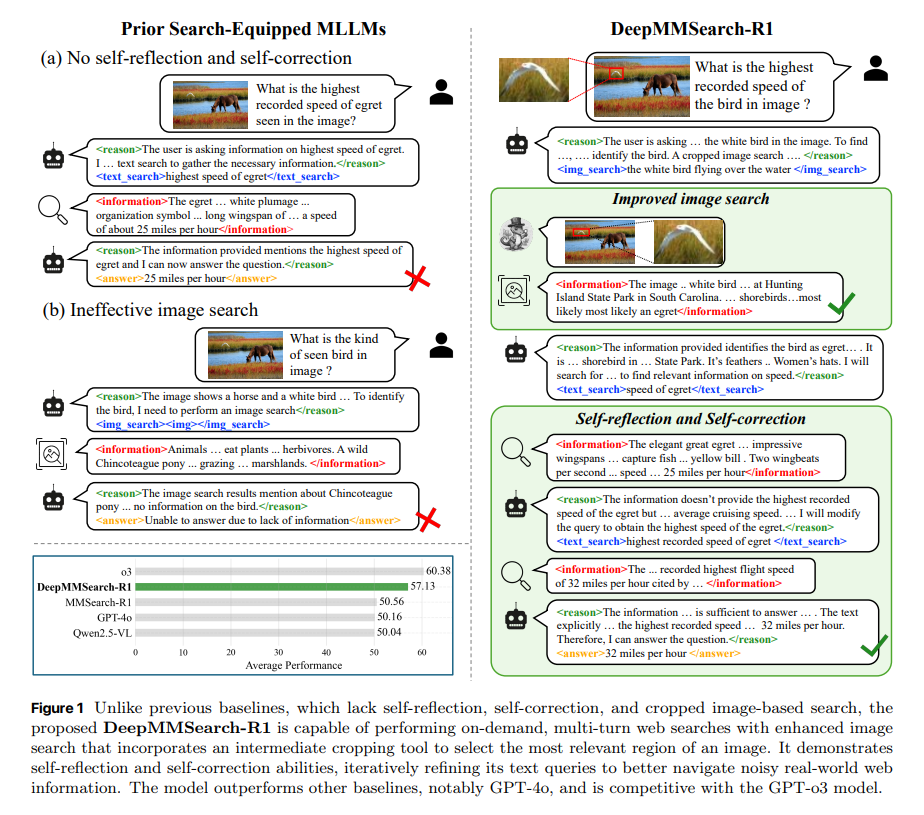
现实应用中的多模态大模型(MLLM)在知识密集与信息检索型视觉问答任务上常受限于静态训练语料与长尾知识分布,难以及时获取最新事实与开放世界知识;传统RAG与“搜索代理”方案又常存在检索管线僵硬、查询构造欠佳、过度检索与噪声注入等问题。论文DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search提出的 DeepMMSearch-R1 针对这些痛点,强调“按需、多轮”的网页搜索、基于检索反馈的自反思/自纠错,以及以“裁剪—检索”协同的图像检索,从而在真实网络环境中更稳健地完成多模态信息寻址与推理。
论文作者为Kartik Narayan, Yang Xu, Tian Cao, Kavya Nerella, Vishal M. Patel, Navid Shiee, Peter Grasch, Chao Jia, Yinfei Yang, Zhe Gan,来自苹果公司。
一、方法总览
DeepMMSearch-R1 的核心是一个“多工具、多轮交互”的检索增强推理循环:
1)文本搜索:模型根据问题与已获信息动态生成/改写文本查询,多轮迭代以缩小检索范围,实现自反思与自纠错;
2)图像裁剪+图像搜索:先由模型生成“指代表达”(referring expression),再用 Grounding DINO 对输入图像进行定位与裁剪,最后以裁剪图作为检索键提升相似图与网页上下文的相关性与纯度;
3)两阶段训练:先在新构造的数据集上进行监督微调(SFT),再用在线强化学习(GRPO)优化工具选择与搜索效率。
二、数据集:DeepMMSearchVQA
作者构建了 DeepMMSearchVQA,用于教授模型“何时搜、搜什么、用哪种工具、如何融合检索信息并决定下一步动作/作答”。该数据集以 InfoSeek 为基语料,借助 Gemini-2.5-Pro 生成多轮对话,样本中显式包含工具标签(如 <text_search>、<img_search>、<answer>)与检索信息块 <information>,并区分“整图检索”与“裁剪检索”;最终筛选出约 1 万个覆盖多知识门类、且在“需检索/免检索”问题上约 50:50 平衡的 VQA 样本用于 SFT。
三、训练策略:SFT + 在线GRPO
(1)SFT:以 Qwen2.5-VL-7B-Instruct 为基座,仅微调 LLM 模块并冻结视觉编码与投影层,配合 LoRA(r=8)提升参数效率。训练目标为标准自回归 LM 损失,并对检索回传文本进行损失屏蔽,聚焦于“推理与工具调用格式”的学习。
(2)GRPO:从 SFT 检点出发,在真实工具回路中多样化生成多条轨迹,以组内相对优势为核心的 GRPO 目标稳定优化;奖励由“答案正确性”与“格式合规”组成,并加入 KL 正则约束策略漂移。训练还限制工具调用次数与轨迹长度,以鼓励“准确—高效”的策略。
四、多模态搜索流水线与工具协作
系统包含三类工具与两个“摘要”步骤:
1)文本搜索:内部Web索引→Top-k 文档→LLM摘要→回灌上下文;
2)图像搜索:整图或裁剪图→相似图与页面元信息→LLM摘要→回灌上下文;
3)裁剪(Grounding DINO):根据模型生成的指代表达定位最相关区域并裁剪,缓解整图噪声干扰。该设计显著提升检索有效性并减少无关噪声进入上下文。
五、实验设置与评价
作者设计了四类评测工作流:① 直接作答;② 刚性RAG两步(先图搜后文搜,每步固定一次);③ 提示式搜索代理(测试时通过提示引导使用工具);④ 具备网页搜索能力的MLLM(可多轮按需搜索)。评测数据覆盖 InfoSeek、DynVQA、SimpleVQA、Enc-VQA、OK-VQA、A-OKVQA 等;指标采用“LLM 评审”框架(gpt-5-chat-latest 作为裁判)以更好刻画开放式多模态回答的语义正确性。
六、结果与分析
1)总体效果:DeepMMSearch-R1-7B(RL)在六项基准上平均 57.13 分,显著优于提示式搜索代理与刚性RAG流程,接近 o3 的水平;同一模型在 SFT→RL 过程中进一步提升,体现在线上强化学习阶段对“何时搜/如何搜”的策略优化价值。
2)RAG与代理对比:刚性两步RAG在 OK-VQA、A-OKVQA 上明显劣于直接作答,原因在于这两类数据多为“可免检索”问题,强行引入网络检索反而带来噪声;提示式搜索代理虽更稳,但仍不及“具备搜索能力的MLLM”,说明仅靠提示在测试时学会用工具不如训练时显式对接工具与结构化协议。
3)裁剪检索与自反思/自纠错:允许多次文本检索与裁剪式图像检索带来稳定增益,尤其对需要锁定单一视觉实体的问题更明显;同时,SFT→RL 后,模型在必要时才进行裁剪,减少了不必要的裁剪调用(DynVQA −36.81%、OK-VQA −34.86%),但整体性能仍提升,体现“更少但更准”的工具使用。
4)数据配比与抽样策略:SFT 数据中“需检索:免检索”保持约 50:50 最优;并且按知识门类均匀采样优于随机抽样,能更好蒸馏“何时搜/如何搜”的行为分布。
5)一般VQA能力保持:在 OCRBench、MMVet、AI2D、MathVista、MMBench、DocVQA、InfoVQA 等通用基准上,DeepMMSearch-R1-7B(RL)与基座 Qwen2.5-VL-7B 表现相当,说明 LoRA-SFT 与带 KL 的在线 GRPO 并未牺牲通用多模态理解能力。
七、创新点与相对位置
1)“裁剪—检索”一体:区别于仅支持整图检索的多模态检索模型,引入指代表达+Grounding DINO 的中间裁剪工具,降低背景噪声对图搜的干扰;
2)自反思/自纠错的多轮文本检索:用检索摘要反馈来迭代修正查询,缓解“一次定型”的查询脆弱性;
3)数据与训练一体化:以结构化工具标签与信息块构成的多轮 VQA 语料(DeepMMSearchVQA)配合 SFT→GRPO,使“会用工具”的能力成为模型参数的一部分,而非仅靠提示工程。
八、局限性与潜在风险
1)对外部基础设施依赖:实际效果受搜索API与索引覆盖度、摘要质量影响;
2)检索偏见与版权合规:自动摘要可能放大偏差或旧闻,且涉及内容来源合规与可追溯;
3)多轮成本与时延:尽管 RL 降低了不必要工具调用,但在高并发应用中仍需精细的调用预算与缓存策略。
九、对工程实践的启示
1)把“是否检索”的决策显式化:在业务层接入策略(如可置信度阈值、问题类别白名单)以避免对“免检索问题”强行检索造成的噪声;
2)优先做“指代—裁剪—检索”的图搜通路:对“识别某一局部实体并补全知识”的场景(商标、器件、徽标、动植物)尤为关键;
3)检索结果二次蒸馏:将 Top-k 结果做结构化摘要(字段化要点、证据片段与来源)再回灌,控制上下文污染;
4)数据合成与比例控制:自建指令数据时维持“需/免检索=1:1”与知识门类均衡,有助于学到更“经济”的工具使用策略;
5)联训与守护:采用参数高效微调(LoRA)与 KL 约束的在线优化,可在不破坏通用能力的前提下稳步注入工具使用技能。
十、结论
DeepMMSearch-R1 将“多轮自反思的文本检索”与“裁剪先行的图像检索”纳入统一的训练与推理框架,并通过 SFT→GRPO 的两阶段训练把“会用工具”的策略固化进模型,在多项知识密集型基准上超越开源基线、接近强闭源模型,且普适VQA能力基本保持。它为“面向真实网页的多模态检索—推理一体化”提供了可复用范式。