论文The Perfect Blend: Redefining RLHF with Mixture of Judges主要讨论了如何通过一种新的后训练范式,称为约束生成策略优化(Constrained Generative Policy Optimization,CGPO),重新定义了基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),特别是在多任务学习(MTL)中的应用。
该论文指出,传统的RLHF方法在多任务学习中存在一些挑战,包括奖励黑客(reward hacking)和极端的多目标优化。为了应对这些挑战,作者提出了混合评审(Mixture of Judges,MoJ)的概念,通过成本效益的约束策略优化和分层机制,在多任务RLHF中找到平衡点。CGPO方法能够检测并减轻奖励黑客行为,同时在多个目标之间达到帕累托最优,最终为RLHF提供了更全面和精确的对齐手段。
论文作者为Tengyu Xu, Eryk Helenowski, Karthik Abinav Sankararaman, Di Jin, Kaiyan Peng, Eric Han, Shaoliang Nie, Chen Zhu, Hejia Zhang, Wenxuan Zhou, Zhouhao Zeng, Yun He, Karishma Mandyam, Arya Talabzadeh, Madian Khabsa, Gabriel Cohen, Yuandong Tian, Hao Ma, Sinong Wang和Han Fang,均来自Meta(Meta GenAI, FAIR)。
一些为论文概要内容:
1. 研究背景
大语言模型(LLMs)已经展示了在多种任务中的优越表现,这得益于其大规模参数化和多任务学习(MTL)的能力。然而,传统的RLHF方法在多任务场景中面临两大主要问题:
- 奖励黑客问题:由于奖励模型并不能完美反映人类的真实偏好,模型可能会优化出不符合人类期望的结果,造成“奖励黑客”现象,即模型通过最大化奖励函数的缺陷,而不是优化人类的真实目标。
- 多目标优化的难题:多任务学习常常需要在多个有时互相矛盾的目标之间进行平衡。传统RLHF方法通常通过线性组合多个奖励模型来处理多任务问题,这种方法需要对每个任务的权重进行细致的调整,难以通用且容易导致某些任务的性能退化。
2. CGPO方法的核心创新
为了解决上述问题,论文提出了一种新的后训练范式,即约束生成策略优化(CGPO),其主要创新点如下:
2.1 混合评审机制(MoJ)
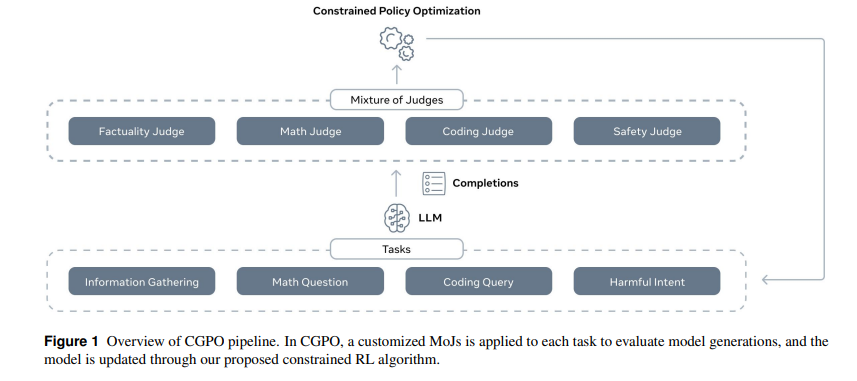
论文的核心之一是引入了“混合评审”(Mixture of Judges, MoJ),这是一种由多种评审器组成的模块,用于识别和应对奖励黑客问题。MoJ可以包括基于规则的评审器和基于大语言模型的评审器。基于规则的评审器可以通过特定规则(如数学问题的答案准确性或代码执行结果)评估生成的文本是否符合要求;而基于LLM的评审器则能够处理更复杂的任务,如判断生成内容的事实性、判断生成内容是否违反安全约束等。
2.2 约束生成策略优化(CGPO)
CGPO通过约束生成策略优化方法,将多任务RLHF中的奖励黑客问题最小化。该方法不仅优化奖励模型分数,还通过约束条件保证生成结果的有效性。例如,在数学问题中,CGPO要求生成答案必须正确,而不仅仅是奖励模型打分高。
为了实现这一点,论文引入了多个约束RLHF优化器:
- 校准正则化策略梯度(CRPG):在传统的RLHF优化中,奖励模型的输出可能存在校准问题,导致不同提示(prompt)的生成结果分数不能直接比较。CRPG通过引入校准奖励机制来解决这一问题,保证不同提示之间的奖励分数是可比较的。
- 约束在线直接偏好优化(CODPO):CODPO基于直接偏好优化(DPO)方法,在线优化策略,通过对每个任务独立优化,避免了传统RLHF中任务间的相互干扰。
- 校准正则化奖励排名微调(CRRAFT):CRRAFT结合了奖励排名算法,通过约束优化每次生成结果的概率,确保模型生成高质量的响应。
2.3 多任务优化中的细粒度管理
论文中特别强调了在多任务学习场景下,不能一刀切地应用同一个奖励模型或优化策略。相反,CGPO根据不同任务定制了特定的奖励模型、评审机制和优化器设置。具体来说,每个任务都有自己的优化策略,避免了不同任务目标之间的冲突。例如,在生成聊天回复的任务中,可能更关注生成内容的帮助性和事实性;而在编程任务中,则重点在于代码的正确性和运行结果。
3. 实验结果
在实验部分,CGPO通过多种基准任务(包括对话生成、数学推理、编程、知识问答等)的评估,证明了其在多个任务中优于现有的RLHF算法如PPO和DPO。例如:
- 在AlpacaEval-2(对话生成任务)中,CGPO相对于PPO提升了7.4%,相对于DPO提升了12.5%。
- 在HumanEval(编程任务)中,CGPO相较于PPO提升了5%。
- 在MATH(数学推理任务)中,CGPO在保持代码准确性的同时,避免了PPO常见的奖励黑客问题。
这些结果表明,CGPO方法在应对奖励黑客问题和多目标优化上具有显著优势。此外,CGPO的混合评审机制可以针对性地优化每个任务,避免了传统RLHF在多任务优化中遇到的瓶颈。
4. 结论与贡献
CGPO为RLHF领域带来了多项突破:
- 多任务学习中的新范式:CGPO通过细粒度的任务管理,解决了传统RLHF在多任务环境中的性能下降问题。
- 奖励黑客的有效控制:通过混合评审机制,CGPO在奖励黑客现象的防控上表现出色,能够在多个任务中找到帕累托最优解。
- 无须大量超参数调整的优化器:CRPG、CODPO和CRRAFT等新型优化器具有很好的可扩展性,适合大规模语言模型的后训练任务,且不需要大量的超参数调整。