MedGo 是一个专门针对中文医学领域的大型语言模型,论文MedGo: A Chinese Medical Large Language Model对其进行了详细介绍。
论文作者为Haitao Zhang(张海涛), Bo An,来自Shanghai East Hospital(上海东方医院)和Chinese Academy of Social Sciences(中国社会科学院)。
1. 研究背景与动机
近年来,大型语言模型(LLMs)逐渐成为人工智能领域的研究热点,它们在理解、生成和处理复杂人类语言方面展现出巨大的潜力。然而,医学领域对语言模型的要求尤为苛刻,主要表现为以下几个方面:
- 高准确性需求:医学应用对生成内容的准确性要求极高,错误的诊断或建议可能对患者健康产生严重后果。
- 可解释性要求:医学决策的高风险性质决定了模型输出必须具备较强的可解释性,传统的“黑箱”模型难以被医疗专业人员信任。
- 任务的多样性与复杂性:医学领域涉及的任务众多,如疾病分类、医学记录生成、知识抽取等,传统的LLMs缺乏针对这些专业任务的训练,难以胜任复杂的医疗场景。
针对上述挑战,MedGo 的开发旨在构建一个能够精准处理中文医学信息的大型语言模型,从而提高医学任务的处理能力,并为临床实践提供辅助支持。MedGo 是基于 Qwen2-72B(阿里巴巴通义千问) 模型进行开发的,通过专门的医学数据集进行预训练和微调,力求提升其在中文医学领域中的表现。
2. 数据集构建与处理
数据集在语言模型的开发中至关重要,特别是在医学领域。为了确保 MedGo 在医学任务中的优异表现,研究者们构建了一个大规模、领域特定的医学数据集,覆盖了广泛的医学知识。数据集分为两大类:无监督数据 和 监督微调数据。
2.1 无监督数据(用于预训练)
无监督数据用于模型的预训练,旨在帮助模型建立对医学文本的基础理解能力。构建的医学语料库包含以下 15 类关键医学数据:
- 核心医学教科书:包括各类医学基础和临床教科书,提供了系统、权威的医学知识。
- 综合医学考试题库:包含大量考试题目,有助于模型理解医学知识的应用。
- 专家共识声明:涵盖权威医学专家对某些医学问题的共识报告,有助于模型掌握临床实践的标准。
- 临床病例报告:通过真实病例的描述,帮助模型理解临床诊断和治疗的实际过程。
- 详细的医学指南与诊断治疗协议:包括临床实践的标准操作规程和治疗协议,使模型掌握标准化的诊疗知识。
- 医学百科全书、医学讲座和专著:这些数据来源为模型提供了更广泛的医学知识背景(MedGo-A Chinese Medical…)。
在数据处理方面,研究者对原始数据进行了严格的数据清洗和隐私保护措施,以确保数据的高质量和患者隐私不受侵犯。数据集规模约为 140 亿 tokens,涵盖了丰富的医学术语和情境,为模型的预训练提供了坚实的基础。
2.2 监督微调数据
监督微调数据的构建包含以下几个步骤:
- 收集开放数据:主要从可信的医学数据库中收集开放数据集,如 CMCQA 数据集,该数据集由 ChunYu 医学问答网站的对话材料构成,涵盖了 45 个临床科室,共 130 万次完整的交互会话,包含约 6500 万个 tokens。
- 自动生成数据:为了扩展数据集的覆盖范围,研究者使用 GPT-4 生成了大量的问答对,特别是针对药物使用信息,模型从 15 万个药品说明书中提取关键数据生成问答对,以提升 MedGo 在药物咨询方面的知识。
- 专家标注:邀请有经验的医师对自动生成的数据进行标注,以确保数据的准确性和相关性。专家通过人工审核的方式对生成的问题和答案进行严格评估,确保数据的高质量。
此外,MedGo 还加入了一组与安全性和人类对齐相关的数据集,称为 Safety-Prompts,专门用于处理敏感话题和不当言论。通过这些数据,模型能够在面对涉及隐私、伦理或法律问题时提供合适的回答,以避免误导或伤害用户的回答。
3. 模型的基础与训练框架
3.1 基础模型选择
为了更好地适应中文医学场景,研究者选择了 Qwen2-72B 作为 MedGo 的基础语言模型。这一选择基于以下几点原因:
- 优异的中文理解与逻辑推理能力:在医学应用中,准确理解专业术语和患者的主观表达是关键。Qwen2 的中文处理能力使其能精确解析复杂的医学文本和对话,增强了模型在国内医疗应用中的实用性。
- 良好的数学计算能力:医学领域涉及药物剂量计算、医学影像数据分析和生物统计学分析,因此模型必须具备强大的数学能力。Qwen2 在数学方面的优势使其能够处理复杂的医疗问题,支持临床决策。
- 严格的安全措施:Qwen2 的安全机制与 GPT-4 相当,能够有效防止潜在的安全风险,确保模型输出符合医学行业的合规要求。
3.2 训练过程
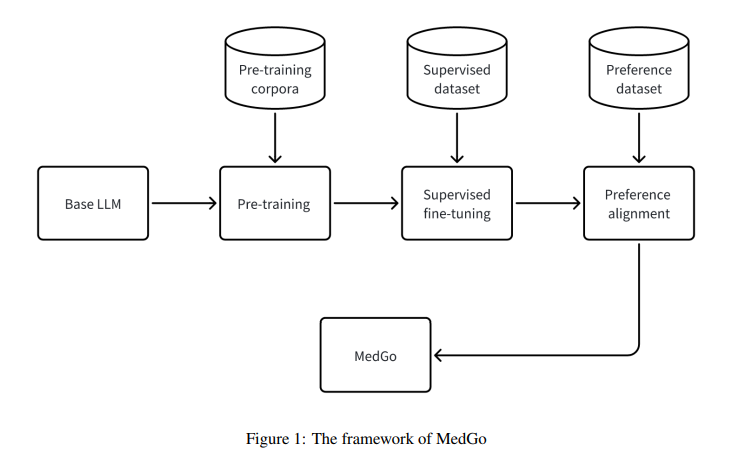
MedGo 的训练过程分为三个阶段:预训练、监督微调和偏好对齐。
- 预训练:模型在大量的医学领域文本上进行预训练,采用了掩码语言建模(MLM)、下一个句子预测(NSP)和句子顺序预测(SOP)等任务。通过 Byte Pair Encoding (BPE) 分词器来处理复杂的医学术语,并使用 AdamW 优化器和 bf16 混合精度训练来加速训练过程。同时采用了 ZeRO(Zero Redundancy Optimizer)和 FlashAttention 技术以提高训练效率和资源利用率。
- 监督微调:为了提升 MedGo 在特定医疗场景中的任务表现,研究者对模型进行了针对性的微调任务,如问答、疾病分类、命名实体识别和关系抽取等。通过使用 Low-Rank Adaptation (LoRA) 方法,模型的微调过程在保持模型性能的同时显著减少了计算资源消耗。
- 偏好对齐:为了确保模型输出符合临床应用的需求,MedGo 采用了直接偏好优化(DPO)方法。与传统的基于人类反馈的强化学习(RLHF)不同,DPO 方法训练更为稳定,避免了强化学习过程中的不稳定性和复杂性。DPO 直接利用医生的偏好数据优化模型参数,从而减少生成非期望输出的风险。
4. 实验与评估
4.1 CBLUE 基准测试
MedGo 的性能在公开的 CBLUE 基准测试上进行了评估,该测试包括 18 个不同的医学信息处理任务,涵盖了实体识别、关系抽取、事件抽取、文本分类、语义关系判断等内容。实验结果表明,MedGo 在知识抽取、对话和文本分类等任务上均表现优异,相比基模型 Qwen2-72B,MedGo 的多个任务得分显著提高,并在 CBLUE 3.0 评估中取得了第一名。
4.2 ClinicalQA 数据集评估
为了验证 MedGo 在实际临床环境中的应用潜力,研究者构建了一个包含 15,000 个多选医学咨询问题的高质量数据集,问题主要涉及疾病诊断和治疗的常见问题。每个问题有四个选项,其中一个为专家手动编制,其余三个由 GPT-4 自动生成。研究者采用严格的双重审核机制,保证选项的准确性和科学性,最终得到的 ClinicalQA 数据集非常适用于医学 NLP 研究。实验结果表明,MedGo 在该数据集上的准确率为 78.6%,显著优于基模型 Qwen2-72B 和 GPT-4o。
5. 模型部署与未来工作
MedGo 已成功部署在上海东方医院,并在实际临床场景中为医生提供决策支持和医学咨询服务。每天收集约 1000 条医生对模型回答的反馈,通过这种持续的反馈机制,MedGo 不断迭代优化其表现,以确保其在临床环境中的实用性和可靠性。
未来的工作包括:
- 引入更多的数据集进行评估:例如 MedBench 数据集,以更全面地评估 MedGo 在不同医学子领域和任务类型中的性能。
- 持续扩展和优化训练数据:进一步提升模型的准确性和泛化能力。
- 开放模型与数据集:计划将 MedGo 和 ClinicalQA 数据集开源,以促进医学领域智能化应用的推广和发展。
6. 总结与应用潜力
通过对大规模、专门的医学语料库的训练和多阶段的优化,MedGo 具备了较强的中文医学信息处理能力。实验结果表明,MedGo 在包括问答、信息抽取、临床决策支持等多项任务中的表现优异,展示了其在实际医疗场景中的巨大应用潜力。MedGo 的成功部署为医院提供了有效的辅助决策工具,也为智能医疗的未来发展奠定了基础。
在未来的发展中,MedGo 的改进方向将集中于增强模型的多样性和普适性,并确保其在不同的医学子领域都能提供高质量的服务。模型的开源也将进一步推动医学 AI 的发展,支持医疗行业内外的协作和创新。
相关阅读:吃进了6000多本教材 从内外妇儿科全方位“思考” AI医学大模型Med-Go在沪发布