论文MedImageInsight: An Open-Source Embedding Model for General Domain Medical Imaging(《MedImageInsight: 通用领域医学影像的开源嵌入模型》)介绍了一个新的开源医学影像嵌入模型——MedImageInsight。此模型由微软健康与生命科学团队开发,旨在解决医学影像领域内数据量迅速增长与专业劳动力相对缓慢增加之间的矛盾。MedImageInsight模型在多个医学影像领域中进行了训练和评估,包括X光片、CT、MRI、皮肤镜、光学相干断层扫描(OCT)、视网膜摄影、超声、病理学以及乳腺X光片等。论文详细描述了模型的架构、训练过程以及在各种医学影像任务中的表现。
论文作者为Noel C. F. Codella, Ying Jin, Shrey Jain, Yu Gu, Ho Hin Lee, Asma Ben Abacha, Alberto Santamaria-Pang, Will Guyman, Naiteek Sangani, Sheng Zhang, Hoifung Poon, Stephanie Hyland, Shruthi Bannur, Javier Alvarez-Valle, Xue Li, John Garrett, Alan McMillan, Gaurav Rajguru, Madhu Maddi, Nilesh Vijayrania, Rehaan Bhimai, Nick Mecklenburg, Rupal Jain, Daniel Holstein, Naveen Gaur, Vijay Aski, Jenq-Neng Hwang, Thomas Lin, Ivan Tarapov, Matthew Lungren和Mu Wei,来自微软,University of Wisconsin-Madison和University of Washington。
以下是论文的内容概要说明:
1. 研究背景与动机
论文首先介绍了全球医学影像领域的挑战,特别是数据量的快速增长和专业人员数量增长的失衡。随着每年医学影像数据量以6%的速度增长,而专业从业人员数量仅以0.7%的速度增长,导致临床诊断工作负担增加。通过将AI和机器学习集成到影像处理工作流中,可以显著提高诊断的准确性、自动化处理流程并支持临床决策。因此,开发一种通用的影像嵌入模型以适应多种医学影像领域,成为应对这一问题的关键。
基础模型在医学领域的应用
随着大模型(Foundation Models)在NLP等领域取得成功,这种模型逐渐应用于医疗领域,尤其是在影像处理方面。论文提到一些基础模型,如GPT-4在医疗考试(USMLE)等多任务上的表现卓越,显示了其跨领域的适应能力。因此,研究人员希望通过类似的基础模型,创建一种可适应多个医学影像领域的通用模型,减少开发单独模型的成本和复杂度。
2. MedImageInsight模型的架构与技术特点
MedImageInsight是一个轻量级、开源的通用医学影像嵌入模型,专为不同类型的医学影像数据设计。模型架构上借鉴了双塔结构(Two-Tower Architecture),其中一个塔是图像编码器,另一个塔是文本编码器,二者通过对比学习的方式进行训练。
2.1. 模型参数
模型的图像编码器和文本编码器参数分别为0.36B和0.25B。与现有的大型模型(如GPT-4、Med-PaLM等)相比,MedImageInsight模型的参数量较小,但在多领域医学任务上展现出强大的性能。这得益于其创新的架构设计和高效的预训练策略。
2.2. 数据注释形式
模型在预训练时,支持两种主要的图像注释形式:图像-文本对和图像-标签对。这种设计能够覆盖医学影像领域中常见的注释类型,适应不同的数据集需求。例如,模型既可以通过图像和标签进行分类任务,也可以通过图像-文本对进行图像检索任务。
2.3. 模型优势
- 高效扩展:MedImageInsight可以在14个不同医学影像领域中高效扩展,而无需为每个领域单独进行微调。部分领域仅使用100张图像就能进行有效训练。
- 透明的决策过程:模型支持生成ROC曲线,用于分类决策的置信度评估,这对临床应用中调节灵敏度和特异性极为重要。同时,模型能够通过图像-图像检索提供分类预测的直接证据,使得决策过程更加透明。
3. 模型性能与评估
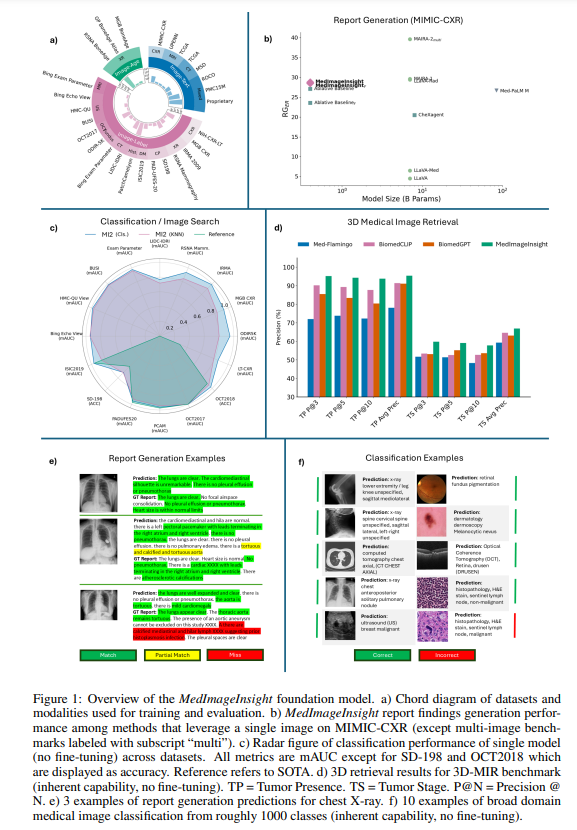
MedImageInsight在多个公开数据集上的性能经过严格评估,涵盖了不同类型的医学影像领域,如X光、CT、MRI、皮肤病学、眼科等。在多个任务上,模型都展现了优异的性能。
3.1. 公共数据集的分类与检索任务
论文详细描述了MedImageInsight在分类、图像-图像检索以及3D医学图像检索任务中的表现。例如,在胸部X光数据集的疾病分类和检索任务中,模型达到了SOTA(最新技术水平),并且在骨龄估算任务中达到了人类专家水平。尤其是在3D医学图像检索中,模型在肝、肺、胰腺和结肠的肿瘤检测任务上表现出色,精确度明显超过其他模型。
3.2. 任务微调实验
模型在多领域医学任务中无需微调即可达到SOTA表现,但为了评估其在特定任务上的适应能力,研究团队进行了微调实验。论文展示了MedImageInsight在ChestX-ray14数据集上的微调结果,特别是在水肿、肺实变、胸腔积液等三种临床重要条件下的表现。实验表明,模型微调后能够在多个领域的任务上与其他SOTA模型(如CXR Foundation和ELIXR)表现相当。
4. 报告生成能力
MedImageInsight模型还支持医学报告生成。在报告生成任务中,模型与一个轻量级的文本解码器(仅0.07B参数)结合,能够以较低的计算成本生成接近SOTA的单张图像报告。与大型模型(如GPT-4o和GPT-4o-mini)相比,MedImageInsight在报告生成的临床效能指标上表现更为优异,但在词汇指标(如BLEU和ROUGE)上略逊。
5. 模型的公平性与透明性
论文特别强调了MedImageInsight模型在AI公平性上的优势。通过独立的临床评估,模型在性别和年龄上的分类表现差异较小,展示了模型的公平性。尤其是在胸部X光图像的分类任务中,MedImageInsight在女性和男性的mAUC差异仅为0.3点,这表明该模型在不同性别群体中的表现较为一致。
6. 3D医学图像检索
MedImageInsight还在3D医学图像检索任务中展示了卓越的能力。在3D-MIR基准测试中,模型在肝脏、肺部、胰腺和结肠的肿瘤存在检测任务上超过了其他主流模型(如BiomedCLIP和Med-Flamingo)。在肿瘤分期的精度和召回率上,MedImageInsight也显著优于其他模型。
7. 训练方法与数据
论文还详细描述了模型的预训练过程。MedImageInsight模型基于Florence计算机视觉基础模型开发,采用了DaViT架构作为图像编码器,并使用了UniCL作为目标函数。训练过程中,模型使用了大规模的医学影像数据,包括来自MIMIC-CXR、NIH-CXR、RSNA骨龄、ISIC2019、OCT2017等多个公开数据集,总计使用了超过370万张图像数据。
训练的技术细节
- 训练过程中使用了AdamW优化器,学习率为1E-5,权重衰减为0.2,批次大小为1024。
- 数据增强方面,采用了随机缩放、随机裁剪、随机擦除等常见的图像处理技术。
碳足迹
模型预训练耗费了7680小时的V100 GPU计算,总排放量为0.89184 tCO2eq,计算资源由Azure机器学习平台提供。
8. 结论
论文最后总结了MedImageInsight的创新之处,强调了该模型在多领域医学影像任务中的通用性、透明性和高效性。模型的开源有助于推动医学影像AI研究的发展,并希望通过该模型的广泛应用,改善全球医疗保健系统中的AI透明性和公平性。