Human I/O是一种统一的方法,它使用自我中心视觉(egocentric vision)、多模态感知(multimodal sensing)和大语言模型推理(LLM reasoning)来检测情境性障碍,并评估用户在特定情境下使用手、视觉、听觉或语音进行交互的能力。
我们每天都会遇到一些暂时性的挑战,这些挑战会影响我们应对不同情况的能力。这些挑战被称为情境性诱发的障碍和残疾(Situationally Induced Impairments and Disabilities, SIIDs),它们可能由各种环境因素引起,如噪音、光线、温度、压力,甚至是社会规范。例如,想象一下你在一个嘈杂的餐馆里,因为听不到电话铃声而错过了一个重要的电话。或者想象一下你在洗碗时试图回复一条短信,你的湿手和正在进行的任务使得打字变得很困难。这些日常场景展示了我们的环境如何暂时减少我们的身体、认知或情绪能力,导致令人沮丧的体验。
此外,情境性障碍变化很大且频繁变化,这使得难以应用一种通用的解决方案来实时满足用户的需求。例如,考虑一个典型的早晨日常:刷牙时,用户可能无法使用语音命令与智能设备互动;洗脸时,可能很难看到和回复重要的短信;使用吹风机时,可能很难听到任何电话通知。虽然各种努力已经为这些特定情境创造了针对性的解决方案,但为每一种可能的情境和挑战组合手动设计解决方案并不现实,也难以大规模应用。
获得CHI 2024最佳论文荣誉提名奖的“Human I/O: Towards a Unified Approach to Detecting Situational Impairments”论文介绍了一个用于检测SIIDs的通用且可扩展的框架。与其为洗脸、刷牙或使用吹风机等活动设计单独的模型,Human Input/Output(Human I/O)普遍评估用户的视觉(例如阅读短信、观看视频)、听觉(例如听通知、电话)、语音(例如进行对话、使用Google Assistant)和手部(例如使用触摸屏、手势控制)输入/输出交互通道的可用性。我们描述了Human I/O如何利用自我中心视觉、多模态感知和大语言模型(LLMs)的推理,在32种不同情境的60个现实世界自我中心视频录制中实现了82%的可用性预测准确率,并在与10名参与者的实验室研究中验证了其作为交互系统的有效性。
Authors: Xingyu Bruce Liu, Jiahao Nick Li, David Kim, Xiang ‘Anthony’ Chen, Ruofei Du
一、研究方法
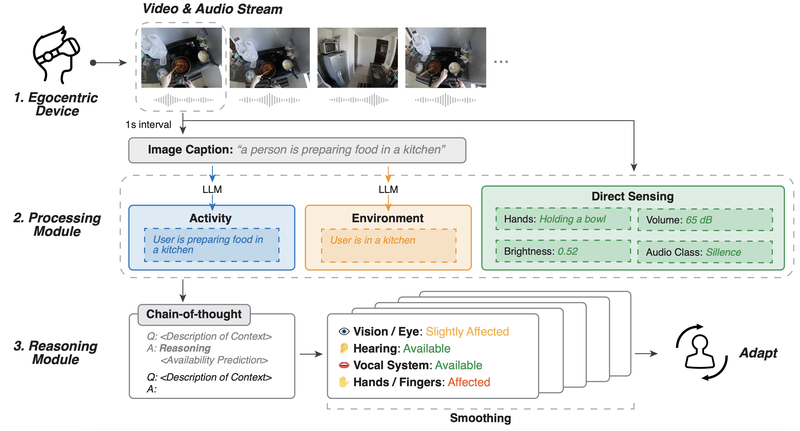
Human I/O系统包含三个主要部分:
- 数据采集:使用自我中心视角的相机和麦克风捕捉视频和音频流。
- 处理模块:处理视频和音频数据,生成活动和环境的描述,并通过直接感知评估特定通道的状态。
- 推理模块:利用大语言模型(LLM)进行推理,预测视觉、听觉、声音和手部通道的可用性。
二、研究结果
- Human I/O在60个现实世界视频场景中展示了0.22的平均绝对误差和82%的准确率。
- 系统通过用户研究展示了其在实际应用中的有效性,显著减少了用户在面对SIIDs时的努力,提高了用户体验。
三、相关工作
本文的研究基于以往在情境感知计算、自我中心视觉、大语言模型推理、活动和环境感知等领域的研究成果。现有系统多集中于特定情境的检测,如行走、驾驶、醉酒、分心等,但难以扩展到实时应对多种情境障碍。
四、技术框架
Human I/O使用自我中心视角的相机和麦克风捕捉用户的第一人称视角数据,处理这些数据以生成文本描述,然后利用大语言模型进行推理,预测人类输入/输出通道的可用性。系统使用了一种四级评分标准(可用、轻度受影响、受影响、不可用)来衡量通道的可用性。
五、用户研究
通过与10名参与者的用户研究,研究结果表明Human I/O系统在处理SIIDs时显著减少了用户的努力、精神、体力和时间需求,并改善了用户体验。
六、未来工作
未来的研究可以扩展Human I/O系统,通过引入更多的感知技术(如眼动追踪、热成像、深度感知等)和开发更大规模的数据集,以提高系统的准确性和实时性。此外,研究还应探索个性化的适应策略和情境感知网络的开发,以实现更广泛的应用场景。
七、结论
Human I/O系统展示了一种统一的、基于人类输入/输出通道可用性的SIIDs检测方法。通过结合自我中心视觉、多模态感知和大语言模型推理,该系统在多种日常活动中展示了其有效性和潜力,为未来的情境自适应和可访问互动系统铺平了道路。
P.S., 基于此论文成果的源码:HumanIO Source Code on GitHub