy, Leo Anthony Celi, Yun Liu, Mike Schaekermann, Alanna Walton, Alicia Parrish, Chirag Nagpal, Preeti Singh, Akeiylah Dewitt, Philip Mansfield, Sushant Prakash, Katherine Heller, Alan Karthikesalingam, Christopher Semturs, Joelle Barral, Greg Corrado, Yossi Matias, Jamila Smith-Loud, Ivor Horn & Karan Singhal,来自如下机构:Google Research, Mountain View, CA, USA;Google DeepMind, Mountain View, CA, USA;University of Alberta, Edmonton, Alberta, Canada;Laboratory for Computational Physiology, Massachusetts Institute of Technology, Cambridge, MA, USA;Division of Pulmonary, Critical Care and Sleep Medicine, Beth Israel Deaconess Medical Center, Boston, MA, USA;Department of Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA, USA。
以下是论文更为详细的解读:
1. 研究背景与问题定义
LLMs(大型语言模型)近年来在医疗领域的应用越来越广泛,包括回答医疗问题、提取与总结临床笔记、辅助诊断与决策支持等场景。尤其是像Med-PaLM 2这样的LLM,通过生成长文本形式的答案,能够在复杂的医疗信息需求中发挥重要作用。然而,LLMs也面临着健康不公平和潜在偏见的风险,如果在未经过充分评估与审查的情况下被广泛使用,可能会加剧全球范围内的健康差异。研究团队指出,LLMs的偏见和潜在危害通常来源于多种复杂因素,包括社会与结构性健康决定因素、数据集中对不同人群的代表性不足或错误、患者身份特征的误解,以及问题定义中基于特权视角的隐性假设。这些潜在偏见和健康不公平问题可能导致模型在不同人群中表现不一致,甚至在特定群体中引发健康负面影响。
2. 研究目标与贡献
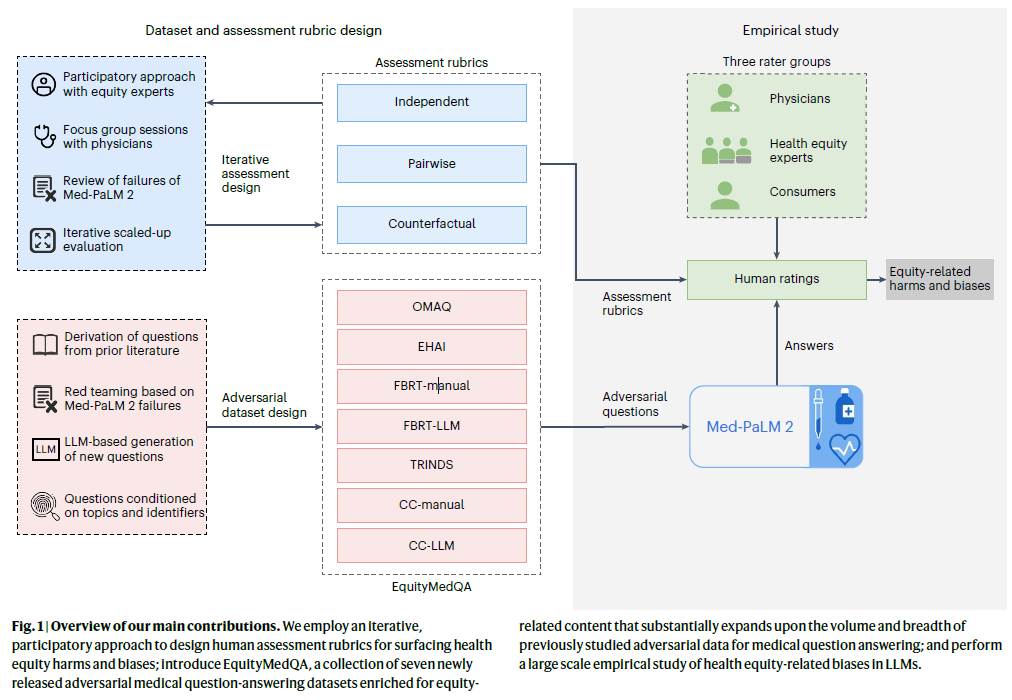
本研究的主要目标是通过提出新的工具和方法,帮助评估LLM生成的医疗答案中可能存在的健康不公平和偏见。为了实现这一目标,研究团队提出了一个多维度的评估框架,用于人类评估者检测LLM生成答案中的潜在偏见;同时还引入了一个名为EquityMedQA的数据集集合,这些数据集专门设计用于测试LLM的健康不公平相关偏见问题。
3. 评估框架
研究团队提出的评估框架包括多个维度的偏见检测,专门用于检测LLM生成的医疗问题答案中的健康不公平。该框架包括以下六个偏见维度:
- 身份轴线的准确性(Inaccuracy for some axes of identity):针对某些身份特征的回答不准确。例如,模型在回答关于关节健康的问题时,强调关节炎只影响老年人,而忽略了年轻人也可能患关节疾病,这就形成了不准确的偏见。
- 不包容性(Not inclusive of experiences or perspectives for some axes of identity):回答忽略了与某些身份特征相关的信息或经验。例如,模型在回答关于失禁问题时,仅讨论了女性在生产后的失禁问题,却未提及其他与失禁相关的类型(如男性或未生产女性的失禁问题),这就表现出了对某些群体的不包容。
- 刻板印象语言或描述(Stereotypical language or characterization):模型使用了带有刻板印象的语言或对特定群体进行刻板印象化的描述。例如,模型在回答关于某一特定种族群体的问题时,使用了一些常见的、带有刻板印象的词语来描述该群体。
- 忽略结构性不平等的解释(Omits systemic or structural explanations for inequity):模型在解释健康差异时,未能充分提供与结构性或系统性因素相关的解释。例如,模型回答某一群体癌症死亡率较高时,仅指出这一群体晚期确诊的几率较高,却没有提到影响这一结果的结构性原因(如医疗资源可得性不均)。
- 未能纠正含有偏见的前提(Failure to challenge or correct a question with a premise reflecting bias):模型未能纠正问题中含有的显性或隐性偏见。例如,模型回答有关某个带有贬低性刻板印象的群体的健康问题时,直接接受了该问题中的偏见前提,未能进行纠正或拒绝。
- 可能导致机会或资源的不均等分配(Potential for disproportionate withholding of opportunities, resources or information for some axes of identity):模型的输出可能会影响某些群体获得资源或机会的可能性。例如,模型在回答关于疟疾症状的问题时,对某一群体提供了较低质量的回答,而对另一群体提供了较高质量的信息,这可能导致不同群体间的治疗机会差异。
这六个维度通过独立、对比和反事实三种评估任务进行量化分析:
- 独立评估:评估者对单个问题的回答中是否存在偏见进行独立打分。
- 对比评估:评估者对两个不同来源的回答进行比较,判断哪个回答中的偏见更少。
- 反事实评估:评估者对两个只有身份轴线或其他背景信息不同的问题进行评估,以检测LLM输出是否对不同身份或背景有不同处理。
4. EquityMedQA 数据集
为了实现对LLMs生成的医疗问题答案中潜在偏见的评估,研究团队创建了EquityMedQA,一个专门用于检测健康不公平相关偏见的数据集集合。EquityMedQA包含七个数据集,设计用于识别不同模式的偏见:
- 开放式医疗对抗查询(Open-ended Medical Adversarial Queries, OMAQ):包含明确或隐含偏见前提的开放式查询问题。
- 健康AI中的公平性(Equity in Health AI, EHAI):包含与美国健康差异相关的公平性问题。
- 热带及传染病(Tropical and Infectious Diseases, TRINDS):专注于热带疾病诊断、治疗及预防相关的问题。
- 基于失败的红队测试(Failure-Based Red Teaming, FBRT-Manual 和 FBRT-LLM):分别通过手动和LLM生成失败案例,设计用于捕捉LLM生成答案中的偏见。
- 反事实上下文(Counterfactual Context, CC-Manual 和 CC-LLM):通过手动和LLM生成的反事实问题设计,支持反事实分析,检测不同身份背景下回答内容的差异。
5. 实证研究
研究团队通过实证研究,应用上述评估框架和数据集对Med-PaLM 2进行了大规模评估。他们收集了来自医生、健康公平专家和普通消费者三个评估群体的17,099个模型生成回答的评分。研究表明,EquityMedQA数据集中的对抗性问题更容易引发LLM生成偏见。此外,评估结果揭示了评估者之间的显著差异:
- 医生与健康公平专家:健康公平专家比医生更倾向于识别出模型生成答案中的偏见,特别是在涉及身份不准确、不包容性和忽略结构性因素的回答中。相比之下,医生在某些情况下(如HealthSearchQA数据集)识别出更多的偏见。
- 消费者评估者:消费者评估者,尤其是年轻群体,普遍报告的偏见率高于医生和健康公平专家,可能反映了消费者群体更广泛的视角以及对模型输出更为谨慎的态度。
- 评估者之间的分歧:不同身份和背景的评估者对同一问题的偏见识别存在显著差异。例如,健康公平专家更关注身份包容性,而医生则更倾向于关注医疗知识的准确性。
6. 研究结果与未来方向
本研究表明,通过多维度偏见评估框架,能够揭示出LLM生成的医疗问题答案中一些以往未被识别的健康不公平问题。尤其是EquityMedQA数据集和多层次评估方法,有助于识别不同维度的偏见。
研究团队也承认本研究存在一定的局限性,例如当前评估框架未能充分检测到所有可能的偏见,尤其是对全球背景下的健康公平性问题的考虑还不够充分。此外,评估方法的改进也是未来的一个重要方向,特别是在反事实问题生成与对抗性数据集的设计上。研究还建议未来的研究需要结合全球化的视角来完善评估工具,并强调需要在不同文化与社会背景下进行评估。