论文《ExPLoRA: Parameter-Efficient Extended Pre-Training to Adapt Vision Transformers under Domain Shifts》详细介绍了ExPLoRA技术,该技术为视觉Transformer(ViT)在面对领域转移(Domain Shifts)时的高效适应提供了一种创新的解决方案。ExPLoRA的核心理念是,通过扩展预训练阶段并使用参数高效的调优方法(如LoRA),在不完全解冻模型的情况下,继续在新的目标领域进行自监督学习,从而在多个领域的迁移学习任务中实现优异表现。
论文作者为Samar Khanna, Medhanie Irgau, David B. Lobell和Stefano Ermon,均来自Stanford University。
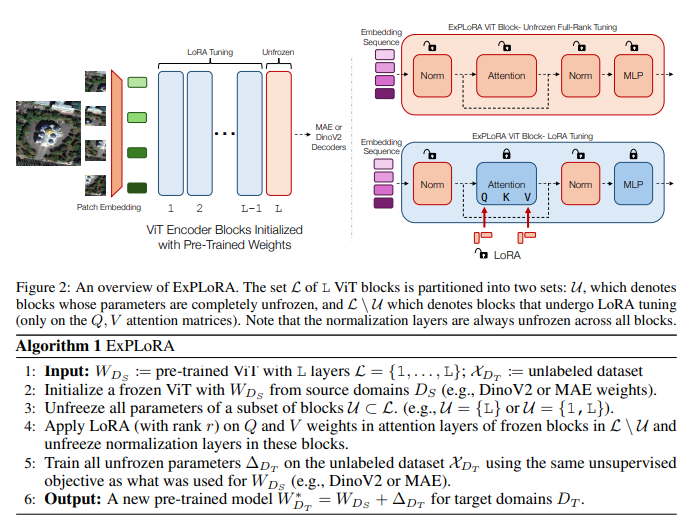
视觉基础模型(VFMs)如MAE(Masked Autoencoder)和DinoV2等,被广泛应用于自然图像的大规模数据集上,它们在下游任务中表现优异。然而,这些模型在被迁移到与自然图像差异较大的领域(如卫星图像、医学图像等)时,表现往往不如针对这些特定领域进行预训练的模型。为此,传统的方法需要对这些新领域进行全量预训练,但这种方法需要大量的计算资源和时间成本。ExPLoRA提出了一种高效的替代方案,利用已经在自然图像领域预训练好的模型,并通过自监督学习扩展到新领域,同时只需调优极少量的模型参数,显著降低计算开销。
虽然参数高效的微调方法(PEFT)如LoRA(Low-Rank Adaptation)能够通过仅调优少量模型参数将预训练好的模型适应下游任务,但目前针对如何在没有监督标签的情况下扩展预训练阶段仍缺乏研究。论文提出的关键问题是:是否可以通过高效的自监督预训练方法,将已经在自然图像领域预训练好的模型适应到新领域?
ExPLoRA方法概述:
ExPLoRA是一种新颖的参数高效的扩展预训练方法,专门用于应对ViT在领域转移下的适应性问题。其流程可以分为几个关键步骤:
- 模型初始化:
- 首先,使用在自然图像数据集(如MAE或DinoV2)上预训练好的ViT模型作为基础模型。这些模型已经包含了对自然图像领域丰富的语义信息。
- 然后,选择性解冻ViT的1-2个预训练模块,并将其余部分通过LoRA进行微调。
- 自监督预训练:
- ExPLoRA在新的目标领域上进行自监督的预训练,不依赖标签。具体来说,模型使用与初始预训练相同的自监督目标(例如MAE的掩码自编码器或DinoV2的学生-教师模型),但应用于新的领域数据。
- 在这个阶段,只有1-2个Transformer模块被完全解冻,其他模块的参数通过LoRA进行更新。LoRA通过低秩矩阵分解,仅对注意力层中的查询矩阵(Q)和键值矩阵(V)进行调整,显著减少了需要更新的参数数量。
- 有监督微调:
- 在完成自监督预训练后,ExPLoRA在新领域的数据集上进行有监督微调。此时只需要通过LoRA微调极少量的模型参数,即可达到甚至超过现有的最先进方法的性能。
- LoRA的核心原理:
- LoRA假设在将一个自监督预训练模型调整到下游任务时,所需的权重更新可以表示为一个低秩子空间的变化: ΔW=BA\Delta W = BAΔW=BA 其中,B和A是两个低秩矩阵,通过这两个矩阵的乘积来表示所需的权重更新。这种低秩分解可以显著减少需要调优的参数数量。
- 在ExPLoRA中,LoRA只应用于Q和V矩阵,而模型的其余部分保持冻结,进一步降低了计算开销。
主要贡献:
- 提出ExPLoRA方法:ExPLoRA是一个参数高效的扩展预训练方法,能够通过自监督学习,将视觉基础模型扩展到新的目标领域,且仅需调优少量的参数。
- 实验证明其有效性:在多个数据集上的实验结果表明,ExPLoRA在卫星图像等领域上实现了最先进的性能。在fMoW-RGB数据集上,ExPLoRA的线性探测准确率提高了8%,并且在使用不到原模型10%的参数的情况下,性能优于完全预训练的模型。
- 消融实验和分析:通过消融实验,验证了ExPLoRA在不同ViT模块解冻策略、LoRA秩选择等方面的优越性。实验表明,解冻适量的Transformer模块,并通过LoRA调优其余模块,可以在保持参数效率的同时获得更好的迁移性能。
详细实验结果:
ExPLoRA在多个视觉领域的数据集上进行了实验,包括RGB和多光谱的卫星图像、医学影像以及野生动物图像等。实验结果表明,ExPLoRA不仅在这些任务中优于其他最先进的模型,而且在计算资源和参数使用方面更加高效。特别是在fMoW-RGB数据集上,ExPLoRA实现了79.15%的Top-1准确率,比使用完整模型的最先进方法还高,并且仅调优了6%的模型参数。
实验案例:卫星图像
- 数据集:Functional Map of the World (fMoW) 数据集,包括高分辨率的卫星图像及其对应的分类标签。
- ExPLoRA在该数据集上的表现优于之前所有完全预训练的方法。例如,DinoV2+ExPLoRA模型达到了79.15%的Top-1准确率,相比完全预训练的SatMAE等方法具有显著提升。
- 在线性探测任务中,ExPLoRA比现有最先进方法提升了8.2%的准确率,进一步验证了该方法在特征提取和迁移学习中的优势。
消融研究:
论文还进行了详细的消融研究,探索了不同模块的解冻策略、LoRA秩的选择对模型性能的影响。实验结果表明,仅解冻最后1-2个Transformer模块,并使用LoRA对其他模块进行低秩调优,可以在参数效率和模型性能之间取得最佳平衡。
应用领域:
ExPLoRA不仅限于卫星图像,还可以扩展到其他需要迁移学习的视觉领域。论文中还测试了医疗影像、农业影像、野生动物监控等领域的数据集,结果表明,ExPLoRA具有广泛的适用性,能够有效地适应不同领域的视觉任务。
总结与展望:
ExPLoRA提出了一种新的、高效的扩展预训练方法,能够有效地适应视觉Transformer模型在不同领域中的迁移学习需求。通过参数高效的自监督学习和微调技术,ExPLoRA不仅大幅度降低了计算成本,还在多个领域中超过了现有的最先进模型。未来,ExPLoRA可能进一步应用于自然语言处理和其他领域,以解决大规模预训练模型在不同领域中的适应性问题。这一技术为计算资源有限的研究人员提供了新的思路,能够帮助他们在不进行全量预训练的情况下,将现有的视觉基础模型高效应用于新的视觉领域。这不仅降低了环境成本,也极大地拓展了基础模型的应用场景。