随着人工智能(AI)和机器学习(ML)的迅猛发展,数据科学领域取得了显著进展,广泛应用于机器翻译、推荐系统、社会模拟和医学诊断等领域。然而,伴随数据日益异构与高维化,数据科学任务的复杂性也持续上升,需要更高水平的专业知识和工程能力。尽管Kaggle等众包平台部分缓解了这一挑战,但高水平机器学习工程(MLE)任务仍然极度依赖手工迭代与经验调优,效率较低。
大语言模型(LLMs)具备强大的代码生成与推理能力,被认为能有效探索大规模设计空间,自动化MLE流程。但实际情况是,即使最先进的LLMs在MLE-bench这类现实竞赛基准中,也仅能实现人类专家表现的一小部分。为解决这一差距,论文R&D-AGENT: AN LLM-AGENT FRAMEWORK TOWARDS AUTONOMOUS DATA SCIENCE提出了R&D-Agent框架,一个系统化、可扩展、解耦合的MLE智能体架构,该架构可将AI辅助的机器学习工程推进至更高的自动化层次。
论文作者为Xu Yang, Xiao Yang, Shikai Fang, Yifei Zhang, Jian Wang, Bowen Xian, Qizheng Li, Jingyuan Li, Minrui Xu, Yuante Li, Haoran Pan, Yuge Zhang, Weiqing Liu, Yelong Shen, Weizhu Chen, Jiang Bian,来自微软。
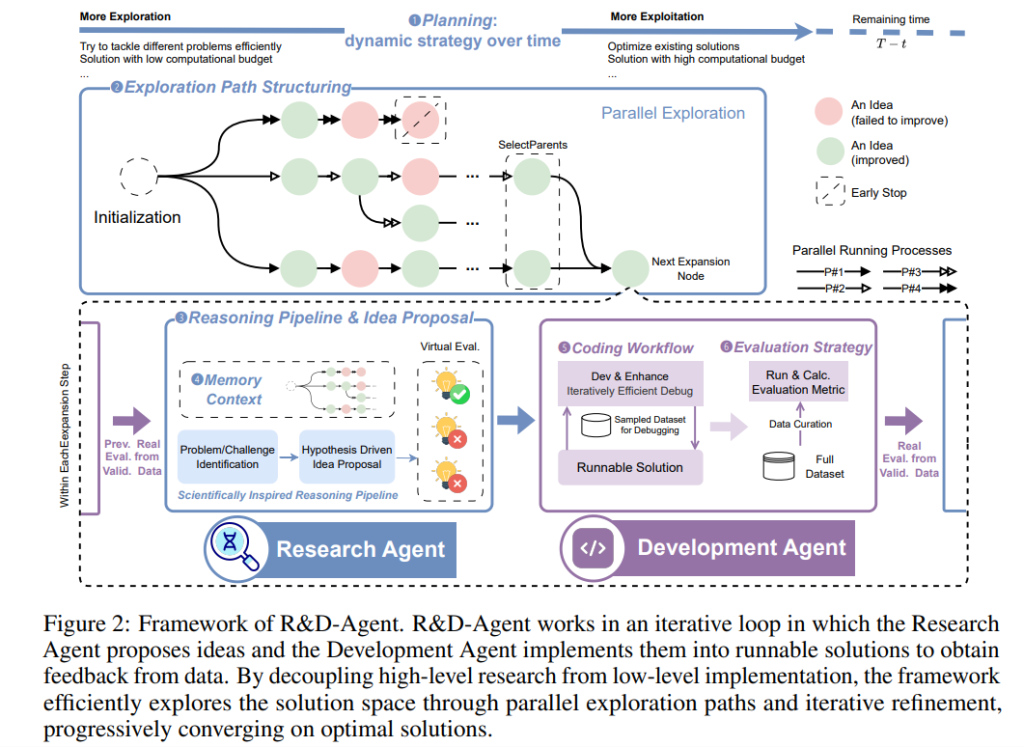
一、R&D-Agent 框架概述
R&D-Agent 借鉴人类数据科学家的工作流程,将整个机器学习工程过程划分为两个核心阶段和六个模块组件:
- 研究阶段(Research Phase)
- ❶ 规划(Planning):动态调整探索策略与资源分配。
- ❷ 探索路径结构(Exploration Path Structuring):决定探索策略是链式还是树状结构。
- ❸ 推理流程(Reasoning Pipeline):系统地生成与筛选候选研究思路。
- ❹ 记忆上下文(Memory Context):组织历史知识以供重复利用与知识迁移。
- 开发阶段(Development Phase)
- ❺ 编码流程(Coding Workflow):将思路转化为可运行、可调试的代码。
- ❻ 评估策略(Evaluation Strategy):提供鲁棒、稳定的一致性评估手段。
整个流程形成一个R&D循环,研究代理生成想法,开发代理实现、验证与反馈,从而逐步逼近最优解。
二、关键模块设计(人类专家启发)
- 规划模块(MD-Planning):借鉴人类的科学探索路径,前期聚焦轻量探索与新颖方案,后期逐渐引入复杂方法(如集成、交叉验证)以精细优化。
- 探索路径结构(MD-Exploration Path):采用DAG结构多路径并行探索,前期广度最大化,后期局部贪心优化,同时合并优质解。
- 多步推理流程(MD-Scientific Reasoning Pipeline):模仿科学推理,先分析问题,再提出假设、评估代价与收益,并引入LLM评分的虚拟评估来筛选最优idea。
- 协作式记忆上下文(MD-Memory Context):跨分支共享高质量思路,通过概率内核与LLM决策进行信息交互,既促进收敛又保留多样性。
- 高效编码流程(MD-Coding Workflow):先在采样子集上快速原型迭代,验证通过后再用全数据训练,极大缩短开发周期,提升试验效率。
- 聚合评估策略(MD-Evaluation Strategy):统一验证集划分、聚合多个子路径结果,保证评估一致性与公平性,减少偶然误差与过拟合风险。
三、实验设计与结果分析
实验使用MLE-Bench基准(基于真实Kaggle竞赛)进行评估,对比主流系统如ML-Master、AIDE等,并使用两种配置:GPT-5独立部署与o3(Research)+ GPT-4.1(Development)混合架构。
主要发现如下:
- R&D-Agent(GPT-5)在“任意奖牌率(Any Medal Rate)”上达35.1%,显著优于ML-Master(29.3%),实现SOTA。
- 混合模型配置在资源受限情况下也达到了29.7%,说明框架设计优于纯模型替换。
- 在任务复杂度不同的分组中,R&D-Agent在所有复杂度(Low==Lite, Medium, High)上均表现优异。
四、消融实验
为验证各组件的贡献,作者对六个核心模块逐一进行消融实验。研究阶段四个模块中:
- 去除规划模块:任意奖牌率下降24%,因缺乏时间动态适应。
- 去除探索路径结构:下降28%,R&D循环次数减半,表明树状结构是关键。
- 去除多步推理:下降24%,改进率骤降至23%,显示简单单步推理无法有效提升质量。
- 去除协作记忆:下降较小(9%),但仍影响跨分支知识共享与快速收敛。
开发阶段中:
- 去除编码流程:奖牌率下降至24%,采样调试法优于全数据调试是关键突破。
- 去除评估策略:初期无明显影响,但随着复杂解的出现,奖牌率下降至30.7%,表明系统性评估在后期至关重要。
五、额外分析与扩展结果
- 不同LLM配置对比:混合架构(o3+GPT-4.1)优于单模型配置,验证“研究-开发”分工下的模型互补性。
- RAG(检索增强)引入反而在简单任务上降低表现,表明“是否使用RAG”应按任务难度选择,RAG非万能增益。
- 与闭源系统对比:R&D-Agent在低资源下(12h、1×V100 GPU)达到与InternAgent等闭源系统相近或更优的水平,凸显其实用性与可复现性。
- 计算效率:平均每场比赛花费约21美元,远低于传统AutoML方案,具备极高性价比。
六、结论
R&D-Agent将机器学习工程代理的设计从手工调参转变为系统性、可复现、可组合的探索过程。其核心创新在于明确区分研究与开发两个阶段,并在六个组件上系统化架构设计,结合人类专家工作流,形成高效并行、可复用、易调试的通用框架。
论文通过详尽的实验与消融分析,验证了每个模块在提升效率、准确性与泛化能力上的作用。R&D-Agent不仅刷新了MLE-Bench基准的最佳成绩,也为后续研究者提供了标准化、模块化的开发平台,极大降低了进入门槛,有望推动AI自主科学研究的发展。
R&D-Agent on GitHub: https://github.com/microsoft/RD-Agent