当前“深度研究(Deep Research, DR)”型智能体在撰写复杂、长篇的研究报告时,常依赖通用的测试时(test-time)扩展算法(如CoT、best-of-n、MCTS、辩论、自反思等),但整体流程往往是“线性或并行的检索→汇总→成文”,缺乏围绕“草稿—检索—反馈—修订”的认知闭环,导致全局上下文易丢失、信息整合不及时、报告一致性与完整性不足。论文Deep Researcher with Test-Time Diffusion据此提出一种受人类写作过程启发的“测试时扩散”框架:Test-Time Diffusion Deep Researcher(TTD-DR),把“研究报告生成”拟合为扩散采样的迭代去噪过程,并在每一步由检索增强与组件级自进化共同驱动,从而提升准确性、全面性与连贯性。
论文作者为Rujun Han, Yanfei Chen, Zoey CuiZhu, Lesly Miculicich, Guan Sun, Yuanjun Bi, Weiming Wen, Hui Wan, Chunfeng Wen, Solène Maître, George Lee, Vishy Tirumalashetty, Emily Xue, Zizhao Zhang, Salem Haykal, Burak Gokturk, Tomas Pfister, Chen-Yu Lee,来自Google。
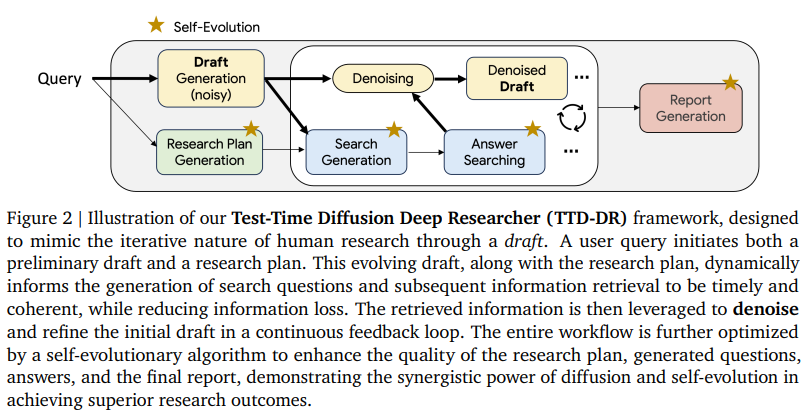
一、总体框架:TTD-DR 的“草稿—去噪—检索—自进化”
TTD-DR 的核心是“以草稿为中心”的扩散式生成:先由LLM依据用户问题产出一个“初始草稿”(相当于带噪的低分辨率草图),随后在多轮迭代中,草稿一方面被外部检索信息不断校正和充实(去噪),另一方面,框架对各子模块(规划、提问、作答、成文)施加“自进化”优化,使每一步产生的中间信息更高质、更可用,进而为后续去噪提供更好的“条件”。这一设计显著减少了跨轮次搜索中的信息丢失,并让研究方向随草稿演进而动态调整。
二、三阶段骨干智能体(Backbone DR Agent)
1)阶段一:研究规划(Research Plan)
收到用户查询后,先由单元LLM智能体生成结构化研究规划,列出完成最终报告所需的关键领域与子问题,为后续搜索提供“骨架”。该规划被存入智能体状态,并传递给子智能体。
2)阶段二:迭代检索与综合(Search & Synthesis Loop)
包含两个子智能体:
2a)检索问题生成:依据“研究规划+用户查询+历史问答与草稿状态”动态提出下一条搜索子问题;
2b)答案综合:调用可用搜索源(文中实现为Google搜索的grounding),取回文档后先做RAG式精炼,生成“可直接用于成文的要点答案”,而非简单存原文。循环迭代直至覆盖规划或达到步数上限。
3)阶段三:最终成文(Final Report)
最后由成文智能体汇总“阶段一的规划+阶段二的多轮问答摘要+草稿演进痕迹”,生成完整、连贯的最终报告。
三、组件级“自进化”(Self-Evolution)的机制与作用
自进化以并行与循环相结合的工作流对各组件输出进行“生成—评估—修订—交叉合并”:
(1)多样起点:对同一子任务(如搜索答案)采样多份不同变体(温度、top-k等扰动),扩大探索空间;
(2)环境反馈:用LLM-as-a-judge对“有用性、全面性”等打分并给出文字批评;
(3)基于反馈的修订:每个变体按批评意见迭代改进,循环若干步;
(4)交叉合并:融合多条进化路径的精华,形成更高质量的单一结果;该套路可对“规划、提问、作答与成文”各环节独立应用,从而全链条提升中间上下文质量。
经验分析显示,自进化显著提高了阶段二所生成“搜索问题与答案”的复杂度与多样性(以自动抽取的关键点数衡量),从而丰富了可用信息,解释了成文质量的提升。
四、报告级“带检索去噪”(Denoising with Retrieval)
为解决“只有在搜索全部结束后才将信息注入成文”的滞后性,TTD-DR引入基于扩散采样思想的“报告级去噪”闭环:
— 将“当前草稿”直接馈入阶段2a,生成“下一条最能弥补草稿缺口的查询”;
— 阶段2b返回综合后的新增信息;
— 用新增信息立刻修订草稿(增补事实、校对已写内容);
— 重复上述闭环若干次,直到退出条件触发;
最终,再以“所有修订历史+问答汇总”产出终稿。该算法有效地把“搜索—成文”从串行搬到“紧耦合迭代”,显著提升“早期信息的及时保存与利用”,并减少跑偏。
五、实现与测试时扩展策略
实现方面,作者使用Google ADK编排工作流,基础模型为Gemini-2.5-pro,并将“带检索去噪”的最大步数固定为20;阶段2b的RAG以Google Search grounding实现。
六、评测方案与指标
针对长文本输出与复杂智能体轨迹的难评特性,作者采用“人类标注+LLM裁判对齐”的评估:
— 侧重两项单边质量指标:有用性(满足意图、易读连贯、准确、语言得体)与全面性(关键信息不遗漏);
— 采用成对偏好(side-by-side)作为主观比较范式,并校准LLM-as-a-judge使其与人评一致;
— 对于有标准答案的短式多跳任务(如HLE/GAIA),以正确率衡量。
七、数据集与任务
两大类任务:
1)长篇综合报告生成(LongForm Research 与 DeepConsult);
2)需要大量检索与推理的多跳问答(HLE、GAIA)。作者还从HLE中筛出“更依赖检索”的子集HLE-search(200个问题)以更契合研究目标。
八、主要结果(对比与消融)
1)总体对比:
相对OpenAI Deep Research,TTD-DR在两项“长篇研究报告”任务上分别取得69.1%与74.5%的胜率;在需要广泛检索的三项“短式答案”任务上,TTD-DR在HLE-Search、HLE-Full、GAIA上分别高出4.8%、7.7%与1.7%正确率,显示出在检索+推理型任务上的优势。
2)消融分析:
— 仅使用强基座LLM(Gemini-2.5-pro/flash)且不带智能体工作流与检索,其在HLE-Search上的正确率很低;加入简单检索工具(simple RAG)虽有提升,但仍不及领先DR系统;
— 引入“骨干DR智能体”后进一步提升;
— 加上“自进化”后,在两项长文任务上已超过OpenAI DR;
— 最终叠加“带检索去噪”后,在所有基准上达到最佳,并在“性能—时延”帕累托前沿上呈现更高的“单位时延收益”。
九、机理剖析与可解释性发现
(1)自进化为何有效:它在阶段二显著增加“问题与答案”的关键点数量与多样性,扩展了信息覆盖深度与广度,为后续草稿去噪提供更“浓缩、结构化”的知识源。
(2)带检索去噪的关键贡献:与仅用自进化相比,它能在早期就把更多“最终报告所需信息”写回草稿;作者给出的归因度量显示,在第9步时已覆盖终稿信息的一半以上,同时以更少步数取得更高的对比胜率——说明“让草稿反过来驱动检索焦点”能显著提高搜索的“新颖度与有效性”。
十、与既有深度研究系统的关系
与HuggingFace Open DR、GPT Researcher、Open Deep Research等“逐节独立检索再拼接”的做法不同,TTD-DR避免把搜索割裂到每个小节,从而保持全局上下文的一致,且用RAG先加工文献再入库,减少冗余与噪声积累。
十一、贡献总结
1)提出“测试时扩散”范式,把长篇研究报告生成视为“草稿驱动的去噪”过程;
2)在不依赖专有重工具的前提下,仅以通用搜索工具验证方法有效性;
3)构建更严格的评测方案(人评校准的LLM裁判+多维指标),并在多个真实复杂任务上取得SOTA或可比领先;
4)系统性消融证明“自进化”和“带检索去噪”双策略的互补增益与更优的“性能—时延”权衡。
十二、局限与展望
— 目前侧重“搜索工具”场景,尚未纳入浏览、编程等更多工具协同;
— 未涉及“智能体训练/微调”(如RL/指令微调)以进一步提升策略质量;
— 未来可探讨多模态信息、跨源证据一致性约束,以及把“去噪步数与搜索预算”做成自适应控制。
十三、方法复现要点(实践清单)
— 工作流:按“规划→(提问↔作答)×N→成文”的骨干框架搭建;
— 草稿机制:任何时刻保持“可修订草稿”作为全局条件,所有检索结果先RAG成要点再写回草稿;
— 自进化:对“规划/提问/作答/成文”分别做“多样采样—LLM裁判—迭代修订—合并”;
— 停止准则:设定最大去噪步数与覆盖阈值,并监控草稿“新增有效信息密度”的边际收益;
— 评测:使用“有用性+全面性”的并排对比与“可校准的LLM裁判”,短式任务则用标准抽取与匹配评估。
十四、面向产业场景的价值
对于需要“强检索+多跳推理+长篇报告”的场景(咨询、投研、医药、技术情报、政策评估等),TTD-DR的“草稿驱动检索”与“组件自进化”能在有限预算下更快收敛到“正确且完整”的结论,并以可追溯的草稿演化轨迹,提升可解释性与复核效率。