论文SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation研究成果为SANA-Sprint模型,该模型通过训练自由的 TrigFlow 变换、稳定一致性蒸馏、对抗蒸馏和实时交互能力,实现高效单步文本到图像生成,推理速度快 64.7 倍,质量超越现有方法,推动扩散模型在实时应用中的落地。
论文作者为Junsong Chen, Shuchen Xue, Yuyang Zhao, Jincheng Yu, Sayak Paul, Junyu Chen, Han Cai, Enze Xie, Song Han,来自NVIDIA, MIT, Tsinghua University和Huggingface。个别作者为独立研究者。
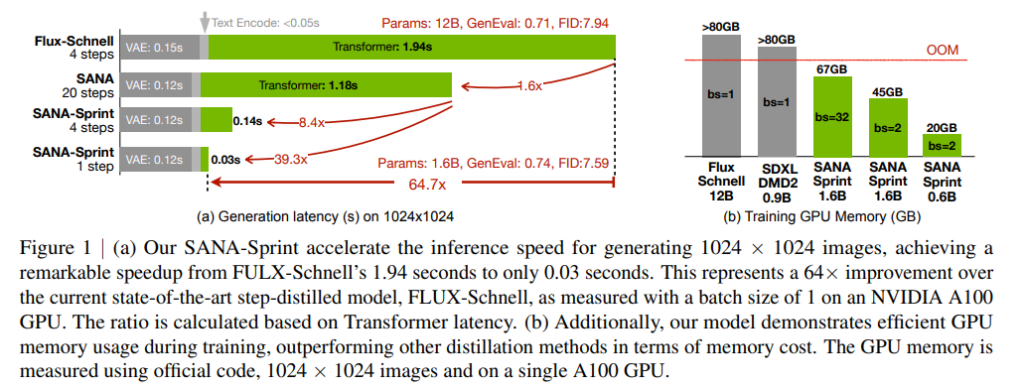
一、引言
扩散生成模型(Diffusion Models)因其高质量的图像生成能力,在文本到图像(T2I)生成领域得到了广泛应用。然而,传统扩散模型通常需要 50-100 次迭代去噪步骤,导致计算成本高昂,推理速度较慢。近年来,时间步蒸馏(timestep distillation)方法不断涌现,以实现高效推理,但仍然面临稳定性、泛化性以及生成质量的挑战。
SANA-Sprint 是一种基于SANA 预训练模型的高效扩散模型,通过结合 连续时间一致性蒸馏(sCM) 和 潜变量对抗蒸馏(LADD),将推理步数从 20 降至 1-4 步,同时保持高质量的生成效果。其核心创新包括:
- 训练自由的转换方法:通过数学变换,将流匹配模型(Flow Matching Model)转换为 TrigFlow 以适应 sCM 蒸馏,无需额外训练教师模型,提高训练效率。
- 自适应步长的统一模型:SANA-Sprint 在 1-4 步范围内均能生成高质量图像,消除了特定步长的训练需求,提高泛化性。
- 集成 ControlNet 以实现实时交互:SANA-Sprint 结合 ControlNet 实现实时图像生成,为用户提供即时反馈。
实验表明,SANA-Sprint 仅需 1 步 便能达到 7.59 FID 和 0.74 GenEval,超越 FLUX-schnell(7.94 FID / 0.71 GenEval),并且推理速度提高 10 倍(0.1s 对比 1.1s, H100 上)。
二、背景知识
1. 扩散模型及其变种
扩散模型的核心思想是通过添加噪声将干净数据逐步转换为高斯分布,然后通过训练一个去噪网络恢复原始数据。常见扩散模型包括:
- 流匹配模型(Flow Matching):采用线性插值的方式进行噪声添加,训练目标是预测数据点的速度场。
- TrigFlow:使用球面插值(Slerp)进行噪声扰动,相比线性插值,其轨迹更平滑。
- 一致性模型(Consistency Models, CMs):通过训练神经网络 𝑓𝜃(𝑥𝑡, 𝑡) 直接预测无噪数据 𝑥₀,避免迭代去噪。
2. 一致性模型的挑战
一致性模型主要包括两类:
- 离散时间一致性模型(Discrete-Time CMs):依赖数值 ODE 求解器进行训练,存在离散化误差。
- 连续时间一致性模型(Continuous-Time CMs):采用解析方法消除离散误差,但在极少步数(<4)下质量下降。
此外,现有扩散模型蒸馏方法面临诸多问题:
- GAN 方法:训练不稳定,容易模式崩溃。
- VSD(变分分数蒸馏):需额外训练一个扩散模型,增加计算开销。
- 一致性模型(CMs):在极少步数推理时,存在质量下降的问题。
SANA-Sprint 旨在结合 sCM 和 LADD 蒸馏策略,实现高效且高质量的单步扩散生成。
三、方法
1. 训练自由的 TrigFlow 变换
SANA-Sprint 通过 数学变换 将 SANA 预训练的流匹配模型转换为 TrigFlow,以适应 sCM 蒸馏。此过程无需额外训练,提高了训练效率。
核心变换如下:
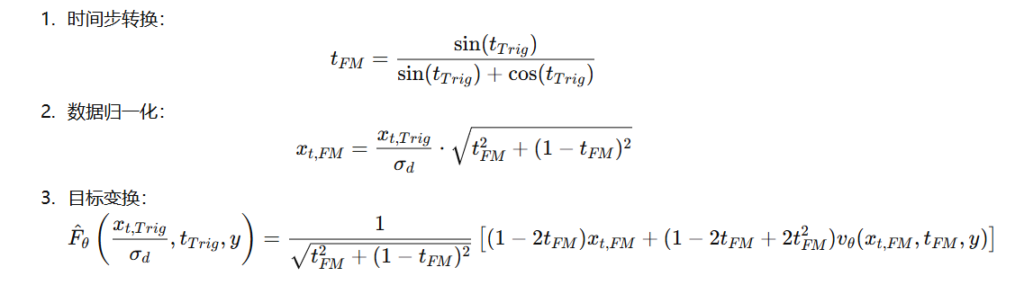
该变换在理论上是无损的,确保 TrigFlow 兼容性。
2. 稳定连续时间蒸馏
SANA-Sprint 采用 QK 归一化(QK-Norm) 和 密集时间嵌入(Dense Time Embedding) 以稳定训练:
- QK 归一化:在教师模型的自注意力和交叉注意力层引入 RMS 归一化,避免梯度爆炸。
- 密集时间嵌入:降低时间衰减幅度,减少梯度震荡,提高收敛速度。
3. 结合 LADD 进行对抗蒸馏
LADD(潜变量对抗蒸馏)通过训练 判别器 以增强生成质量:
- 采用 多判别头(Discriminator Heads) 进行潜变量监督,区别真实样本与生成样本。
- 采用 Hinge 损失:
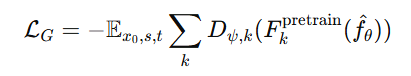
实验表明,结合 sCM 和 LADD,FID 降低 3.9,CLIP-Score 提高 0.9,显著提升生成质量。
4. 实时交互生成
SANA-Sprint 结合 ControlNet 实现 实时用户交互:
- 控制条件输入(HED 边缘检测) 作为额外输入,提高结构控制能力。
- 在 H100 上,仅需 250ms 即可生成 1024×1024 分辨率图像,支持实时反馈。
四、实验结果
1. 速度与质量对比
SANA-Sprint 实现 单步 7.59 FID / 0.74 GenEval,超越 FLUX-schnell(7.94 FID / 0.71 GenEval),推理速度提高 10 倍:
- H100 上:1024×1024 图像仅需 0.1s。
- RTX 4090 上:1024×1024 图像仅需 0.31s。
2. 消融实验
- 蒸馏策略对比:
- 仅用 sCM:FID 8.93,CLIP 27.51
- 仅用 LADD:FID 12.20,CLIP 27.00
- 结合 sCM + LADD:FID 8.11,CLIP 28.02(最佳)
- 时间步加权(Max-Time Weighting)
- 50% 权重提升生成质量,优化单步推理效果。
Code on GitHub: https://github.com/NVlabs/Sana
Project Page: https://nvlabs.github.io/Sana/Sprint/