论文Optimizing Audio Augmentations for Contrastive Learning of Health-Related Acoustic Signals(《对比学习健康相关声学信号的音频增强优化》),研究的主要目标是改进健康相关声学信号(例如咳嗽和呼吸声)在对比学习中的表现,具体是通过优化音频增强策略来实现的。
作者为Louis Blankemeier, Sebastien Baur, Wei-Hung Weng, Jake Garrison, Yossi Matias, Shruthi Prabhakara, Diego Ardila, Zaid Nabulsi,均来自Google Research。
论文概要内容如下:
一、背景与动机
健康相关的声学信号如咳嗽声和呼吸声对于医学诊断和健康监测有着重要意义。然而,目前大多数机器学习模型在处理这些信号时,通常是针对特定任务进行训练的,这限制了它们在不同医疗应用场景中的通用性。为了克服这一问题,论文提出采用自监督学习框架(SimCLR)和Slowfast NFNet主干网络进行对比学习,旨在开发适用于多种健康声学任务的通用表示。
二、研究目标
论文的核心研究问题是如何优化Slowfast NFNet在健康声学信号对比学习中的音频增强策略。论文通过深入分析多种音频增强策略,发现合适的增强策略可以显著提升Slowfast NFNet音频编码器在多种健康声学任务中的表现。
三、方法
论文的研究分为三个主要阶段:
- 确定单个增强策略的最佳参数:通过网格搜索(grid search)找到每个增强策略的最优参数。
- 探索增强策略的组合:研究将一种或两种增强策略连续应用时的效果。
- 与现有最先进的音频编码器进行比较:将优化后的Slowfast NFNet模型与其他音频编码器在五个数据集上的21个二元分类任务上进行比较。
在这些实验中,论文使用了SimCLR自监督对比学习框架,并对多种音频增强策略进行了系统性探索,如裁剪和填充、噪声添加、布朗带速率(Brownian tape speed)、音频缩放、音高移位、时间拉伸、循环时间移位和SpecAugment等。研究发现,通过组合这些增强策略,可以产生协同效应,使模型表现优于单独应用每种策略的效果。
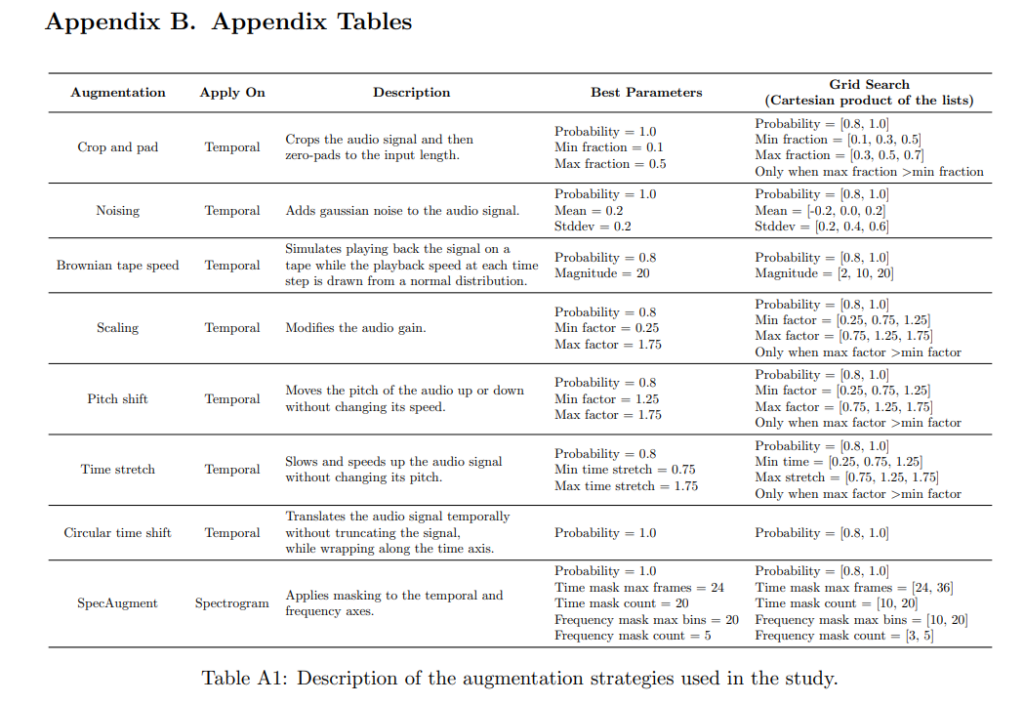
四、数据集
论文使用了一个来自YouTube的非语义声音数据集(YT-NS)进行训练,包含约142,000小时的音频数据,这些数据经过过滤,包含咳嗽声、讲话声、笑声等健康相关的声学信号。为了评估模型的性能,论文使用了五个公开数据集,包括FSD50K、Flusense、PSG、CoughVID和Coswara。
五、实验结果
研究表明,组合使用增强策略往往比单独使用某一增强策略效果更好。具体来说,研究发现“循环时间移位”结合“时间拉伸”是最有效的两步增强策略,尽管单独使用时这两种策略的效果不如SpecAugment,但它们组合后表现出显著的协同效应。最终优化后的SimCLR模型在多个下游任务中表现出与最先进的音频编码器相当甚至更优的性能。
六、结论
论文通过系统地探讨健康声学领域的音频增强策略,揭示了循环时间移位和时间拉伸组合在增强模型泛化能力方面的潜力。这些研究结果表明,适当的增强策略组合可以显著提升对比学习在健康相关声学信号上的表现。然而,作者也指出了一些限制,如实验只在Slowfast NFNet架构上进行,未来研究可以尝试其他架构和增强策略。
七、限制与未来工作
研究保留了测试集,以便进行持续的模型开发,这意味着实验结果可能具有一定的乐观性。此外,研究仅在Slowfast NFNet架构上进行了分析,未来可以在不同的架构和增强策略上进一步验证结果。作者还建议在训练过程中引入健康信号类型标签,可能进一步提高学习到的表示的质量。