大型语言模型(LLM)驱动的智能体正被用于长期、持续的真实世界任务(如网页浏览、软件工程自动化),但主流智能体在“跨任务学习”上存在明显短板:它们往往把每个任务当作孤立事件处理,既无法从历史交互中汲取可迁移的推理策略,也难以避免重复犯错。这种“无记忆或弱记忆”的模式不仅浪费了宝贵的经验,还使智能体缺乏随时间自我进化的能力。因此,论文ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory提出要构建一种“面向推理的记忆”机制,使智能体能够在测试期连续任务流中,主动从成功与失败的经历里提炼通用化的策略,并在后续任务中有效调用与迭代,从而实现“边测试、边进化”的能力。
论文作者为Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, Tomas Pfister,来自University of Illinois Urbana-Champaign, Yale University和Google。
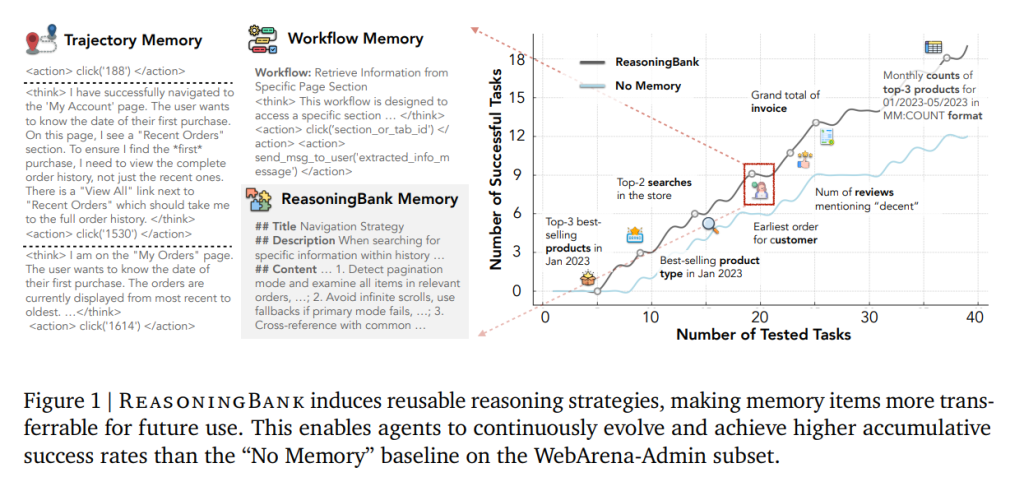
一、核心贡献与整体框架
论文提出的核心是 ReasoningBank 与与之耦合的记忆感知测试期扩展 MaTTS(Memory-aware Test-Time Scaling):
1)ReasoningBank:把智能体在交互轨迹中的“思考与行动”蒸馏为结构化的“策略级记忆项”(title/description/content 三段式),既保留成功经验中的有效套路,也显式吸纳失败经历中的“防错启示/反事实线索”。与只存原始轨迹或只存成功流程的以往方法不同,它强调提炼可迁移的“高层推理模式”。
2)MaTTS:在测试期对同一任务“加深探索”的同时,让 ReasoningBank 主导记忆的生成与筛选,形成“探索→对比/自纠→高质量记忆→更有效探索”的正反馈回路。作者分别给出并行扩展(多条并行轨迹的自对比)与串行扩展(同一轨迹的多轮自修正)两种实现。
3)实验上横跨 WebArena、Mind2Web 与 SWE-Bench-Verified,多种基座模型(Gemini-2.5/Claude-3.7),在成功率与交互步数两方面同时获益,并展示了“记忆质量 × 测试期扩展规模”的协同效应。
二、方法细节:ReasoningBank 的三阶段闭环
1)记忆检索(Memory Retrieval):面对新任务,先用当前上下文从 ReasoningBank 中做嵌入召回,选取 top-k 相关记忆项,作为系统指令注入到策略生成中,帮助决策“少走弯路、规避既知坑点”。
2)记忆构建(Memory Extraction):任务完成后,采用“LLM-as-a-judge”在无标签条件下自评轨迹成败;对成功轨迹抽取“有效策略”,对失败轨迹抽取“防错/边界/反例”提示;同一轨迹可抽取多条记忆项以覆盖不同维度的策略信号。
3)记忆固化(Memory Consolidation):将新抽取的记忆项简单追加进 ReasoningBank,持续滚动积累,形成“取用—生成—回灌”的闭环。作者刻意保持这一管线朴素,以突出策略级记忆本身的贡献。
三、方法细节:MaTTS 的两种记忆感知扩展
1)并行扩展(Parallel Scaling):针对同一查询并行生成多条轨迹,利用“自对比”在多解之间归纳共识策略、剔除偶然性路径,从而产出更可靠的记忆。该流程与 ReasoningBank 交替:先用记忆引导多样探索,再用多轨对比反哺更强记忆。
2)串行扩展(Sequential Scaling):在单条轨迹上做多轮自我修正(self-refine),把中间的检视、纠偏、假设检验等“思维痕迹”也作为记忆信号保存,丰富策略粒度。扩展因子 k 分别表示并行轨迹数或串行自修次数。
四、实验设置与对比基线
基准:WebArena(多域网页操作,去除了地图域以保证可用性)、Mind2Web(跨任务/跨站点/跨领域泛化),SWE-Bench-Verified(仓库级问题修复)。
基座模型:Gemini-2.5-flash / -pro 与 Claude-3.7-sonnet。
对比:无记忆(No Memory)、轨迹记忆(Synapse)与流程记忆(AWM/Agent Workflow Memory)。
指标:成功率(SR/SSR/Task SR 等)与交互步数(Step)。
五、主要结果与现象
1)整体有效性与效率
• WebArena:ReasoningBank 在三个基座上总体 SR 分别较无记忆提升 +8.3、+7.2、+4.6,同时平均步数显著降低(例如在多个子集上较 No Memory 与其他记忆基线各减少约 1.0–1.6 步)。
• SWE-Bench-Verified:Resolve Rate 提升(例如 Gemini-2.5-pro:57.4 vs 54.0),步数进一步下降(19.8 vs 21.1),说明策略级记忆能减少“无效尝试”。
• Mind2Web:在跨任务、跨站与跨领域三种泛化设定下,ReasoningBank 在 EA/AF1/SSR/SR 指标上均有增益,跨领域增益最为显著,体现其“高可迁移策略”的价值。
2)MaTTS 的扩展收益
• 随着扩展因子 k 增大,并行与串行两种 MaTTS 的成功率总体上升;在 k=5 时,并行可达 55.1、串行 54.5。相比“无记忆扩展”,MaTTS 的增长更稳定、更可观;相比“无聚合的朴素 TTS(相当于把多轨迹各自独立记忆化)”,MaTTS 也持续占优,这表明“基于对比/自修的记忆聚合”至关重要。R
• 小规模扩展时串行略占优,但随着 k 增大并行更能持续产生多样化探索与更强的对比信号,因此在高 k 区间反超。
3)记忆 × 扩展的协同
• 更好的记忆带来更强的 Best-of-N(BoN):无记忆时扩展几乎不涨或波动;Synapse/AWM 有一定提升;ReasoningBank 的提升最大(例如 BoN 从 49.7 升至 52.4)。
• 扩展反哺记忆质量:以 Pass@1 衡量“记忆固化后的平均轨迹质量”,弱记忆在扩展后甚至下降(噪声大于信息),而 ReasoningBank 唯一实现正向提升(49.7→50.8),说明只有“高质量策略记忆”才能把扩展生成的多样轨迹转化为有效的对比信号,形成良性循环。
六、深入分析:为何“失败也应被记忆”
作者做了“只用成功轨迹 vs 同时纳入失败轨迹”的消融。结果显示:基于成功轨迹的传统方法(Synapse/AWM)在加入失败数据后收益有限甚至退化;而 ReasoningBank 通过专门的失败蒸馏策略,能把失败转化为“边界/防错/反事实”知识,成功率从“仅成功”条件下的 46.5 进一步提升到 49.7。这为“让智能体学会不去做什么”提供了实证。
七、效率视角:减少的是“冗余探索”,而非“草率放弃”
将步数分别在“成功用例/失败用例”上统计,ReasoningBank 在四个 WebArena 子域均显著减少成功用例的平均步数(最高减少 2.1 步,约 26.9% 相对下降),而对失败用例的步数影响较小。这表明它主要是在“找对方向后少走弯路”,而不是“更早放弃”。
八、与现有记忆范式的差异与优势
1)相对“原始轨迹记忆”(重放长上下文):ReasoningBank 通过结构化的策略项,避免了长文本检索/注入的噪声与成本,更利于泛化与压缩。
2)相对“流程/工作流记忆”(只存成功模块化流程):它显式吸纳失败信号,且抽取的是“可组合的策略与判断要点”,不局限于固定流程,有利于不同网站/仓库/问题域间的迁移。
3)与测试期扩展协同:策略记忆提供了“引导探索的先验”,扩展产生“对比学习的多样样本”,二者互促,形成新的扩展维度——“经验驱动的扩展”。
九、潜在局限与开放问题
1)LLM-as-judge 的自评偏差:在无标注场景依赖模型自判,可能引入系统性偏差,进而影响记忆的纯度;后续可考虑多评审、多视角一致性或轻量外部验证器。
2)记忆库规模与检索:随着任务流增长,记忆项数量膨胀,需要更强的索引、去冗、聚类与策略元学习(例如根据任务域自适应选择“失败防错”类记忆的权重)。
3)对环境漂移/站点差异的鲁棒性:策略层记忆虽可迁移,但页面结构、DOM 可访问性与代码仓生态差异仍会造成“策略-动作落差”,需要与结构化工具观测、程序化技能诱导共同演进。
4)计算-收益曲线:并行/串行扩展都要付出额外算力,何时停止、如何自适应选择 k、如何在“快速解/深度探”间平衡,仍需更系统的代价感知调度。
十、实践落地建议(从工程视角)
1)记忆项模板化:强制三段式(标题/一句话摘要/要点清单),要点尽量写成“条件-动作-检查”结构,便于检索与注入。
2)失败优先的安全栅:为每个常见失败态(如“只看最近订单”“错把分页为无限滚动”)建立防错记忆,作为系统提示前缀优先注入。
3)扩展因子自适应:小 k 先用串行(低成本收敛/纠偏),当不再产生新洞见时切换到并行以引入多样性。
4)记忆健康度度量:对记忆项维护“命中率/触发后成功率/误触发率/时效性”等指标,定期自动合并相似项、淘汰陈旧项。
十一、学术与产业价值
论文把“记忆质量”纳入“扩展维度”的第一性要素,跳出了单纯堆算力或仅在参数规模上的扩展逻辑,提供了一个“经验-对比-记忆”的可操作闭环。它在网页智能体与代码智能体两个典型场景同时验证,说明这种“策略级记忆 + 测试期扩展”的范式有望成为通用的智能体自演化路线。
十二、结论
ReasoningBank 通过把成功与失败共同蒸馏为“可迁移的策略记忆”,并与 MaTTS 的并行/串行扩展形成正反馈,显著提升了智能体在连续任务流中的有效性与效率;更重要的是,它证明了“记忆驱动的经验扩展”这一新范式的可行性:高质量记忆让扩展更有效,多样扩展又锻造更高质量记忆,最终使智能体在无监督的测试期自然涌现出更复杂、更稳健的推理行为。